一 GIL
1 GIL是什么
1 GIL的全称是Global Interpreter Lock(全局解释器锁),来源是python设计之初的考虑,为了数据安全所做的决定。
2 每个CPU在同一时间只能执行一个线程(在单核CPU下的多线程其实都只是并发,不是并行,并发和并行从宏观上来讲都是同时处理多路请求的概念。但并发和并行又有区别,并行是指两个或者多个事件在同一时刻发生;而并发是指两个或多个事件在同一时间间隔内发生。)
可见,某个线程想要执行,必须先拿到GIL,我们可以把GIL看作是“通行证”,并且在一个python进程中,GIL只有一个。拿不到通行证的线程,就不允许进入CPU执行。
2 python2和python3中GIL的区别
在python2.x里,GIL的释放逻辑是当前线程遇见IO操作或者ticks计数达到100(ticks可以看作是python自身的一个计数器,专门做用于GIL,每次释放后归零,这个计数可以通过 sys.setcheckinterval 来调整,执行字节码 行数),进行释放。
而每次释放GIL锁,线程进行锁竞争、切换线程,会消耗资源。并且由于GIL锁存在,python里一个进程永远只能同时执行一个线程(拿到GIL的线程才能执行),这就是为什么在多核CPU上,python的多线程效率并不高而在python3.x中,GIL不使用ticks计数,改为使用计时器(执行时间达到阈值后,当前线程释放GIL),这样对CPU密集型程序更加友好,但依然没有解决GIL导致的同一时间只能执行一个线程的问题,所以效率依然不尽如人意。
多核多线程比单核多线程更差,原因是单核下多线程,每次释放GIL,唤醒的那个线程都能获取到GIL锁,所以能够无缝执行,但多核下,CPU0释放GIL后,其他CPU上的线程都会进行竞争,但GIL可能会马上又被CPU0拿到,导致其他几个CPU上被唤醒后的线程会醒着等待到切换时间后又进入待调度状态,这样会造成线程颠簸(thrashing),导致效率更低
3 python的多线程没用?
我们进行分类讨论:
1、CPU密集型代码(各种循环处理、计数等等),在这种情况下,ticks计数很快就会达到阈值,然后触发GIL的释放与再竞争(多个线程来回切换当然是需要消耗资源的),所以python下的多线程对CPU密集型代码并不友好。
2、IO密集型代码(文件处理、网络爬虫等),多线程能够有效提升效率(单线程下有IO操作会进行IO等待,造成不必要的时间浪费,而开启多线程能在线程A等待时,自动切换到线程B,可以不浪费CPU的资源,从而能提升程序执行效率)。所以python的多线程对IO密集型代码比较友好。
4 IO密集型用多线程,CPU(计算)密集型用多进程
每个进程有各自独立的GIL,互不干扰,这样就可以真正意义上的并行执行,所以在python中,多进程的执行效率优于多线程(仅仅针对多核CPU而言)。
所以我们能够得出结论:多核下,想做并行提升效率,比较通用的方法是使用多进程,能够有效提高执行效率
二 进程线程协程
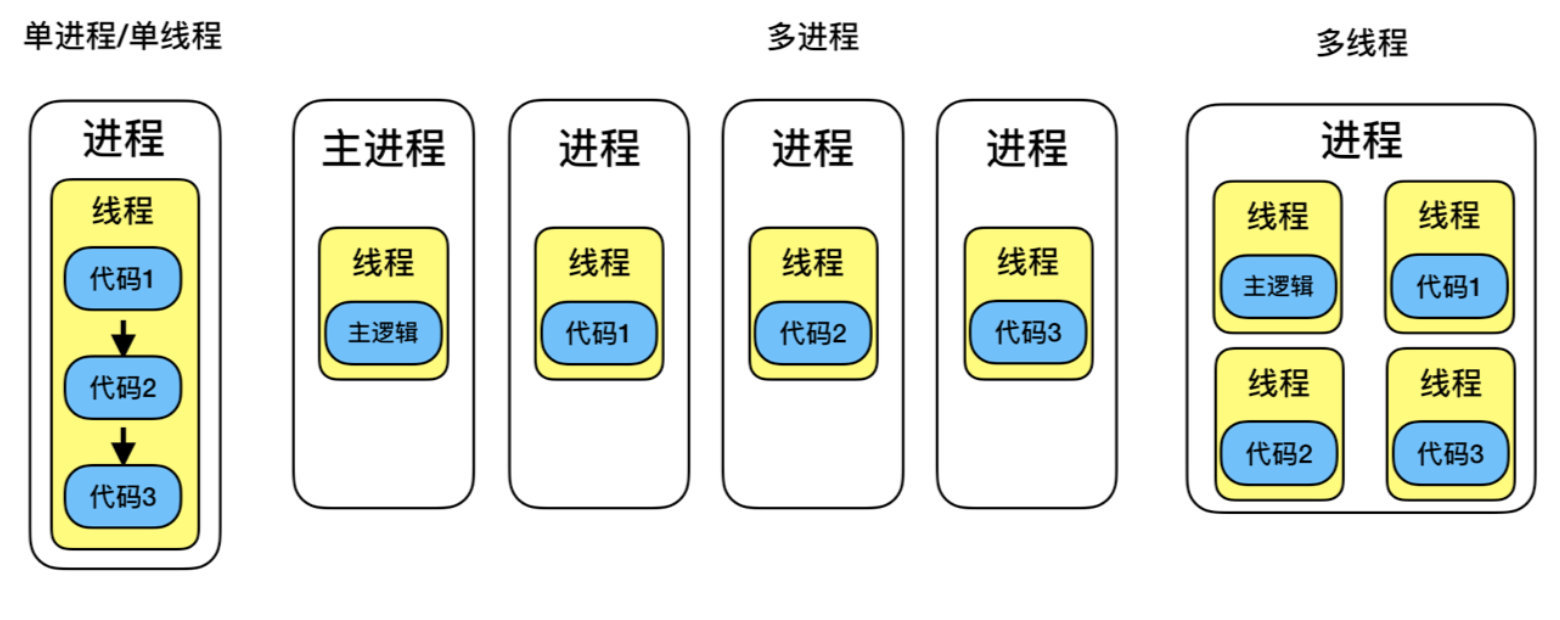
1 进程
进程是具有一定独立功能的程序、它是系统进行资源分配和调度的一个独立单位,重点在系统调度和单独的单位,也就是说进程是可以独 立运行的一段程序
2 线程
线程是进程的一个实体,是CPU调度和分派的基本单位,他是比进程更小的能独立运行的基本单位,线程自己基本上不拥有系统资源。在运行时,只是暂用一些计数器、寄存器和栈 。
1 一个线程只能属于一个进程,而一个进程可以有多个线程,但至少有一个线程(通常说的主线程)。
2 资源分配给进程,同一进程的所有线程共享该进程的所有资源。
3 线程在执行过程中,需要协作同步。不同进程的线程间要利用消息通信的办法实现同步。
4 处理机分给线程,即真正在处理机上运行的是线程。
5 线程是指进程内的一个执行单元,也是进程内的可调度实体。
3 协程
程序中任务执行的本质是CPU作为执行者运行代码,因此并行必定意味着多核,并发好比单核切换交替执行多个任务。
由于Python解释器中GIL全局解释器锁的问题,Python的多线程只能实现并发,多进程才能实现并行。而协程是在单线程中实现的,因此协程也只能实现并发。
协程又被称为微线程,是抽象出来的一个概念;而进程和线程都是实际存在的对象,是操作系统中确确实实存在的东西。
因而多进程、多线程的切换是操作系统负责的,而协程的切换不是由操作系统的。
也就是说只要是单线程中实现了多个任务的交替/切换的执行,那么它就是协程。同时协程的切换本质上由用户控制。
协程的实现方式其实都是通过将CPU的执行环境(控制单元、存储单元、运算单元)进行替换实现的。因为CPU只根据它控制单元、存储单元、运算单元里的东西来运算。
如当前CPU正在运行函数1,那么此时直接将函数1在CPU的运行情况保存起来,然后替换成函数2的,这样就实现了从函数1到函数2的切换。
具体实现一般分为两种情况:
一种是语言特性,原生支持,如Python的yield、Go的goroutine等;
另一种是第三方模块的单独实现,如gevent中的使用的greenlet。
IO密集任务与计算密集任务
- IO密集型:适合多线程或协程
- 大量磁盘I/O操作(文件读写、磁盘读写)
- 大量网络I/O操作(网络请求、socket程序)
- 计算密集型:适合多进程
- 大量运算操作(计算精确到小数点1000位的圆周率、视频高清解码、图像运算)
- 大量逻辑判断操作(循环判断、if判断等大量逻辑代码处理)
- 原因:
- I/O操作不会占用CPU,多线程、协程能同时处理多个I/O操作
- 计算操作需要一直使用CPU,多进程能利用多个核心
- 多进程资源开销比多线程资源开销大很多
网络应用是I/O密集型应用,爬虫程序是I/O密集型应用。
而显然针对I/O密集型程序,协程开销相较于线程小得多
三 IO操作与IO模型
1 IO操作
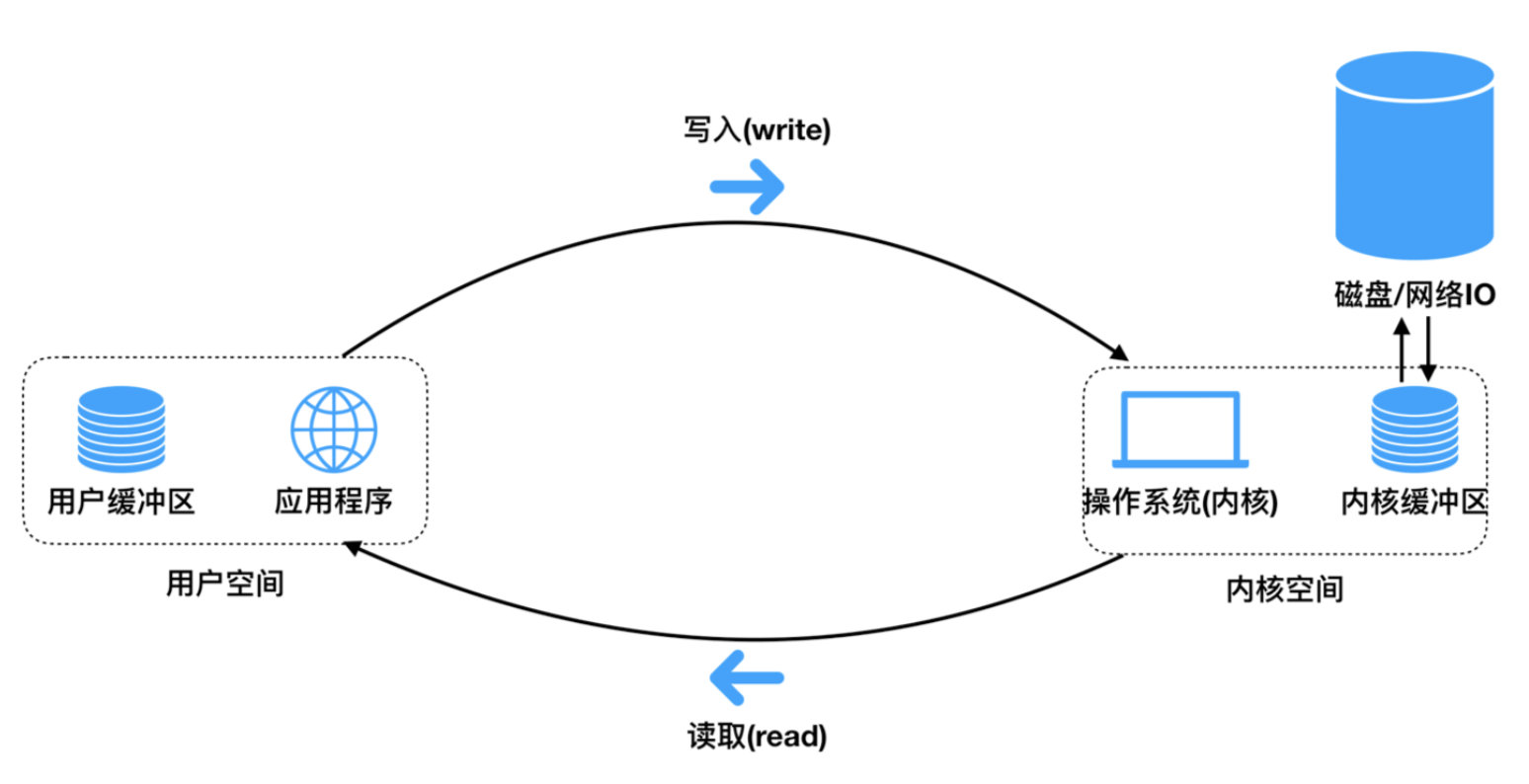
数据复制的过程中不会消耗CPU
用户的应用程序不能直接操作内核缓冲区,需要将数据从内核拷贝到用户才能使用
而IO操作、网络请求加载到内存的数据一开始是放在内核缓冲区的
2 IO模型
1. BIO – 阻塞模式I/O
用户进程从发起请求,到最终拿到数据前,一直挂起等待; 数据会由用户进程完成拷贝
''' 举个例子:一个人去 商店买一把菜刀, 他到商店问老板有没有菜刀(发起系统调用) 如果有(表示在内核缓冲区有需要的数据) 老板直接把菜刀给买家(从内核缓冲区拷贝到用户缓冲区) 这个过程买家一直在等待 如果没有,商店老板会向工厂下订单(IO操作,等待数据准备好) 工厂把菜刀运给老板(进入到内核缓冲区) 老板把菜刀给买家(从内核缓冲区拷贝到用户缓冲区) 这个过程买家一直在等待 是同步io '''
2. NIO – 非阻塞模式I/O
用户进程发起请求,如果数据没有准备好,那么立刻告知用户进程未准备好;此时用户进程可选择继续发起请求、或者先去做其他事情,稍后再回来继续发请求,直到被告知数据准备完毕,可以开始接收为止; 数据会由用户进程完成拷贝
''' 举个例子:一个人去 商店买一把菜刀, 他到商店问老板有没有菜刀(发起系统调用) 老板说没有,在向工厂进货(返回状态) 买家去别地方玩了会,又回来问,菜刀到了么(发起系统调用) 老板说还没有(返回状态) 买家又去玩了会(不断轮询) 最后一次再问,菜刀有了(数据准备好了) 老板把菜刀递给买家(从内核缓冲区拷贝到用户缓冲区) 整个过程轮询+等待:轮询时没有等待,可以做其他事,从内核缓冲区拷贝到用户缓冲区需要等待 是同步io 同一个线程,同一时刻只能监听一个socket,造成浪费,引入io多路复用,同时监听读个socket '''
3. IO Multiplexing - I/O多路复用模型
''' 举个例子:多个人去 一个商店买菜刀, 多个人给老板打电话,说我要买菜刀(发起系统调用) 老板把每个人都记录下来(放到select中) 老板去工厂进货(IO操作) 有货了,再挨个通知买到的人,来取刀(通知/返回可读条件) 买家来到商店等待,老板把到给买家(从内核缓冲区拷贝到用户缓冲区) 多路复用:老板可以同时接受很多请求(select模型最大1024个,epoll模型), 但是老板把到给买家这个过程,还需要等待, 是同步io '''
4. AIO – 异步I/O模型
发起请求立刻得到回复,不用挂起等待; 数据会由内核进程主动完成拷贝
三 同步I/O与异步I/O
- 同步I/O
- 概念:导致请求进程阻塞的I/O操作,直到I/O操作任务完成
- 类型:BIO、NIO、IO Multiplexing
- 异步I/O
- 概念:不导致进程阻塞的I/O操作
- 类型:AIO
注意:
- 同步I/O与异步I/O判断依据是,是否会导致用户进程阻塞
- BIO中socket直接阻塞等待(用户进程主动等待,并在拷贝时也等待)
- NIO中将数据从内核空间拷贝到用户空间时阻塞(用户进程主动询问,并在拷贝时等待)
- IO Multiplexing中select等函数为阻塞、拷贝数据时也阻塞(用户进程主动等待,并在拷贝时也等待)
- AIO中从始至终用户进程都没有阻塞(用户进程是被动的)
四 并发-并行-同步-异步-阻塞-非阻塞
# 1 并发 并发是指一个时间段内,有几个程序在同一个cpu上执行,但是同一时刻,只有一个程序在cpu上运行 跑步,鞋带开了,停下跑步,系鞋带 # 2 并行 指任意时刻点上,有多个程序同时运行在多个cpu上 跑步,边跑步边听音乐 # 3 同步: 指代码调用io操作时,必须等待io操作完成才返回的调用方式 # 4 异步 异步是指代码调用io操作时,不必等io操作完成就返回调用方式 # 6 阻塞 指调用函数时候,当前线程别挂起 # 6 非阻塞 指调用函数时候,当前线程不会被挂起,而是立即返回 # 区别: 同步和异步是消息通讯的机制 阻塞和非阻塞是函数调用机制