原文:你不知道的js系列
什么是作用域(Scope)?
作用域 是这样一组规则——它定义了如何存放变量,以及程序如何找到之前定义的变量。
编译器原理
JavaScript 通常被归类为动态语言或者解释型语言,但实际上它是编译型语言。它不是像其它传统的编译型语言一样预先编译好,编译后也不能在各种系统上兼容。
但无论如何,JS 引擎采取和传统编译器相同的步骤,只不过以一种更不易被人意识到的负责的方式。
传统编译型语言的处理过程:
1. 分词/词法分析(Tokenizing/Lexing)
将一连串字符分割成有意义的片段,称为 token。比如 var a = 2; 可能会被分成几个 token :var,a,=,2,和;空格也有可能被保留为一个 token,取决于这个空格符是否有意义。
注:词法分析可以理解为基于有状态分析规则进行的分词,比如 a 是一个独立的 token 还是 其它 token 的一部分。
2. 解析 (Parsing)
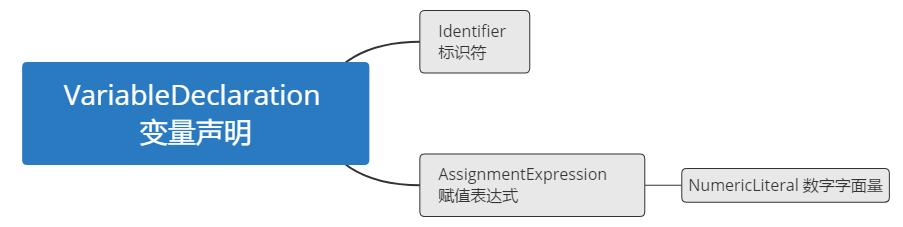
将一个 token 序列转换成一个抽象语法树(Abstract Syntax Tree),代表整个程序的语法结构。
比如 var a = 2;可能就会有一个最上层的结点叫做变量声明,然后一个子结点标识符 代表 a,另一个子结点为赋值表达式,表达式下面又有一个子结点叫做数字字面量,值为 2。
3. 代码生成 (Code-Generation)
将一个抽象语法树转换成可执行代码。这部分的实现很大程度上依赖目标语言和平台。
所以抛开具体细节,我们只需要知道,通过某种方式,将上一步解析 var a = 2;得到的 AST转化成一系列机器指令,这些指令真正意义上创建了变量 a (在内存中)并赋给一个值。
而 JavaScript 引擎比这些步骤还要更加复杂。比如,在解析和代码生成的过程中,有对执行性能的优化以及去除冗余元素等。
首先,JavaScript 引擎没有足够的时间去做代码优化,因为 JavaScript 编译器没有预先构建的步骤。
对于 JavaScript 来说,很多情况下,在运行之前只有几微妙的时间去编译。
简单来说,任何 JavaScript 代码在执行之前都会先经过编译,然后立即执行。
理解作用域 (Scope)
我们可以将编译的过程理解为一场对话,编译对象为 var a = a;
出场角色:
1.引擎——负责代码的编译和执行
2.编译器——引擎的一个朋友,负责分析语法和生成代码
3.作用域——引擎的另一个好朋友,收集和保存声明过的标识符(变量),以及严格规定了正在执行的代码如何对这些变量进行访问。
台前幕后:
当你看到代码 var a = 2;时,你很可能会把它看作一条语句,但引擎不是这么认为的。事实上,引擎看到的是两条语句,一个是编译器在编译的时候处理的,一个是在引擎执行代码期间才会处理的。
编译器做的第一件事情是分词,生成语法树。
接下来你可能假设编译器会生成类似于这样的代码:给变量分配一个内存区域,标记为 a,然后把值 2 放入 这个变量里。
事实上编译器是这样做的:
1. 遇到 var a,编译器会问作用域,是否有变量 a 已经存在于当前的作用域集合,如果有,编译器就会忽略这个声明,否则,编译器会让作用域在当前的集合中新增一个变量a。
2. 编译器生成可执行代码,让引擎去执行,处理 a = 2 这个赋值语句。执行过程中,这段代码会首先问作用域,当前的集合范围内是否存在一个变量 a 可以访问,如果有,引擎会使用这个变量,如果没有,就会向上查找(嵌套作用域)
如果引擎最终可以找到这个变量,就给它赋值为 2,如果没有,引擎就会举手大喊“有个错误”
总结:一个变量赋值有两个动作,首选编译器声明变量(如果在当前范围内没有被声明过),其次,引擎查找这个变量,如果找到就赋值给这个变量。
编译器说
我们需要一些术语来进一步理解。
当引擎执行编译器在第 2 步生成的代码时,它必须去查找是否这个变量已经被声明,这个查找就是去问作用域,但是查询的方式会影响查询的结果。
在这个例子中,引擎将进行 “LHS” 查询变量 a ,另外一种查询为 “RHS”。
LHS 代表 左边,RHS 是右边,这个左右是对于赋值操作符来说的。
当一个变量出现在赋值操作符的左边时,就会进行 LHS 查找,反之,则是 RHS 查找。
一个 RHS 是不太好区分的,因为它仅仅是查询变量的值,而 LHS 查询就是查找这个变量本身,然后可以进行赋值。
从这方面看,RHS 并不是真的在赋值操作右边的意思,它仅仅意味着不在左边。你也可以认为 RHS 是去取某个值。
比如:
console.log(a);
这里的 a 就是一个 RHS 引用,因为 a 没有被赋值,我们只是把 a 里的值取出来传给了console.log()
a = 2;
这个 a 就是一个 LHS 引用,因为这里我们不关心当前 a 的值是什么,我们只想把 2 赋值给它
注:LHS 和 RHS 这里的左右并不一定是字面代表的赋值操作符的左右,赋值也会以其它方式进行。所以 LHS 为赋值的目标,RHS 为赋值的源。
function foo(a) { console.log( a ); // 2 } foo( 2 );
这里 foo(a) 中的 foo 就是一个 RHS 引用,而 foo(2) 在执行之后,把值 2 赋值给了参数 a,所有这里 a 是一个 LHS 引用。
在 console.log(a) 中,a 又是一个 RHS 引用,得到的值传给 console.log(),console 是一个 RHS 引用,然后检查这个对象是否有 log() 方法。
最后,概念化描述一下,当值 2 通过 a 传入 log() 时,a 发生了一个 LHS/RHS 交换,在 log 方法的内部实现中,我们可以假设它有参数,第一个参数是一个 LHS 引用,然后赋值为2 。
注:你可能会将函数声明理解为普通的变量声明和赋值,例如 var foo 以及 foo = function(a){... ,也就会认为这里包含一次 LHS 查询。
然而,这个细小但很重要的区别是,编译器在代码生成的时候处理声明和值的定义,也就是说在引擎执行代码的时候,没必要有把一个函数赋值给变量 foo 这个操作,因此,把一个函数声明看作是一个 LHS 查询赋值是不太合适的。
引擎/作用域 对话
还是上面的代码,想象一组对话:
引擎:嘿!作用域,我有一个 foo 的 RHS 引用,你听过它吗?
作用域:呀 我见过,编译器刚刚声明了它,它是一个函数,给你。
引擎:太棒了 谢谢!我要执行 foo 了
引擎:嘿!作用域,我有一个 对 a 的 LHS 引用,你听过吗?
作用域:呀 我见过的,编译器刚刚声明了它作为 foo 的形参,给你啦
引擎:再次感谢啦!现在可以把 2 赋值给 a 了
引擎:嘿!作用域,我有一个 对 console 的 RHS 引用,你听过吗?
作用域:没问题,它是个内置对象,给你
引擎:完美!查找 log(),找到!太好了,这是个函数
引擎:嘿!作用域,你帮我查一下对 a 的 RHS 引用,我记得它,但是想再次确认一下。
作用域:你是对的!还是那个 a ,给你
引擎:好了!现在把 a 的值,也就是 2 ,传给 log()
……
测试:
function foo(a) { var b = a; return a + b; } var c = foo( 2 );
找出其中的 LHS 查询(3个)
找出其中的 RHS 查询(4个)
注:在小结中查看答案
嵌套作用域
作用域是一组定义如何通过标识符名称查询变量的规则。通常程序中不只有一个作用域。
就像一个代码块或者函数可以被嵌套在另一个代码块或者函数中,作用域也可以嵌套别的作用域。
所以如果一个变量在当前的作用域没有被找到的话,引擎就会查找包含这个作用域的外部作用域,直到找到这个变量或者一直达到最外层(也就是全局作用域)。
function foo(a) { console.log( a + b ); } var b = 2; foo( 2 ); // 4
在这段代码中,对 b 的 RHS 引用在 foo 内部无法解决,但是在全局作用域中存在。
引擎在查找到最外层的全局作用域时就会停止,无论是否找到到变量。
建筑比喻

这栋建筑代表程序的嵌套作用域规则集合。第一层是代表你现在正则执行的作用域。建筑顶层是全局作用域。
你要查找当前的楼层来解析 LHS 和 RHS 引用。如果没找到,就坐电梯去上一层找,然后再上一层,……
错误
为什么区别 LHS 和 RHS 是重要的?
因为如果变量没有被声明时,这两种查找的行为是不一样的。
function foo(a) { console.log( a + b ); b = a; } foo( 2 );
当对 b 进行 RHS 查找时,没有找到,这个时候就做 未声明 变量,引擎会抛出 ReferenceError 类型的错误。
相反,如果引擎进行 LHS 查找的时候,直到全局作用域都没有查询成功,如果程序不是在严格模式下,全局作用域会创建一个变量,然后返回给引擎。
但在严格模式下,引擎会和 RHS 的情况一样,抛出 ReferenceError 类型的错误。
如果一个 RHS 引用的变量被查找到,但是你想做一些不可能的操作,比如把一个非函数的值当作函数去调用,或者引用值为 null 或 undefined 的变量的属性,这时引擎就会抛出 TypeError 类型的错误。
ReferenceError 是作用域解析失败相关的错误,而 TypeError 表示作用域查找没有问题,但是对于值的操作非法/不可能的操作。
总结:
作用域的概念
LHS 查询和 RHS 查询
与作用域相关的赋值可以发生在赋值语句或者调用函数传参时
LHS 查询失败在严格模式和非严格模式下表现不同,在严格模式下抛出 ReferenceError 错误。
测试题答案
1. c = ..
a = 2
b = ..
2. foo(2..
= a;
a + ..
.. + b
原文地址 https://github.com/getify/You-Dont-Know-JS/blob/master/scope%20%26%20closures/ch1.md