我们为什么需要锁?
在多用户环境中,在同一时间可能会有多个用户更新相同的记录,这就会产生冲突,这个就是著名的并发性问题。

图 1 并行性问题漫画
如何解决并发性问题?
借助正确的锁定策略可以解决并发性问题,资源被锁定后,其它进程想要访问它就会被阻止。
并发会造成什么样的冲突?
并发主要会导致四种常见的问题,详细情况请看下表。
| 问题 | 简要描述 | 解释 |
| 脏读取 | 当一个事务读取其它完成一半事务的记录时,就会发生脏读取 |
|
| 不可重复读取 | 在每次读数据时,如果你获得的值都不一样,那表明你遇到了不可重复读取问题 |
|
| 虚幻行 | 如果update和delete SQL语句未对数据造成影响,很可能遇到了虚幻行问题 |
|
| 更新丢失 | 一个事务的更新覆盖了其它事务的更新结果,就是所谓的更新丢失 |
|
如何解决上述冲突?
答案是使用乐观锁或悲观锁,下面将进一步进行阐述。
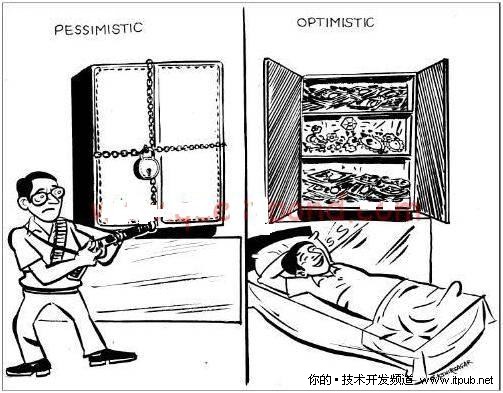
图 2 乐观锁和悲观锁
什么是乐观锁?
顾名思义,乐观锁假设多个事务相互不会影响对方,换句话说就是,在乐观锁模式下,没有锁操作会得到执行,事务只是验证是否有其它事务修改数据,如果有则进行事务回滚,否则就提交。

图 3 乐观锁
乐观锁是如何工作的?
实现乐观锁的方法有多种,但基本原则都一样,总是少不了下面五个步骤:
• 记录当前的时间戳
• 开始修改值
• 在更新前,检查是否有其他人更新了值(通过检查新旧时间戳实现)
• 如果不相等就回滚,否则就提交
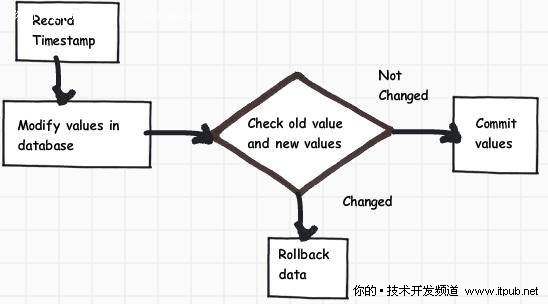
图 4 乐观锁的工作原理
实现乐观锁的解决方案
在.NET中,实现乐观锁的方法主要有三种:
• 数据集(Dataset):数据集是实现乐观锁的默认方法,在更新前它会检查新旧值。
• 时间戳数据类型(timestamp):在你的表中创建一个timestamp数据类型,在更新时,检查旧时间戳是否等于新时间戳。
• 直接检查新旧值:在更新时检查旧值和新值是否相等,如果不相等就回滚,否则就提交。
解决方案1:数据集
正如前面所说的,数据集是处理乐观锁的默认方法,下面是一个简单的快照,在Adapter的update函数上有一个调试点,当我移除断点运行update函数时,它抛出如下图所示的并行异常错误。

图 5 Update函数执行时抛出的异常错误
如果你运行后端分析器,你将会看到更新语句检查当前值和旧值是否相等:
exec sp_executesql N'UPDATE [tbl_items] SET [AuthorName] = @p1 WHERE (([Id] = @p2) AND ((@p3 = 1 AND [ItemName] IS NULL) OR ([ItemName] = @p4)) AND ((@p5 = 1 AND [Type] IS NULL) OR ([Type] = @p6)) AND ((@p7 = 1 AND [AuthorName] IS NULL) OR ([AuthorName] = @p8)) AND ((@p9 = 1 AND [Vendor] IS NULL) OR ([Vendor] = @p10)))',N'@p1 nvarchar(11),@p2 int,@p3 int,@p4 nvarchar(4),@p5 int,@p6 int,@p7 int,@p8 nvarchar(18),@p9 int,@p10 nvarchar(2)',@p1=N'this is new',@p2=2,@p3=0,@p4=N'1001',@p5=0,@p6=3,@p7=0,@p8=N'This is Old Author',@p9=0,@p10=N'kk'
在这种情况下,我尝试将“AuthorName”字段值修改为“This is new”,但更新时会检查旧值“This is old author”,下面是比较旧值的精简代码段:
,@p8=N'This is Old Author'
解决方案2:使用timestamp数据类型
SQL Server有一个数据类型是timestamp,它是实现乐观锁的另一种途径,每次更新SQL Server数据时,时间戳会自动产生一个唯一的二进制数值,时间戳数据类型可用来版本化你的记录更新。

