1.定义
哈夫曼编码主要用于数据压缩。
哈夫曼编码是一种可变长编码。该编码将出现频率高的字符,使用短编码;将出现频率低的字符,使用长编码。
变长编码的主要问题是,必须实现非前缀编码,即在一个字符集中,任何一个字符的编码都不是另一个字符编码的前缀。如:0、10就是非前缀编码,而0、01不是非前缀编码。
2.哈夫曼树的构造
按照字符出现的频率,总是选择当前具有较小频率的两个节点,组合为一个新的节点,循环此过程知道只剩下一个节点为止。
对于5个字符A、B、C、D、E,频率分别用1、5、7、9、6表示,则构造树的过程如下:

上面过程对应的哈夫曼树为:
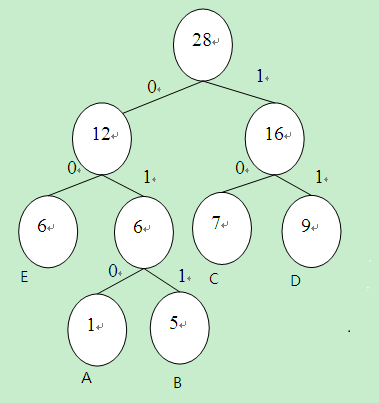
假设规定左边为0,右边为1,则变长编码为:
A 1:010
B 5:011
C 7:10
D 9:11
E 6: 00
3.哈夫曼构造代码


1 #include <iostream> 2 #include <string.h> 3 using namespace std; 4 struct Node{ 5 char c; 6 int value; 7 int par; 8 char tag; //tag='0',表示左边;tag='1',表示右边 9 bool isUsed; //判断这个点是否已经用过 10 Node(){ 11 par=-1; 12 isUsed=false; 13 } 14 }; 15 16 int input(Node*,int); //输入节点信息 17 int buildedTree(Node*,int); //建哈夫曼树 18 int getMin(Node*,int); //寻找未使用的,具有最小频率值的节点 19 int outCoding(Node*,int); //输出哈夫曼编码 20 21 int main () 22 { 23 int n; 24 cin>>n; 25 Node *nodes=new Node[2*n-1]; 26 input(nodes,n); 27 buildedTree(nodes,n); 28 outCoding(nodes,n); 29 delete(nodes); 30 return 0; 31 } 32 33 int input(Node* nodes,int n){ 34 for(int i=0;i<n;i++){ 35 cin>>(nodes+i)->c; 36 cin>>(nodes+i)->value; 37 } 38 return 0; 39 } 40 41 int buildedTree(Node* nodes,int n){ 42 int last=2*n-1; 43 int t1,t2; 44 for(int i=n;i<last;i++){ 45 t1=getMin(nodes,i); 46 t2=getMin(nodes,i); 47 (nodes+t1)->par=i; (nodes+t1)->tag='0'; 48 (nodes+t2)->par=i; (nodes+t2)->tag='1'; 49 (nodes+i)->value=(nodes+t1)->value+(nodes+t2)->value; 50 } 51 return 0; 52 } 53 54 int getMin(Node* nodes,int n){ 55 int minValue=10000000; 56 int pos=0; 57 for(int i=0;i<n;i++) 58 { 59 if((nodes+i)->isUsed == false && (nodes+i)->value<minValue){ 60 minValue=(nodes+i)->value; 61 pos=i; 62 } 63 } 64 (nodes+pos)->isUsed=true; 65 return pos; 66 } 67 68 int outCoding(Node* nodes,int n){ 69 char a[100]; 70 int pos,k,j; 71 char tmp; 72 for(int i=0;i<n;i++){ 73 k=0; 74 pos=i; 75 memset(a,'�',sizeof(a)); 76 while((nodes+pos)->par!=-1){ 77 a[k++]=(nodes+pos)->tag; 78 pos=(nodes+pos)->par; 79 } 80 strrev(a); //翻转字符串 81 cout<<(nodes+i)->c<<" "<<(nodes+i)->value<<":"<<a<<endl; 82 } 83 return 0; 84 }
执行示例:
