本文首发于:行者AI
强化学习 (reinforcement learning) 是机器学习和人工智能里的一类问题,研究如何通过一系列的顺序决策来达成一个特定目标。它是一类算法, 是让计算机实现从一开始什么都不懂,脑袋里没有一点想法,,通过不断地尝试, 从错误中学习, 最后找到规律, 学会了达到目的的方法。 这就是一个完整的强化学习过程。这里我们可以引用下方图做一个更直观形象的解释。
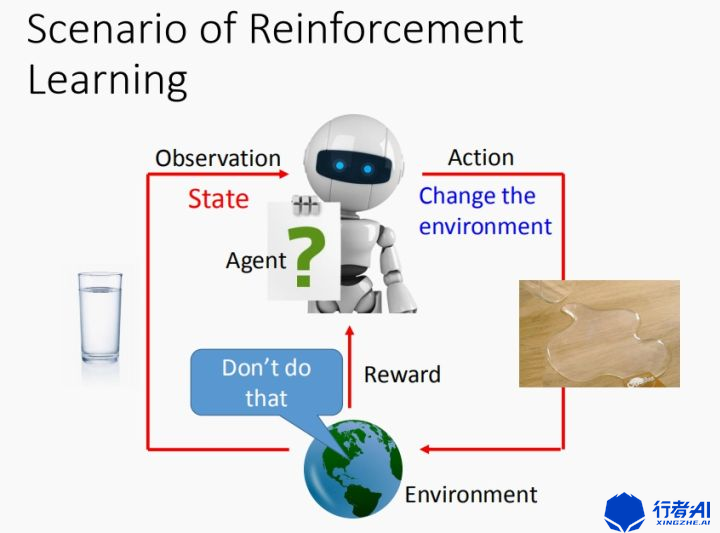
Agent为智能体,也就是我们的算法,在游戏当中以玩家的形式出现。智能体通过一系列策略,输出一个行为(Action)从而作用到环境(Environment),而环境则返回作用后的状态值也就是图中的观察(Observation)和奖励值(Reward)。当环境返回奖励值给智能体之后,更新自身所在的状态,而智能体获取到新的Observation。
1. ml-agents
1.1 介绍
目前游戏大部分Unity游戏数量庞大,引擎完善,训练环境好搭建。由于Unity 可以跨平台,可以在Windows、Linux平台下训练后再转成WebGL发布到网页上。而mlagents是Unity的一款开源插件,能让开发者在Unity的环境下进行训练,甚至不用去编写python端的代码,不用深入理解PPO,SAC等算法。只要开发者配置好参数,就可以很轻松的使用强化学习的算法来训练自己的模型。
1.2 Anaconda、tensorflow及tensorboard安装
本文介绍的ml-agents需要通过Python与Tensorflow通信,训练时从ml-agents的Unity端拿到Observation、Action、Reward、Done等信息传入Tensorflow进行训练,然后将模型的决策传入Unity。因此在安装ml-agents前,需要根据如下链接进行tensorflow的安装。
Tensorboard方便数据可视化,方便分析模型是否达到预期。
1.3 ml-agents安装步骤
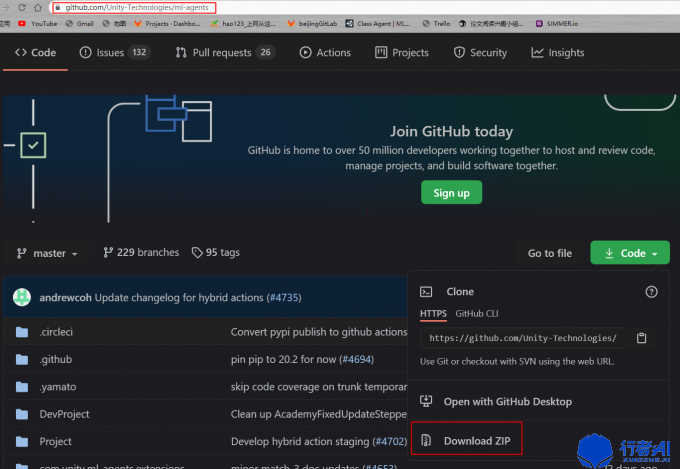
(1) 前往github下载ml-agents (本实例采用release6版本)
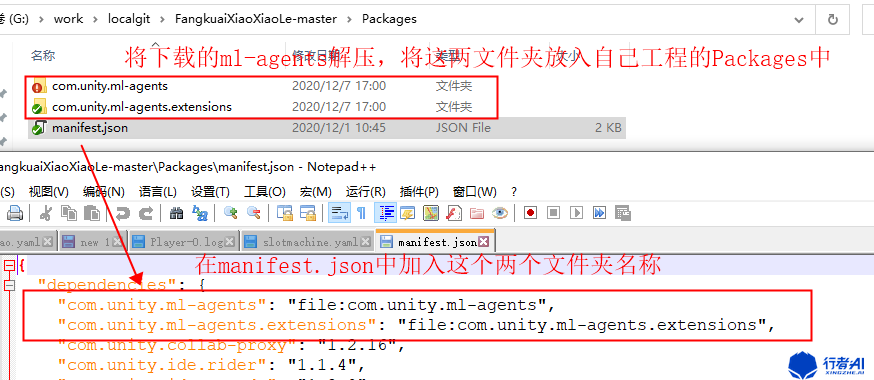
(2) 将压缩包解压,把com.unity.ml-agents,com.unity.ml-agents.extensions 放入Unity的Packages目录下(如果没有请创建一个),将manifest.json中加入此两个目录。
(3) 安装完成后,到工程中就导入后,建立个新脚本,输入以下引用以验证安装成功
using Unity.MLAgents;
using Unity.MLAgents.Sensors;
using Unity.MLAgents.Policies;
public class MyAgent : Agent
{
}
2. ml-agents训练实例
2.1 概要及工程
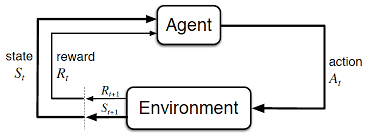
Environment 通常利用马尔可夫过程来描述,agent 通过采取某种 policy 来产生Action,和 Environment 交互,产生一个 Reward。之后 agent 根据 Reward 来调整优化当前的 policy。
本例实际工程参考消消乐规则,凑齐三个同样的颜色即可得分,本实例去除了四个连色及多连的额外奖励(以方便设计环境)

工程实例下载处 点击前往
Unity工程导出部分请参考官方 点击前往 。
下面将从四个角度来分享项目项目实践的方法,接口抽离、选算法、设计环境、参数调整。
2.2 游戏框架AI接口抽离
将工程的Observation、Action需要的接口从游戏中抽离出来。用于传入游戏当前的状态和执行游戏的动作。
static List<ML_Unit> states = new List<ML_Unit>();
public class ML_Unit
{
public int color = (int)CodeColor.ColorType.MaxNum;
public int widthIndex = -1;
public int heightIndex = -1;
}
//从当前画面中,拿到所有方块的信息,包含所在位置x(长度),位置y(高度),颜色(坐标轴零点在左上)
public static List<ML_Unit> GetStates()
{
states.Clear();
var xx = GameMgr.Instance.GetGameStates();
for(int i = 0; i < num_widthMax;i++)
{
for(int j = 0; j < num_heightMax; j++)
{
ML_Unit tempUnit = new ML_Unit();
try
{
tempUnit.color = (int)xx[i, j].getColorComponent.getColor;
}
catch
{
Debug.LogError($"GetStates i:{i} j:{j}");
}
tempUnit.widthIndex = xx[i, j].X;
tempUnit.heightIndex = xx[i, j].Y;
states.Add(tempUnit);
}
}
return states;
}
public enum MoveDir
{
up,
right,
down,
left,
}
public static bool CheckMoveValid(int widthIndex, int heigtIndex, int dir)
{
var valid = true;
if (widthIndex == 0 && dir == (int)MoveDir.left)
{
valid = false;
}
if (widthIndex == num_widthMax - 1 && dir == (int)MoveDir.right)
{
valid = false;
}
if (heigtIndex == 0 && dir == (int)MoveDir.up)
{
valid = false;
}
if (heigtIndex == num_heightMax - 1 && dir == (int)MoveDir.down)
{
valid = false;
}
return valid;
}
//执行动作的接口,根据位置信息和移动方向,调用游戏逻辑移动方块。widthIndex 0-13,heigtIndex 0-6,dir 0-3 0上 1右 2下 3左
public static void SetAction(int widthIndex,int heigtIndex,int dir,bool immediately)
{
if (CheckMoveValid(widthIndex, heigtIndex, dir))
{
GameMgr.Instance.ExcuteAction(widthIndex, heigtIndex, dir, immediately);
}
}
2.3 游戏AI算法选择
走入强化学习项目的第一个课题,面对众多算法,选择一个合适的算法能事半功倍。如果对算法的特性还不太熟悉,可以直接使用ml-agents自带的PPO和SAC。
本例笔者最开始使用的PPO算法,尝试了比较多的调整,平均9步才能走对一步,效果比较糟糕。
后来仔细分析游戏的环境,由于此工程的三消类的游戏,每次的环境都完全不一样,每一步的结果对下一步产生的影响并没有多大关系,对马尔科夫链的需求不强。由于PPO是OnPolicy的policy-based的算法,每次更新的策略更新非常小心,导致结果很难收敛(笔者尝试了XX布,依然没有收敛)。
相比DQN是OffPolicy的value-base算法,可以收集大量环境的参数建立Qtable,逐步找到对应的环境的最大值。
简单地说,PPO是在线学习,每次自己跑几百步后,回过头来学习这几百步哪里做得对,哪里做的不对,然后更新学习后,再跑几百步,如此反复。这样学习效率慢不说,还很难找到全局最优的解。
而DQN是离线学习,可以跑上亿步,然后回去把这些跑过的地方都拿出来学习,然后很容易找到全局最优的点。
(本例使用PPO做演示,后续分享在ml-agents外接算法,使用外部工具stable_baselines3,采用DQN的算法来训练)
2.4 游戏AI设计环境
当我们确定了算法框架之后,如何设计Observation、Action及Reward,便成了决定训练效果的决定性因素。在这个游戏中,环境的这里的环境主要有两个变量,一个是方块的位置,另一个是方块的颜色。
--Observation:
针对如果上图,我们的本例长14、宽7、颜色有6种。
ml-agents使用的swish作为激活函数,可以使用不太大的浮点数(-10f ~10f),但是为了让agents获得环境更纯净,训练效果更理想,我们还是需要对环境进行编码。
本例笔者使用Onehot的方式进行环境编码,左上角定位坐标零点。如此下来,左上角的青色方块的环境编码就可以表示为 长[0,0,0,0,0,0,0,0,0,0,0,0,0,1],
高[0,0,0,0,0,0,1],颜色按固定枚举来处理( 黄,绿,紫,粉,蓝,红)颜色[0,0,0,0,1,0]。
环境总共包含 (14+7+6)14 * 7 = 2646
代码示例:
public class MyAgent : Agent
{
static List<ML_Unit> states = new List<ML_Unit>();
public class ML_Unit
{
public int color = (int)CodeColor.ColorType.MaxNum;
public int widthIndex = -1;
public int heightIndex = -1;
}
public static List<ML_Unit> GetStates()
{
states.Clear();
var xx = GameMgr.Instance.GetGameStates();
for(int i = 0; i < num_widthMax;i++)
{
for(int j = 0; j < num_heightMax; j++)
{
ML_Unit tempUnit = new ML_Unit();
try
{
tempUnit.color = (int)xx[i, j].getColorComponent.getColor;
}
catch
{
Debug.LogError($"GetStates i:{i} j:{j}");
}
tempUnit.widthIndex = xx[i, j].X;
tempUnit.heightIndex = xx[i, j].Y;
states.Add(tempUnit);
}
}
return states;
}
List<ML_Unit> curStates = new List<ML_Unit>();
public override void CollectObservations(VectorSensor sensor)
{
//需要判断是否方块移动结束,以及方块结算结束
var receiveReward = GameMgr.Instance.CanGetState();
var codeMoveOver = GameMgr.Instance.IsCodeMoveOver();
if (!codeMoveOver || !receiveReward)
{
return;
}
//获得环境的状态信息
curStates = MlagentsMgr.GetStates();
for (int i = 0; i < curStates.Count; i++)
{
sensor.AddOneHotObservation(curStates[i].widthIndex, MlagentsMgr.num_widthMax);
sensor.AddOneHotObservation(curStates[i].heightIndex, MlagentsMgr.num_heightMax);
sensor.AddOneHotObservation(curStates[i].color, (int)CodeColor.ColorType.MaxNum);
}
}
}
--Action:
每个方块可以上下左右移动,我们需要记录的最小信息包含,14*7个方块,以及每个方块可以移动4个方向,本例方向枚举(上,右,下,左)。
左上为零点,左上角的青色方块占据了Action的前四个动作,分别是(左上角的青色方块向上移动,左上角的青色方块向右移动,左上角的青色方块向下移动,
左上角的青色方块向左移动)。
那么动作总共包含 14 * 7 * 4 = 392
细心的读者可能会发现 左上角的青色方块 并不能往上和往左移动,这时我们需要设置Actionmask,来屏蔽掉这些在规则上禁止的动作。
代码示例:
public class MyAgent : Agent
{
public enum MoveDir
{
up,
right,
down,
left,
}
public void DecomposeAction(int actionId,out int width,out int height,out int dir)
{
width = actionId / (num_heightMax * num_dirMax);
height = actionId % (num_heightMax * num_dirMax) / num_dirMax;
dir = actionId % (num_heightMax * num_dirMax) % num_dirMax;
}
//执行动作,并获得该动作的奖励
public override void OnActionReceived(float[] vectorAction)
{
//需要判断是否方块移动结束,以及方块结算结束
var receiveReward = GameMgr.Instance.CanGetState();
var codeMoveOver = GameMgr.Instance.IsCodeMoveOver();
if (!codeMoveOver || !receiveReward)
{
Debug.LogError($"OnActionReceived CanGetState = {GameMgr.Instance.CanGetState()}");
return;
}
if (invalidNums.Contains((int)vectorAction[0]))
{
//方块结算的调用,这里可以获得奖励(这里是惩罚,因为这是在屏蔽动作内,训练的时候会调用所有的动作,在非训练的时候则不会进此逻辑)
GameMgr.Instance.OnGirdChangeOver?.Invoke(true, -5, false, false);
}
DecomposeAction((int)vectorAction[0], out int widthIndex, out int heightIndex, out int dirIndex);
//这里回去执行动作,移动对应的方块,朝对应的方向。执行完毕后会获得奖励,并根据情况重置场景
MlagentsMgr.SetAction(widthIndex, heightIndex, dirIndex, false);
}
//MlagentsMgr.SetAction调用后,执行完动作,会进入这个函数
public void RewardShape(int score)
{
//计算获得的奖励
var reward = (float)score * rewardScaler;
AddReward(reward);
//将数据加入tensorboard进行统计分析
Mlstatistics.AddCumulativeReward(StatisticsType.action, reward);
//每一步包含惩罚的动作,可以提升探索的效率
var punish = -1f / MaxStep * punishScaler;
AddReward(punish);
//将数据加入tensorboard进行统计分析
Mlstatistics.AddCumulativeReward( StatisticsType.punishment, punish);
}
//设置屏蔽动作actionmask
public override void CollectDiscreteActionMasks(DiscreteActionMasker actionMasker)
{
// Mask the necessary actions if selected by the user.
