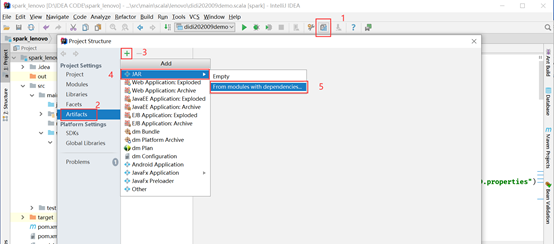
(1)添加pom.xml中的依赖包
注意依赖包必须跟cdh中的组件版本一致。附上cdh3.2.1版的pom.xml内容:
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>spark_lenovo</groupId> <artifactId>spark</artifactId> <version>1.0-SNAPSHOT</version> <properties> <project.build.sourceEncoding>UTF-8</project.build.sourceEncoding> <maven.compiler.source>1.8</maven.compiler.source> <maven.compiler.target>1.8</maven.compiler.target> <spark.scala.version>2.11</spark.scala.version> <spark.version>2.4.0</spark.version> <hadoop.version>3.0.0-cdh6.3.2</hadoop.version> <hbase.version>2.1.0-cdh6.3.2</hbase.version> <jar.scope>compile</jar.scope> </properties> <dependencies> <!--spark--> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_${spark.scala.version}</artifactId> <version>${spark.version}</version> <scope>${jar.scope}</scope> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_${spark.scala.version}</artifactId> <version>${spark.version}</version> <scope>${jar.scope}</scope> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-hive_${spark.scala.version}</artifactId> <version>${spark.version}</version> <scope>${jar.scope}</scope> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_${spark.scala.version}</artifactId> <version>${spark.version}</version> <scope>${jar.scope}</scope> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-mllib_${spark.scala.version}</artifactId> <version>${spark.version}</version> <scope>${jar.scope}</scope> </dependency> <dependency> <groupId>org.apache.hadoop</groupId> <artifactId>hadoop-client</artifactId> <version>${hadoop.version}</version> <scope>${jar.scope}</scope> </dependency> <!--mysql jdbc驱动 --> <dependency> <groupId>mysql</groupId> <artifactId>mysql-connector-java</artifactId> <version>6.0.5</version> </dependency> <!-- <dependency>--> <!-- <groupId>mysql</groupId>--> <!-- <artifactId>mysql-connector-java</artifactId>--> <!-- <version>5.1.39</version>--> <!-- </dependency>--> <!-- <dependency>--> <!-- <groupId>junit</groupId>--> <!-- <artifactId>junit</artifactId>--> <!-- <version>4.12</version>--> <!-- </dependency>--> <!--hbase--> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase</artifactId> <version>${hbase.version}</version> </dependency> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-server</artifactId> <version>${hbase.version}</version> </dependency> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-client</artifactId> <version>${hbase.version}</version> </dependency> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-common</artifactId> <version>${hbase.version}</version> </dependency> <dependency> <groupId>org.apache.hbase</groupId> <artifactId>hbase-mapreduce</artifactId> <version>${hbase.version}</version> </dependency> </dependencies> <build> <plugins> <!-- 编译scala的插件 --> <plugin> <groupId>net.alchim31.maven</groupId> <artifactId>scala-maven-plugin</artifactId> <version>3.2.2</version> <executions> <execution> <goals> <goal>compile</goal> </goals> </execution> </executions> </plugin> <!-- 编译java的插件 --> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-compiler-plugin</artifactId> <version>3.5.1</version> <configuration> <source>1.8</source> <target>1.8</target> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-shade-plugin</artifactId> <version>2.4.1</version> <executions> <execution> <phase>package</phase> <goals> <goal>shade</goal> </goals> <configuration> <filters> <filter> <artifact>*:*</artifact> <excludes> <exclude>META-INF/*.SF</exclude> <exclude>META-INF/*.DSA</exclude> <exclude>META-INF/*.RSA</exclude> </excludes> </filter> </filters> <transformers> <transformer implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer"> <resource>META-INF/spring.handlers</resource> </transformer> <transformer implementation="org.apache.maven.plugins.shade.resource.AppendingTransformer"> <resource>META-INF/spring.schemas</resource> </transformer> <transformer implementation="org.apache.maven.plugins.shade.resource.ManifestResourceTransformer"> <mainClass>${groupId}.com.bigdata.CellPhoneToHbase</mainClass> </transformer> </transformers> <createDependencyReducedPom>false</createDependencyReducedPom> </configuration> </execution> </executions> </plugin> </plugins> </build> <repositories> <!-- 由于hadoop版本是cdh的,所以需要添加cdh仓库--> <repository> <id>cloudera</id> <name>cloudera</name> <url>https://repository.cloudera.com/artifactory/cloudera-repos</url> </repository> </repositories> </project>
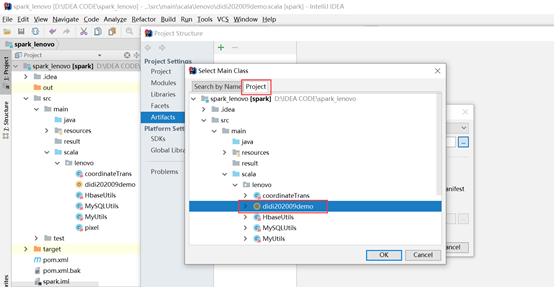
(2)打包
A. 编译