图 6 timestamp数据类型
为了实现乐观锁,首先需要取得旧的时间戳值,在更新时检查旧的时间戳值是否等于当前时间戳,如:
update tbl_items set itemname=@itemname where CurrentTimestamp=@OldTimeStamp
然后检查是否发生了更新操作,如果没有发生更新,则使用SQL Server的raiserror产生一系列错误消息。
if(@@rowcount=0) begin raiserror('Hello some else changed the value',16,10) end
如果发生了并发冲突,当你如下图所示这样调用ExecuteNonQuery时,你应该会看到错误传播。

图 7 时间戳发生变化,存储过程产生了错误
解决方案3:检查旧值和新值
许多时候,我们只需要检查相关字段值的一致性,其它字段则可以忽略,在update语句中,我们可以直接做这种比较。
update tbl_items set itemname=@itemname where itemname=@OldItemNameValue
但使用乐观锁似乎没有完全解决问题,使用乐观锁只能检查并发性问题,为了从根源上解决并发性问题,我们需要使用悲观锁,因此乐观锁能起到预防作用,而悲观锁则能治愈。
什么是悲观锁?
悲观锁总是假定会发生并发性/冲突问题,因此会先对记录上锁,然后再更新。

图 8 悲观锁
如何处理悲观锁?
我们可以在SQL Server存储过程中指定IsolationLevel(隔离级别),ADO.NET级别或使用事务范围对象处理悲观锁。
使用悲观锁可以获得什么样的锁?
使用悲观锁可以获得四种类型的锁:共享(Shared)、独占(Exclusive),更新(Update)和意图(Intent),前两个是真实的锁,后面两个是锁和标记的混合。
| 何时使用 | 允许读 | 允许写 | |
| 共享锁 | 当你只想读,不希望其它事务进行更新时 | 是 | 否 |
| 独占锁 | 当你想修改数据,同时不希望别人可以读,直到你更新完毕时 | 否 | 否 |
| 更新锁 | 这是一个混合锁,当你执行的更新操作有多个步骤时使用 | ||
| 读阶段 | 是 | 否 | |
| 操作阶段 | 是 | 否 | |
| 更新阶段 | 否 | 否 | |
| 意向锁(请求锁) | 意向锁是分级的,当你想锁定下级资源时使用,例如,在表上的一个共享意向锁意味着共享锁是针对页面和表中的行的, | 不适用 | 不适用 |
| 模式锁 | 当你修改表结构时使用 | 否 | 否 |
| 大数据块更新锁 | 当你执行大数据块更新时使用 | 表级(否) | 表级(否) |
详解让人困惑的更新锁
其它锁都好理解,唯独更新锁让人迷糊,因为它混合了锁和标记,在更新前我们首先要读取记录,在读取期间锁是共享的,而在真正更新时,我们需要独占锁,更新锁是非常短暂的。
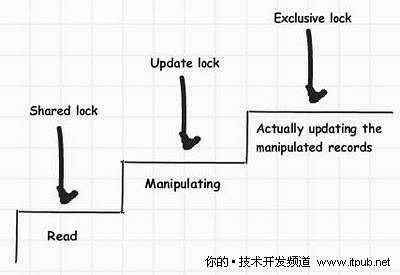
图 9 更新时用到的几种锁
不同隔离级别之间的差异,以及何时使用它们
有4种事务隔离级别,下表列出了这4种隔离级别及其使用时间。
| 隔离级别 | 读 | 更新 | 插入 |
| 读未提交的 | 读取未提交的数据 | 允许 | 允许 |
| 读已提交的(默认) | 读取已提交的数据 | 允许 | 允许 |
| 重复读 | 读取已提交的数据 | 不允许 | 允许 |
| 序列化 | 读取已提交的数据 | 不允许 | 不允许 |
如何指定隔离级别?
隔离级别是关系数据库的一个功能,也就是说,它基本上只与SQL Server相关,而与ADO.NET,EF或LINQ是没有什么关系的,但你可以在这些组件上设置隔离级别。
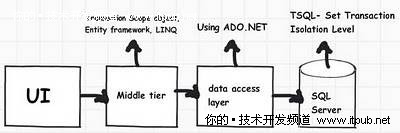
图 10 隔离级别
中间层:在中间层,你可以使用事务范围对象指定隔离级别。
TransactionOptions TransOpt = New TransactionOptions(); TransOpt.IsolationLevel = System.Transactions.IsolationLevel.ReadCommitted; using(TransactionScope scope = new TransactionScope(TransactionScopeOption.Required, TransOptions)) {
ADO.NET:在ADO.NET中你可以使用SqlTransaction对象指定事务隔离级别。
SqlTransaction objtransaction =
objConnection.BeginTransaction(System.Data.IsolationLevel.Serializable);
SQL Server:你也可以在TSQL中使用“SET TRANSACATION ISOLATION LEVEL”指定隔离级别。
SET TRANSACTION ISOLATION LEVEL READ COMMITTED;
事务隔离级别与它能解决的并发性问题之间的对应关系
| 读已提交的 | 重复读 | 序列化 | 读未提交的 | |
| 脏读取 | 能解决 | 能解决 | 能解决 | 不能 |
| 丢失更新 | 不能 | 能解决 | 能解决 | 不能 |
| 非重复读 | 不能 | 能解决 | 能解决 | 不能 |
| 幻想行 | 不能 | 不能 | 能解决 | 不能 |
解决方案4:使用“读已提交的”解决“脏读取”问题
关于“读已提交的”的一些关键点:
• 它是SQL Server默认的事务隔离级别。
• 它只读取已提交的数据,换句话说就是,任何未提交的数据它都会置之不理,直到数据提交为止,下图对其进行了详细解释,你也可以看到更新。
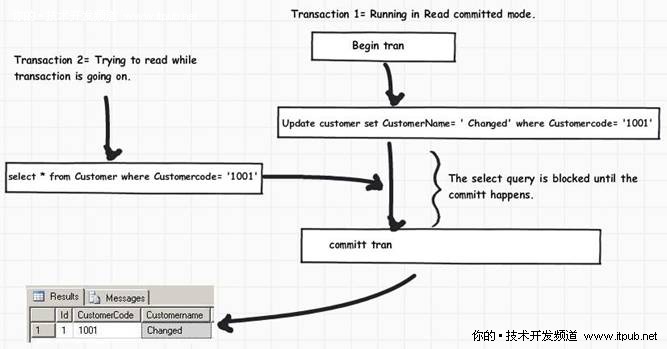
图 11 读已提交模式解析
如果你想看到上图所述的情况,只需要按照下面的步骤做就可以了:
• 打开两个查询窗口,执行一个更新事务,但不提交;
• 在第二个窗口中执行查询时,会显示如下图所示的查询被阻止的提示。

图 12 查询被阻止,直到更新事务提交后才能执行
“读已提交的”对立面是“读未提交的”吗?
是的,读未提交的是读已提交的对立面,当你设置读未提交的事务隔离级别时,未提交的数据也被读取了。
关于“读已提交的”关键点:
• 未提交的是可见的,因此脏读取是可能的;
• 没有锁被抓住;
• 当锁不重要时很有用,更重要的是并发性和吞吐量。
如果你也想测试一下,试试下面的SQL语句,它执行一个更新然,在等待20秒后回滚,在此期间如果你执行查询,返回的是未提交的数据,但20秒后,你再查询,返回的将会以前的旧数据,因为提交的数据已回滚。
set transaction isolation level read uncommitted Begin Tran Update customer set CustomerName='Changed' where CustomerCode='1001' WAITFOR DELAY '000:00:20' rollback tran set transaction isolation level read uncommitted select * from Customer where CustomerCode='1001'
解决方案5:使用重复读解决丢失更新和非重复读
给重复读设置隔离级别后,其他人就不能读取和更新数据,关于重复读隔离级别的关键点包含:
• 当为查询设置重复事务隔离级别时,只读取已提交的数据。
• 当你使用重复读选择一条记录时,其它事务将不能更新该条记录,但查询是可以的。
• 如果在更新查询中设置了可重复事务,必须要等到事务完成才能读和更新相同的记录。
• 当选择和更新查询被设置为可重复读,其它事务可以插入新记录,换句话说就是虚幻行是可能的。
如果你想测试这个隔离级别,执行下面的语句,然后尝试查询和更新查询,它们都将被阻止,50秒后你才能看到数据。
set transaction isolation level repeatable read Begin Tran Update customer set CustomerName='Changed' where CustomerCode='1001' WAITFOR DELAY '000:00:50' rollback tran
如果在重复读模式下执行下面的查询语句,在50秒内你啥也干不了,直到事务完成后你才能得到查询结果。
set transaction isolation level repeatable read begin tran select * from Customer where CustomerCode='1001' WAITFOR DELAY '000:00:50' commit tran
注意,在此期间你可以添加CustomerCode=’1001’的新记录,换句话说就是虚幻行是可能的。
解决方案6:使用序列化隔离级别解决虚幻行问题
这是最高级的隔离级别,在此期间,其它事务是不能更新,查询和插入记录的,关于序列化事务的一些关键点包含:
• 当隔离级别是序列化时,没有其它事务可以插入,更新,删除或查询。
• 会出现许多阻塞,但所有并发性问题都能得到解决。