checkinfo.Clear();
invalidNums.Clear();
int invalidNumber = -1;
for (int i = 0; i < MlagentsMgr.num_widthMax;i++)
{
for (int j = 0; j < MlagentsMgr.num_heightMax; j++)
{
if (i == 0)
{
invalidNumber = i * (num_widthMax + num_heightMax) + j * num_heightMax + (int)MoveDir.left;
actionMasker.SetMask(0, new[] { invalidNumber });
}
if (i == num_widthMax - 1)
{
invalidNumber = i * (num_widthMax + num_heightMax) + j * num_heightMax + (int)MoveDir.right;
actionMasker.SetMask(0, new[] { invalidNumber });
}
if (j == 0)
{
invalidNumber = i * (num_widthMax + num_heightMax) + j * num_heightMax + (int)MoveDir.up;
actionMasker.SetMask(0, new[] { invalidNumber });
}
if (j == num_heightMax - 1)
{
invalidNumber = i * (num_widthMax + num_heightMax) + j * num_heightMax + (int)MoveDir.down;
actionMasker.SetMask(0, new[] { invalidNumber });
}
}
}
}
}
原工程消除过程中使用大量协程,有很高的延迟,我们需要再训练时把延迟的时间挤出来。
为了不影响游戏的主逻辑,一般情况下把协程里面的yield return new WaitForSeconds(fillTime)中的fillTime改成0.001f,这样可以在不大量修改游戏逻辑的情况下,在模型选择Action后能最快得到Reward。
public class MyAgent : Agent
{
private void FixedUpdate()
{
var codeMoveOver = GameMgr.Instance.IsCodeMoveOver();
var receiveReward = GameMgr.Instance.CanGetState();
if (!codeMoveOver || !receiveReward /*||!MlagentsMgr.b_isTrain*/)
{
return;
}
//因为有协程需要等待时间,需要等待产生Reward后才去请求决策。所以不能使用ml-agents自带的DecisionRequester
RequestDecision();
}
}
2.5 参数调整
在设计好模型后,我们先初步跑一版本,看看结果跟我们设计的预期有多大的差异。
首先配置yaml文件,用于初始化网络的参数:
behaviors:
SanXiaoAgent:
trainer_type: ppo
hyperparameters:
batch_size: 128
buffer_size: 2048
learning_rate: 0.0005
beta: 0.005
epsilon: 0.2
lambd: 0.9
num_epoch: 3
learning_rate_schedule: linear
network_settings:
normalize: false
hidden_units: 512
num_layers: 2
vis_encode_type: simple
memory: null
reward_signals:
extrinsic:
gamma: 0.99
strength: 1.0
init_path: null
keep_checkpoints: 25
checkpoint_interval: 100000
max_steps: 1000000
time_horizon: 128
summary_freq: 1000
threaded: true
self_play: null
behavioral_cloning: null
framework: tensorflow
训练代码请参照官方提供的接口,本例使用release6版本,命令如下
mlagents-learn config/ppo/sanxiao.yaml --env=G:mylabml-agent-buildprojectssanxiaowindowsdisplay121001displayfangkuaixiaoxiaole --run-id=121001xxl --train --width 800 --height 600 --num-envs 2 --force --initialize-from=121001
训练完成后,打开Anaconda,在ml-agents工程主目录上输入tensorboard --logdir=results --port=6006,复制http://PS20190711FUOV:6006/到浏览器上打开,即可看到训练结果。
(mlagents) PS G:mylabml-agents-release_6> tensorboard --logdir=results --port=6006
TensorBoard 1.14.0 at http://PS20190711FUOV:6006/ (Press CTRL+C to quit)
训练效果图如下:
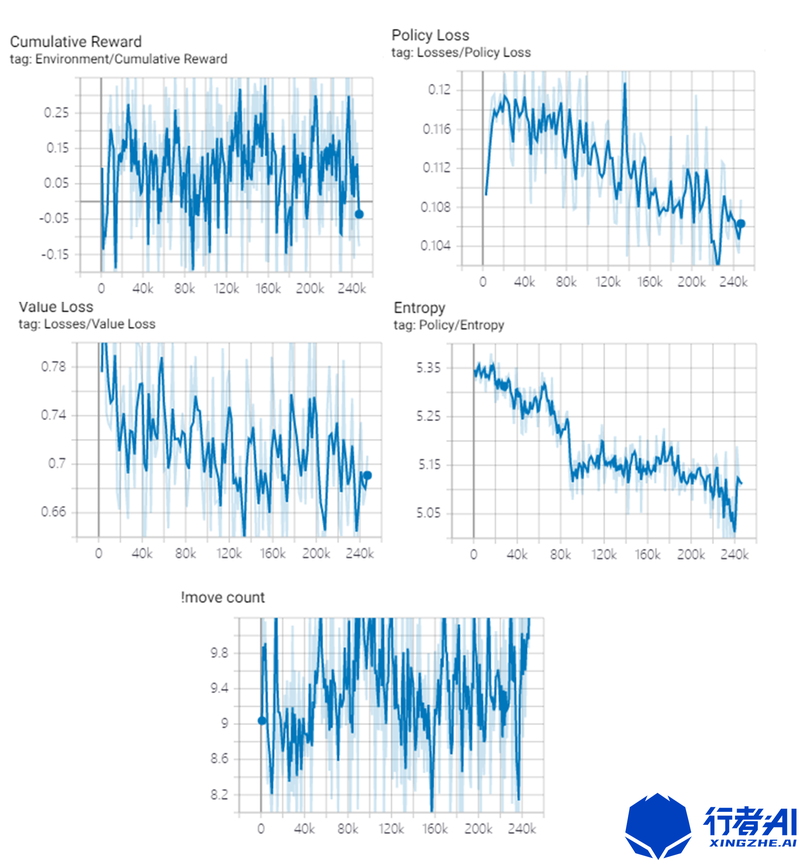
move count 为消掉一次方块,需要走的平均步数,大概需要9布才能走正确一步。在使用Actionmask情况下,可以在6步左右消除一次方块。
–Reward:
根据上面表格的Reward,查看奖励奖励设计的均值。笔者喜欢控制在0.5到2之间。过大过小可以调整rewardScaler。
//MlagentsMgr.SetAction调用后,执行完动作,会进入这个函数
public void RewardShape(int score)
{
//计算获得的奖励
var reward = (float)score * rewardScaler;
AddReward(reward);
//将数据加入tensorboard进行统计分析
Mlstatistics.AddCumulativeReward(StatisticsType.action, reward);
//每一步包含惩罚的动作,可以提升探索的效率
var punish = -1f / MaxStep * punishScaler;
AddReward(punish);
//将数据加入tensorboard进行统计分析
Mlstatistics.AddCumulativeReward( StatisticsType.punishment, punish);
}
3. 总结及杂谈
目前ml-agents官方做法使用模仿学习,使用专家数据在训练网络。
笔者在此例中尝试PPO,有一定的效果。但PPO目前针对三消训练起来有一定难度的,比较难收敛,很难找到全局最优。
设置环境和Reward需要严谨的测试,否则对结果会产生极大的误差,且难以排查。
强化学习目前算法迭代比较快,如果以上有错误的地方,欢迎指正,大家一起进步。
因篇幅有限,不能把整个项目的代码全放出来,如有兴趣研究的同学,可以在下方留言,我可以完整项目通过邮箱的方式发给大家。
后续将分享在ml-agents外接算法,使用外部工具stable_baselines3,采用DQN的算法来训练。
PS:更多技术干货,快关注【公众号 | xingzhe_ai】,与行者一起讨论吧!