特征工程:

一.数据处理
1.数据收集
埋点,mysql,hdfs,日志等收集。
2.数据清洗
a.不符合常理数据
b.超出统计值的数据
c.缺省值极多的字段
3.数据采样
(1)正样本大于负样本,且相差很大
下采样(截取与负样本量相近的正样本)
(2)正样本大于负样本,相差不大
a.采集跟多数据
b.上采样(样本复制,图像识别中图像的镜像和反转)
c.修改损失函数
4.缺失值
(1)直接删除法
(2)平均值法
(3)最近邻法
(4)最大类法
(5)不处理法
二.特征处理
1.数值型
(1)无量纲
不属于同一量纲:即特征的规格不一样,不能够放在一起比较。无量纲化使不同规格的数据转换到同一规格。常见的无量纲化方法有标准化和区间缩放法。
a.标准化
标准化的前提是特征值服从正态分布,标准化后,其转换成标准正态分布。 标准化需要计算特征的均值和标准差,公式表达为:

from sklearn.preprocessing import StandardScaler
b.区间缩放法
区间缩放法利用了边界值信息,将特征的取值区间缩放到某个特点的范围,例如[0, 1]等
区间缩放法的思路有多种,常见的一种为利用两个最值进行缩放,公式表达为:

from sklearn.preprocessing import MinMaxScaler
c.归一化
归一化是依照特征矩阵的行处理数据,其目的在于样本向量在点乘运算或其他核函数计算相似性时,拥有统一的标准,也就是说都转化为“单位向量”。规则为l2的归一化公式如下:
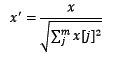
from sklearn.preprocessing import Normalizer
(2)离散化(函数分箱)
import pandas as pd
import numpy as py
arr = np.random.randn(20)
pd.cut(arr,5)
(3)hash分桶
2.类别型
(1)one-hot编码(哑变量)
pandas.get_dummies(data, prefix=None,
prefix_sep='_', dummy_na=False, columns=None, sparse=False, drop_first=False)
(2)hash与聚类
3.日期型
既可以看做连续值
(1)连续值
a.持续时间(浏览时长)
b.间隔时间(上次点击离现在的时间间隔)
(2)离散值
a.一天中的时间段
b.一周工作日与周日
c.一年中的季节
d.一年中的季度
4.文本型
词袋(分词)
(1)稀疏向量
一个词算为1,向量会很稀疏
(2)N-gram
n个词组合算一个整体,一般不超过3个。
(3)TF_IDF
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
TF(t) = (词t在当前文中出现次数) / (t在全部文档中出现次数)
IDF(t) = ln(总文档数/ 含t的文档数)
TF-IDF权重 = TF(t) * IDF(t)
(4)word2vec
5.特征组合
(1)简单组合特征 : 拼接型
一般是特征选择后,将特征权重高的进行更为细化的组合,$x1cdot x2$,${x_{1}}^{2}$,{x_{2}}^{2},sex_item.
(2)模型特征组合
a.用 GBDT 产出特征组合路径
b.组合特征和原始特征一起放进 LR训练
三.特征选择
1.Filter(过滤法):相关性对各个特征进行评分
(1)方差选择法
from sklearn.feature_selection import VarianceThreshold
(2)Pearson相关系数法
from sklearn.feature_selection import SelectKBest
from scipy.stats import pearsonr
(3)卡方检验
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
(4)互信息法,距离相关度
from sklearn.feature_selection import SelectKBest
from minepy import MINE
缺点:没有考虑到特征之间的关联作用,可能把有用的关联特征误踢掉。
2.Wrapper(包装法)
把特征选择看做一个特征子集搜索问题,筛选各种特征子集,用模型评估效果。递归消除特征法使用一个基模型来进行多轮训练,每轮训练后,消除若干权值系数的特征,再基于新的特征集进行下一轮训练。
典型的包裹型算法为 “递归特征删除算法 ”(recursive feature elimination algorithm)
from sklearn.feature_selection import RFE
from sklearn.linear_model import LogisticRegression
比如用逻辑回归:
a.用全量特征跑一个模型。
b.根据线性模型的系数(体现相关性),删5-10%的弱特征,观察准确率AUC的变化。
c.逐步进行, 直至准确率AUC出现大的下滑停止。
3.Embedded(嵌入法)
(1)正则化方式来做特征选择(L1,L2正则化)
from sklearn.feature_selection import SelectFromModel
from sklearn.linear_model import LogisticRegression
SelectFromModel(LogisticRegression(penalty="l1", C=0.1)).fit_transform(data,target)
用LR做CTR预估,在3-5亿维的系数特征上用L1正则化的LR模型。剩余2-3千万的feature,说明其他的 feature重要度不够 。
(2)基于树模型的特征选择法
树模型中GBDT也可用来作为基模型进行特征选择,使用feature_selection库的SelectFromModel类结合GBDT模型。
from sklearn.feature_selection import SelectFromModel
from sklearn.ensemble import GradientBoostingClassifier
SelectFromModel(GradientBoostingClassifier()).fit_transform(data, target)
四.特征降维
特征选择与特征降维:前者只踢掉原本特征里和结果预测关系不大的,后者做特征的计算组合构成新特征,解决特征矩阵过大,导致计算量大,训练时间长的问题
1.PCA:主成分分析法
from sklearn.decomposition import PCA
2.LDA:线性判别分析法
from sklearn.lda import LDA