1. 不同进程之间的资源是互相隔离的
from multiprocessing import Process import os n=100 # 每次开启一个进程就会把这里的代码从头到尾执行一遍,所以每一个进程开始的n都是100,每开启一个进程对全局变量n都会执行减一操作 def func(): global n n-=1 print("子进程:%s,参数n:%s"%(os.getpid(),n)) if __name__=="__main__": for i in range(10): # 创建10个进程 p=Process(target=func) # 开启的每一个进程都是执行func函数 p.start() print("主进程:%s,参数n:%s"%(os.getpid(),n))
运行结果:
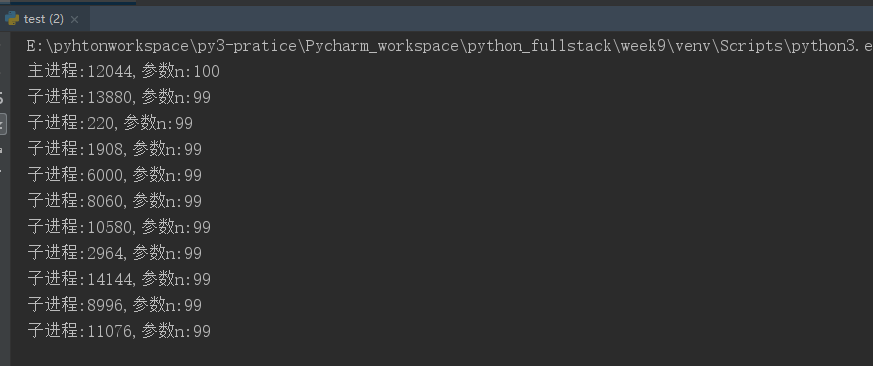
所以不同进程之间的数据是完全隔离的;
2. 创建进程的另一种方式
创建进程可以使用Process类 或者可以自己创建一个类:
from multiprocessing import Process import os class MyProcess(Process): # 自定义一个类继承自Process类 def run(self): # 当创建的子进程对象执行start方法时 就会自动调用r类内的un方法 print("子进程:%s"%os.getpid()) if __name__=="__main__": p=MyProcess() # 实例化一个类,创建进程 p.start() # 就会自动执行MyProcess类的run()方法 print("主进程:%s"%os.getpid())
运行结果:

可是如果我们想对要创建的子进程执行的函数传递一个参数,应该怎么操作:
其实只需要在创建类的时候,初始化方法中传递参数即可:
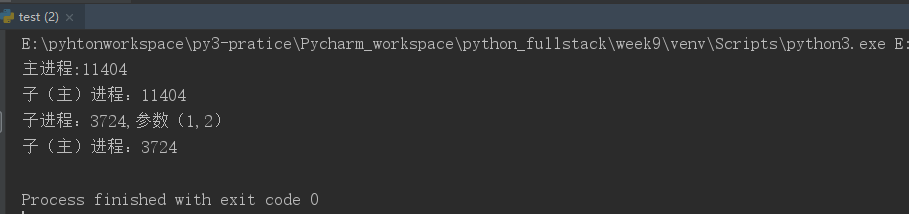
from multiprocessing import Process import os class MyProcess(Process): # 创建一个类,继承自Process def __init__(self,arg1,arg2): super().__init__() # 需要继承自父类Process的初始化方法,不要进行重写初始化方法,否则会覆盖, self.arg1=arg1 self.arg2=arg2 def run(self): # 创建的进程对象执行start方法时会自动执行类中的run方法 print("子进程:%s,参数(%s,%s)"%(os.getpid(),self.arg1,self.arg2)) if __name__=="__main__": p=MyProcess(1,2) # 创建一个进程 p.start() # 开启一个进程,会自动执行类MyProcess类中的run()方法 print("主进程:%s"%os.getpid())
运行结果:
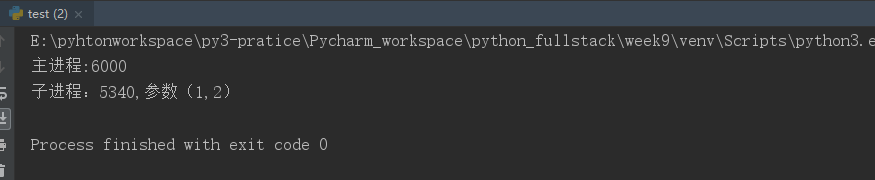
在自定义的类中实现其他的方法(比如下面例子中的walk()方法),在主进程中调其实是在主进程中执行类中的方法,在类内调用类内的方法,会在子进程中执行类中的方法:
from multiprocessing import Process import os class MyProcess(Process): # 创建一个类,继承自Process def __init__(self,arg1,arg2): super().__init__() # 需要继承自父类Process的初始化方法,不要进行重写初始化方法,否则会覆盖, self.arg1=arg1 self.arg2=arg2 def run(self): # 创建的进程对象执行start方法时会自动执行类中的run方法 print("子进程:%s,参数(%s,%s)"%(os.getpid(),self.arg1,self.arg2)) self.walk() # 在run()方法中调用walk()方法,就是在子进程中执行该方法 def walk(self): print("子(主)进程:%s"%os.getpid()) # 在类内调用walk()方法,就是子进程来执行,就是子进程的pid号,在主进程中调用walk()方法就由主进程来执行该方法,相应的就是主进程的pid号 if __name__=="__main__": p=MyProcess(1,2) # 创建一个进程 p.start() # 开启一个进程,会自动执行类MyProcess类中的run()方法 print("主进程:%s"%os.getpid()) p.walk() # 打印主进程的pid号,因为是在主进程中调用的该方法
运行结果: