1. 协程---多个协程 执行函数其实仍然是在同一个线程内完成的,只不过多个协程之间仍然是异步并发执行的
from gevent import monkey;monkey.patch_all() # 加上这句话,gevent遇到其他模块(time,socket等IO操作)的IO 需要等待时 就会切换协程 import gevent from threading import current_thread import time def func1(): print(current_thread().name) # 打印当前线程名(其实协程并不是线程,多个协程是在同一个线程内完成的) print("hello,xuanxuan") time.sleep(1) print("bye") def func2(): print(current_thread().name) # 打印当前线程名(其实开的是协程,多个协程是在同一个线程内执行的) print("hello,xixi") time.sleep(1) g1=gevent.spawn(func1) g2=gevent.spawn(func2) gevent.joinall([g1,g2]) # 在主线程中统一关闭多个协程(但是多个协程之间仍然是并发执行的)
运行结果: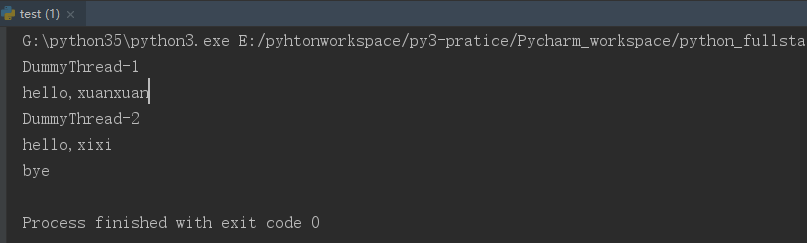
2. 测试有IO操作时,使用多个协程与开单线程单步执行多个任务执行效率的对比
结论: 当需要执行的任务有很多IO操作(比如网络延时requests爬取网页,socket请求等) 开多个协程执行任务,比使用单线程单步执行多个任务(同步执行)效率要高很多;
from gevent import monkey;monkey.patch_all() # 保证gevent在遇到其他模块(time,requests,socket)的IO操作时可以切换协程,从而实现异步,完成时间复用 import gevent import time def task(i): time.sleep(1) print(i) def sync_func(): # 同步执行 for i in range(10): # 有10个任务需要执行 task(i) def async_func(): g_lst=[] # 把开的协程存放成一个列表,最后统一join(),主线程等待所有协程执行完毕,但是多个协程之间仍然是异步并发执行的 for i in range(10): g=gevent.spawn(task,i) # gevent.spawn(func,arg) 创建并开启一个协程(这里是开启10个协程) g_lst.append(g) # 为了使多个协程之间异步并发执行 gevent.joinall(g_lst) # 多个协程统一join() 保证多个协程之间异步并发 start=time.time() sync_func() print("单线程单步执行多个任务所需要的时间:%s"%(time.time()-start)) start=time.time() async_func() print("开启多个协程执行多个任务所需要的时间是:%s"%(time.time()-start))
运行结果: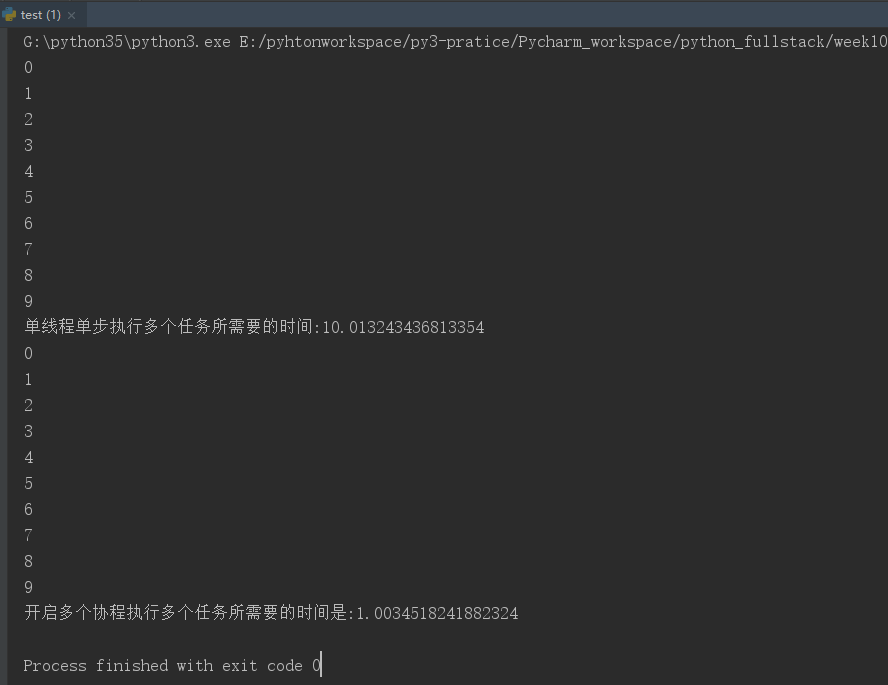
3. 开多个协程去爬取多个网页与单线程单步执行爬取网页的效率对比
爬取10个网页,协程函数去发起10个网页的爬取任务,协程在爬取网页时有一定的响应时间。在等待时,如果用到协程函数,一个函数在爬取网页过程中遇到网络延时(等待IO),它不会等待,而是紧接着去执行下一个任务,这样既可以复用时间,上面的网页等着,下面的网页都已经开始执行了;
from gevent import monkey;monkey.patch_all() # 保证使用gevent遇到其他模块(time,socket requests等网络延时)等的IO操作时可以切换协程,从而实现多个协程并发 import gevent import requests # 爬取网页 import time def get_url(url): ret=requests.get(url) print(url,ret.status_code,len(ret.text)) # 返回爬取网页的信息(requests.get(url).text----获取网页源代码; requests.get(url).status_code----获取网页状态码) url_lst=["http://www.baidu.com","http://www.sougou.com","http://www.python.org","http://www.qq.com","http://www.cnblog.com","http://www.mi.com"] g_lst=[] # 开多个协程然后存成一个列表,最后统一join,为了保证主线程等待所有协程执行完毕,但是多个协程之间是异步并发的; def async_func(): # 开多个协程执行10个爬取网页的任务(有只可能一个协程打开一个网页时,有网络延时,它不会等, # 直接开协程去请求其他的网页,在等待的过程中有可能其他网页都请求完了,从而实现时间的复用) for url in url_lst: g=gevent.spawn(get_url,url) g_lst.append(g) gevent.joinall(g_lst) # 多个协程统一关闭(保证多个协程之间异步并发执行,从而完成时间复用) def sync_func(): # 开单线程单步执行多个任务(爬取10个网页) for url in url_lst: get_url(url) start=time.time() async_func() print("开多个协程执行爬取10个网页的任务所用时间:%s"%(time.time()-start)) start=time.time() sync_func() print("开单线程单步执行爬取10个网页的任务所用时间为:%s"%(time.time()-start))
运行结果:
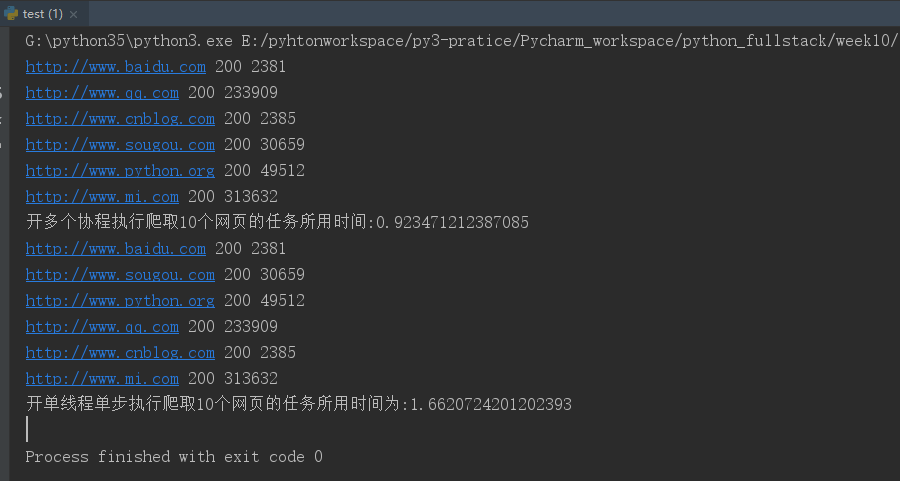
协程在响应一个网页时,有网络延时,它就可能利用这个时间去打开其他网页了,也就是时间复用,有可能利用第一个网页等待时间,把剩下所有网页的请求都发出去了;
同步单步执行时,每执行一个网页就会等待网络延时,串行的;而协程就是在发送一个网页时,不等,因为它直到有网络延时,所以直接执行下一个任务;