一、解析器(parser)
解析器在reqest.data取值的时候才执行。
对请求的数据进行解析:是针对请求体进行解析的。表示服务器可以解析的数据格式的种类。
from rest_framework.parsers import JSONParser, FormParser, MultiPartParser, FileUploadParser
"""
默认得是 JSONParser FormParser MultiPartParser
"""
class BookView(APIView):
# authentication_classes = [TokenAuth, ]
parser_classes = [FormParser, JSONParser]
def get(self, request):....
1、django的request类源码解析
(1)django中发送请求对比
#如果是urlencoding格式发送的数据,在POST里面有值
Content-Type: application/url-encoding.....
request.body
request.POST
#如果是发送的json格式数据,在POST里面是没有值的,在body里面有值,可通过decode,然后loads取值
Content-Type: application/json.....
request.body
request.POST
(2)关于decode和encode
浏览器发送过来是字节需要先解码 ---> decode 如:s=‘中文‘
如果是在utf8的文件中,该字符串就是utf8编码,如果是在gb2312的文件中,则其编码为gb2312。这种情况下,要进行编码转换,都需要先用 decode方法将其转换成unicode编码,再使用encode方法将其转换成其他编码。通常,在没有指定特定的编码方式时,都是使用的系统默认编码创建的代码文件。 如下:
s.decode(‘utf-8‘).encode(‘utf-8‘)
decode():是解码 --->把字节变成字符串 encode()是编码---->把字符串变成字节
(3)查看django中WSGIRequest解析方法
# 1:导入django的类
from django.core.handlers.wsgi import WSGIRequest
# 2:
class WSGIRequest(http.HttpRequest):
def _get_post(self):
if not hasattr(self, ‘_post‘):
self._load_post_and_files()
return self._post
# 3:self._load_post_and_files()从这里找到django解析的方法
def _load_post_and_files(self):
"""Populate self._post and self._files if the content-type is a form type"""
if self.method != ‘POST‘:
self._post, self._files = QueryDict(encoding=self._encoding), MultiValueDict()
return
if self._read_started and not hasattr(self, ‘_body‘):
self._mark_post_parse_error()
return
if self.content_type == ‘multipart/form-data‘:
if hasattr(self, ‘_body‘):
# Use already read data
data = BytesIO(self._body)
else:
data = self
try:
self._post, self._files = self.parse_file_upload(self.META, data)
except MultiPartParserError:
# An error occurred while parsing POST data. Since when
# formatting the error the request handler might access
# self.POST, set self._post and self._file to prevent
# attempts to parse POST data again.
# Mark that an error occurred. This allows self.__repr__ to
# be explicit about it instead of simply representing an
# empty POST
self._mark_post_parse_error()
raise
elif self.content_type == ‘application/x-www-form-urlencoded‘:
self._post, self._files = QueryDict(self.body, encoding=self._encoding), MultiValueDict()
else:
self._post, self._files = QueryDict(encoding=self._encoding), MultiValueDict()
从if self.content_type == ‘multipart/form-data‘:和 self.content_type == ‘application/x-www-form-urlencoded‘: 可以知道django只解析urlencoded‘和form-data这两种类型。
因此在django中传json数据默认是urlencoded解析到request中:body取到json数据时,取到的数据时字节,需要先decode解码,将字节变成字符串。
request.body.decode("utf8") json.loads(request.body.decode("utf8"))
为了传输json数据每次都要decodeloads,比较麻烦因此才有了解析器解决这个问题。
2、rest-framework的request类源码解析
在rest-framework中 是以利用Request类进行数据解析。
1:找到apiview
class APIView(View):
# The following policies may be set at either globally, or per-view.
renderer_classes = api_settings.DEFAULT_RENDERER_CLASSES
parser_classes = api_settings.DEFAULT_PARSER_CLASSES # 解析器
2:找api_settings没有定义找默认
renderer_classes = api_settings.DEFAULT_RENDERER_CLASSES
3:.
api_settings = APISettings(None, DEFAULTS, IMPORT_STRINGS)
4:DEFAULTS
DEFAULTS = {
# Base API policies # 自带的解析器
‘DEFAULT_PARSER_CLASSES‘: (
‘rest_framework.parsers.JSONParser‘, # 仅处理请求头content-type为application/json的请求体
‘rest_framework.parsers.FormParser‘, # 仅处理请求头content-type为application/x-www-form-urlencoded 的请求体
‘rest_framework.parsers.MultiPartParser‘ # 仅处理请求头content-type为multipart/form-data的请求体
),
注意除了上面三种之外还有一个专门处理文件上传:
from rest_framework.parsers import FileUploadParser
3、局部视图parser
from rest_framework.parsers import JSONParser,FormParser
class PublishViewSet(generics.ListCreateAPIView):
parser_classes = [FormParser,JSONParser]
queryset = Publish.objects.all()
serializer_class = PublshSerializers
def post(self, request, *args, **kwargs):
print("request.data",request.data)
return self.create(request, *args, **kwargs)
4、全局视图parser
REST_FRAMEWORK={
"DEFAULT_AUTHENTICATION_CLASSES":["app01.service.auth.Authentication",],
"DEFAULT_PERMISSION_CLASSES":["app01.service.permissions.SVIPPermission",],
"DEFAULT_THROTTLE_CLASSES":["app01.service.throttles.VisitThrottle",],
"DEFAULT_THROTTLE_RATES":{
"visit_rate":"5/m",
},
"DEFAULT_PARSER_CLASSES":['rest_framework.parsers.FormParser',]
}
二、url路由控制
因为我们使用的是视图集而不是视图,我们可以通过简单地将视图集注册到router类来为我们的API自动生成URL conf。
同样,如果我们需要对API URL有更多的控制,我们可以直接使用常规的基于类的视图,并显式地编写URL conf。
最后,我们将默认登录和注销视图包含在可浏览API中。这是可选的,但如果您的API需要身份验证,并且希望使用可浏览的API,那么这是有用的。
1、全自动路由示例
from django.contrib import admin
from django.urls import path, re_path, include
from rest_framework import routers
from app01 import views
routers = routers.DefaultRouter() # 实例化
routers.register("authors", views.AuthorViewSet) # 注册某一个视图
urlpatterns = [
path('admin/', admin.site.urls),
...
# as_view参数指定什么请求走什么方法
# re_path(r'^authors/$', views.AuthorViewSet.as_view({"get": "list", "post": "create"}), name="author_list"),
# re_path(r'^authors/(?P<pk>d+)/$', views.AuthorViewSet.as_view({
# 'get': 'retrieve',
# 'put': 'update',
# 'patch': 'partial_update',
# 'delete': 'destroy'
# }), name="author_detail"),
# 改写如下:
re_path(r"", include(routers.urls)),
re_path(r'^login/$', views.LoginView.as_view(), name="login"),
]
视图的内容不需要任何变动即生效:



2、DRF路由组件使用
路由传参写的特别多,但是框架将这些也已经封装好了。
修改DRFDemo/urls.py文件如下所示:
from django.urls import path, include from .views import BookView, BookEditView, BookModelViewSet from rest_framework.routers import DefaultRouter router = DefaultRouter() # 路由实例化 # 第一个参数是路由匹配规则,这里的路由是分发下来的,因此可以不做设置;第二个参数是视图 router.register(r"", BookModelViewSet) urlpatterns = [ # path('list', BookView.as_view()), # 查看所有的图书 # 注意url中参数命名方式,2.0之前的写法:'retrieve/(?P<id>d+)' # 2.0之后的写法:<>内声明类型,冒号后面跟着关键字参数 # path('retrieve/<int:id>', BookEditView.as_view()) # 单条数据查看 # path('list', BookModelViewSet.as_view({"get": "list", "post": "create"})), # path('retrieve/<int:id>', BookModelViewSet.as_view({"get": "retrieve", "put": "update", "delete": "destroy"})) ] urlpatterns += router.urls # router.urls是自动生成带参数的路由
但是需要自定制的时候还是需要我们自己用APIView写,当不需要那么多路由的时候,不要用这种路由注册,否则会对外暴露过多的接口,会存在风险。总之,一切按照业务需要去用。
三、分页组件(Pagination)
REST框架支持自定义分页风格,你可以修改每页显示数据集合的最大长度。
分页链接支持以下两种方式提供给用户:
- 分页链接是作为响应内容提供给用户
- 分页链接被包含在响应头中(Content-Range或者Link)
内建风格使用作为响应内容提供给用户。这种风格更容易被使用可浏览API的用户所接受。
如果使用通用视图或者视图集合。系统会自动帮你进行分页。
如果使用的是APIView,你就需要自己调用分页API,确保返回一个分页后的响应。可以将pagination_class设置为None关闭分页功能。
1、设置分页风格
可以通过设置DEFAULT_PAGINATION_CLASS和PAGE_SIZE,设置全局变量。
REST_FRAMEWORK = {
'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.LimitOffsetPagination',
'PAGE_SIZE': 100
}
需要同时设置pagination class和page size。 也可以在单个视图中设置pagination_class属性,但一般你需要使用统一的分页风格。
2、修改分页风格
如果你需要修改分页风格 ,需要重写分页类,并设置你需要修改的属性。
from rest_framework.views import APIView
from rest_framework.response import Response
from app01.serializer import *
from .utils import *
#分页
from rest_framework.pagination import PageNumberPagination
class MyPageNumberPagination(PageNumberPagination):
# 默认每页显示的数据条数
page_size = 2
# 获取URL参数中设置的每页显示数据条数
page_size_query_param = 'size'
# 获取URL参数中传入的页码key
page_query_param = 'page'
# 最大支持的每页显示的数据条数(对这个进行限制127.0.0.1:8000/books/?page=1&size=100)
max_page_size = 3
class BookView(APIView):
# authentication_classes = [TokenAuth, ]
# parser_classes = [FormParser, JSONParser]
pagination_class = MyPageNumberPagination # 在视图中使用pagination_class属性调用该自定义类
def get(self, request):
book_list = Book.objects.all() # queryset
# 实例化分页对象,获取数据库中的分页数据
pnp = MyPageNumberPagination()
books_page = pnp.paginate_queryset(book_list, request, self)
# 序列化对象
bs = BookModelSerializers(books_page, many=True, context={"request": request}) # 序列化结果
# return Response(bs.data)
return bs.get_paginated_response(bs.data) # 生成分页和数据
def post(self, request):.....
(1)设置max_page_size是限制直接在页面访问时最大的数据条数显示

虽然总共有4条数据,页面访问get请求时?page=1&size=100但是依然只能拿到max_page_size限制拿到的3条。
3、根据页码分页——PageNumberPagination
这个分页样式接受请求查询参数中的一个数字页面号。
GET https://api.example.org/accounts/?page=4
响应对象:
HTTP 200 OK
{
"count": 1023
"next": "https://api.example.org/accounts/?page=5",
"previous": "https://api.example.org/accounts/?page=3",
"results": [
…
]
}
继承了APIView的视图,也可以设置pagination_class属性选择PageNumberPagination
class MyPageNumberPagination(PageNumberPagination):
# 默认每页显示的数据条数
page_size = 1
# 获取URL参数中设置的每页显示数据条数
page_size_query_param = 'size'
# 获取URL参数中传入的页码key
page_query_param = 'page'
# 最大支持的每页显示的数据条数(对这个进行限制127.0.0.1:8000/books/?page=1&size=100)
max_page_size = 3
更多配置属性:
- django_paginator_class 使用Django分页类。默认为django.core.paginator.Paginator,适用于大多数情况
- page_size 用来显示每页显示对象的数量,如果设置了就重写PAGE_SIZE设置。
- page_query_param 页面查询参数,一个字符串值,指示用于分页控件的查询参数的名称。
- page_size_query_param 该参数允许客户端根据每个请求设置页面大小。一般默认设置为None.
- max_page_size 只有设置了page_size_query_param参数,该参数才有意义,为客户端请求页面中能够显示的最大数量
- last_page_strings 用于存储使用page_query_param参数请求过的值列表或元组,默认为(‘last’,)
- template 用来在可浏览API中,渲染分页的模板(html)名字,可以重写分页样式,或者设置为None,禁用分页。默认为”rest_framework/pagination/numbers.html”。
4、根据位置和个数分页——LimitOffsetPagination
这种分页样式与查找多个数据库记录时使用的语法类似。客户端包括一个”limit”和一个 “offset”查询参数。该限制表示返回的条目的最大数量,并且与page_size大小相同。偏移量表示查询的起始位置,与完整的未分页项的集合有关。
GET https://api.example.org/accounts/?limit=100&offset=400
HTTP 200 OK
{
"count": 1023
"next": "https://api.example.org/accounts/?limit=100&offset=500",
"previous": "https://api.example.org/accounts/?limit=100&offset=300",
"results": [
…
]
}
这种也可以设置PAGE_SIZE,然后客户端就可以设置limit参数了。
继承了GenericAPIView的子类,可以通过设置pagination_class属性为LimitOffsetPagination使用
class MyLimitOffsetPagination(LimitOffsetPagination):
# 默认每页显示的数据条数
default_limit = 1
# URL中传入的显示数据条数的参数
limit_query_param = 'limit'
# URL中传入的数据位置的参数
offset_query_param = 'offset'
# 最大每页显得条数
max_limit = None
(重写LimitOffsetPagination类)配置:
- default_limit: 如果客户端没有提供,则默认使用与PAGE_SIZE值一样。
- limit_query_param:表示限制查询参数的名字,默认为’limit’
- offset_query_param:表示偏移参数的名字, 默认为’offset’
- max_limit:允许页面中显示的最大数量,默认为None
- template: 渲染分页结果的模板名,默认为”rest_framework/pagination/numbers.html”.
5、游标分页——CursorPagination
基于游标的分页显示了一个不透明的“cursor”指示器,客户端可以使用它来浏览结果集。这种分页方式只允许用户向前或向后进行查询。并且不允许客户端导航到任意位置。
基于游标的分页要求在结果集中有一个惟一的、不变的条目顺序。这个排序通常是记录上的一个创建时间戳,用来表示分页的顺序。
基于游标的分页比其他方案更复杂。它还要求结果集给出一个固定的顺序,并且不允许客户端任意地对结果集进行索引,但是它确实提供了以下好处:
- 提供一致的分页视图。当使用正确的指针分页时,即使在分页过程中其他客户端插入新项时,客户端也不会在分页时看到同一个项两次。
- 支持使用非常大的数据集。大量数据集使用基于off-set的分页方式可能会变得低效或不可用。基于指针的分页模式有固定的时间属性,并且随着数据集的大小的增加而不会减慢。
from rest_framework.pagination import PageNumberPagination, LimitOffsetPagination, CursorPagination
class MyCursorPagination(CursorPagination):
# URL传入的游标参数
cursor_query_param = 'cursor'
# 默认每页显示的数据条数
page_size = 2
# URL传入的每页显示条数的参数
page_size_query_param = 'page_size'
# 每页显示数据最大条数
max_page_size = 1000
# 根据ID从大到小排列
ordering = "id"
6、设置全局配置
REST_FRAMEWORK = {
'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.PageNumberPagination',
# 'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.LimitOffsetPagination',
# 'DEFAULT_PAGINATION_CLASS': 'rest_framework.pagination.CursorPagination',
'PAGE_SIZE': 100
}
显示效果:
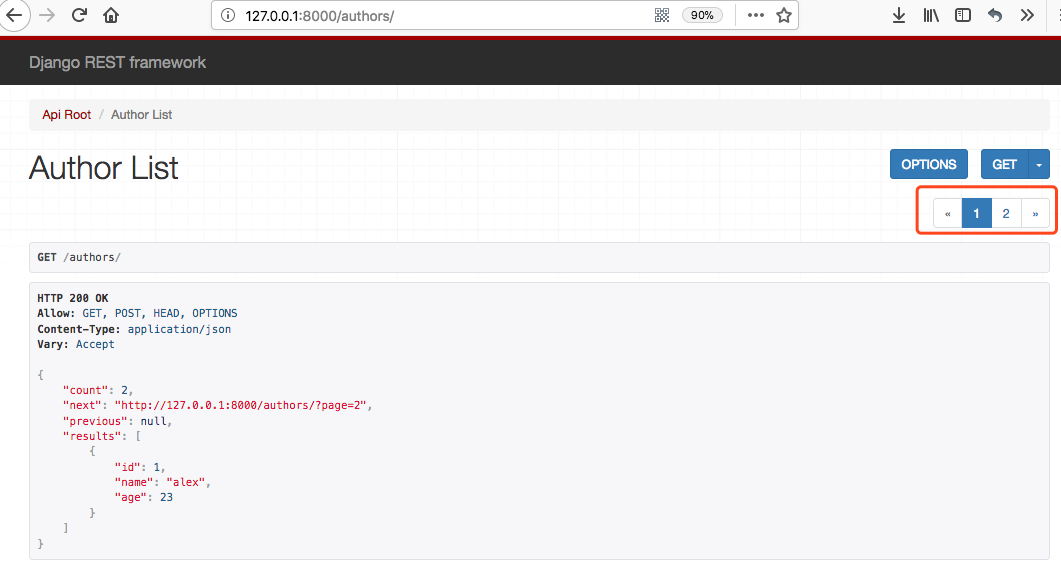
四、响应器(response)
五、渲染器
规定页面显示的效果(无用)。
1、局部添加渲染器
urls.py:
from django.conf.urls import url, include
from api.views import course
urlpatterns = [
# path('admin/', admin.site.urls),
url(r'^api/course/$', course.CourseView.as_view()),
]
api/views/course.py:
from rest_framework.views import APIView
from rest_framework.response import Response
from rest_framework.renderers import JSONRenderer,BrowsableAPIRenderer
class CourseView(APIView):
# 渲染器
# renderer_classes = [JSONRenderer] # 表示只返回json格式
renderer_classes = [JSONRenderer, BrowsableAPIRenderer] # 数据嵌套在html中展示
def get(self, request, *args, **kwargs):
return Response('...')
显示效果:
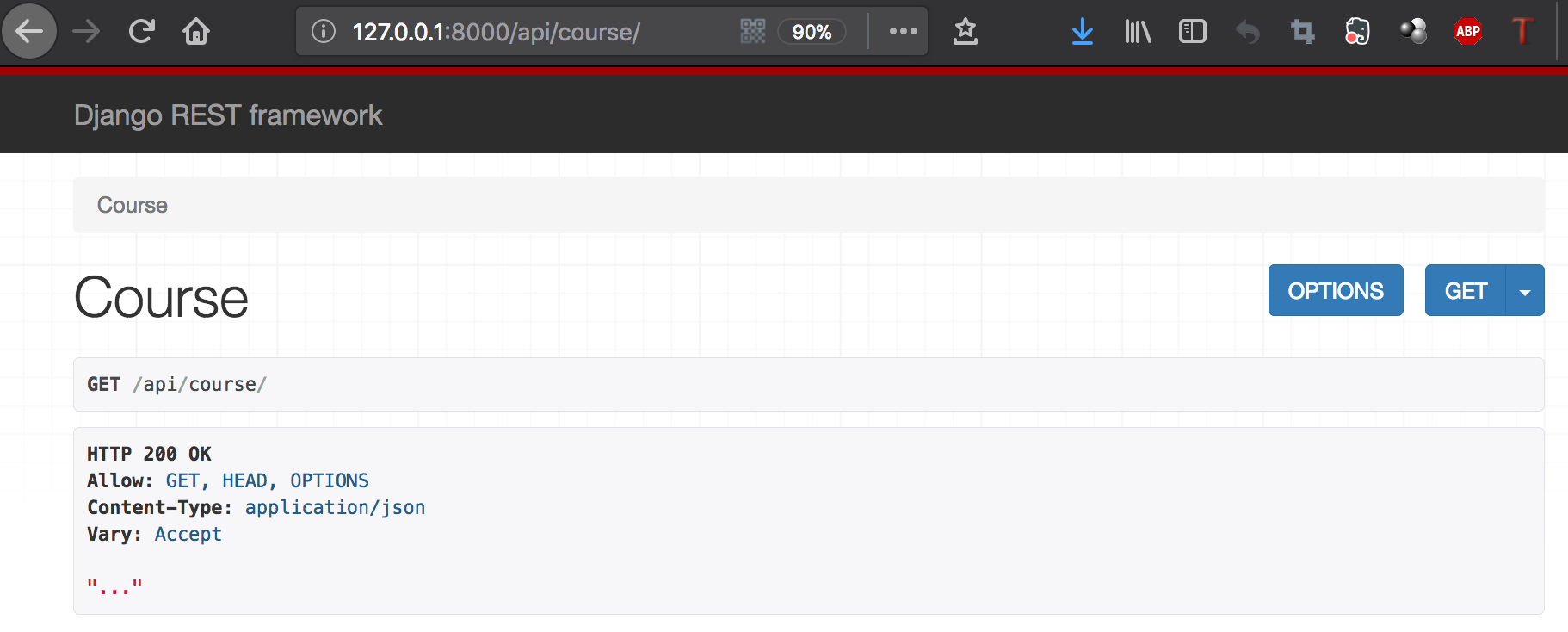
2、全局添加渲染器
settings.py:
# 渲染器配置到全局
REST_FRAMEWORK = {
'DEFAULT_RENDERER_CLASSES': ['rest_framework.renderers.JSONRenderer','rest_framework.renderers.BrowsableAPIRenderer']
}
显示效果同上。