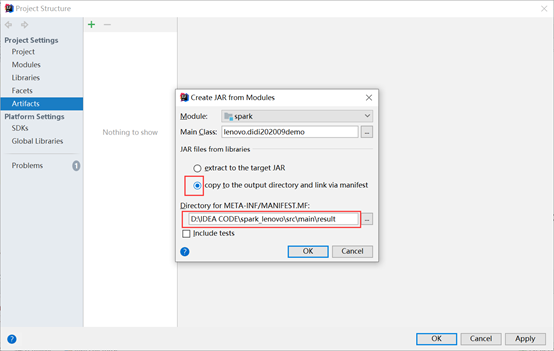
这里选择extract to the target JAR就是将所有的依赖包也都一并打包了;如果选择copy to the output…就只打包自己写的文件。
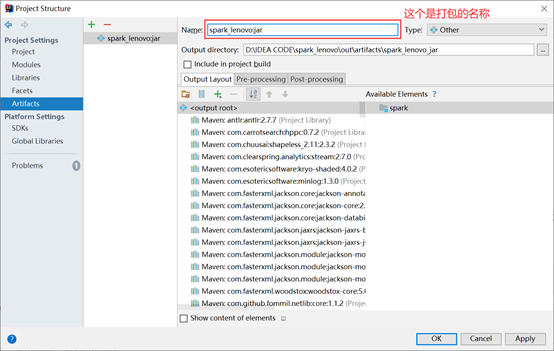
如果选择extract to the target JAR就会出现以下内容:

否则会出现以下内容:
B. 构建

在弹出的选择框中点击build
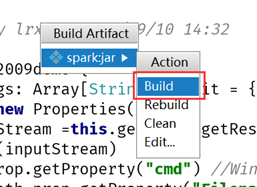
C. 查看
打包前是这样:

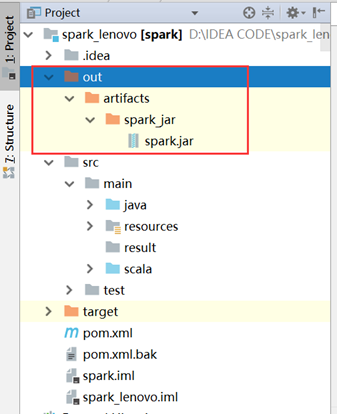
打包后是这样:
如果选择extract to the target JAR就会出现以下内容:
否则会出现以下内容:
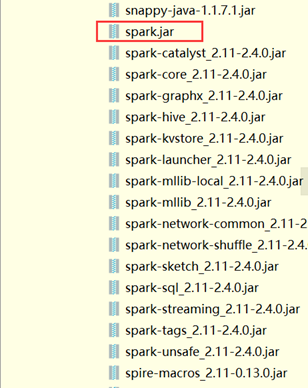

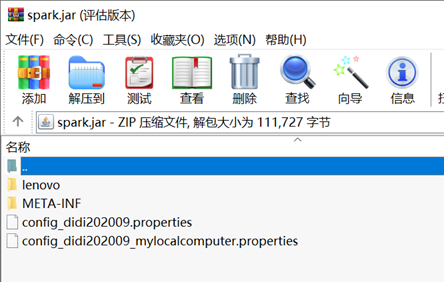
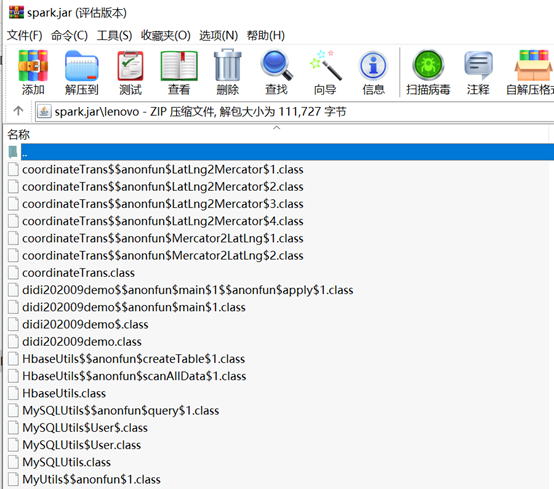
使用解压软件打开jar包,可以看到里面的内容:

(3)执行jar包
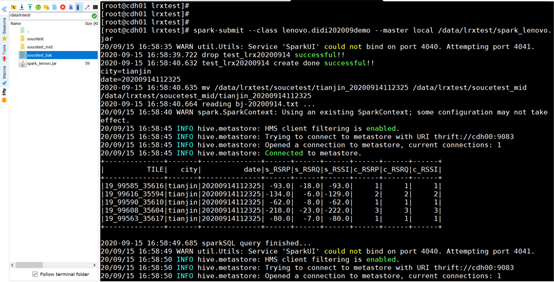
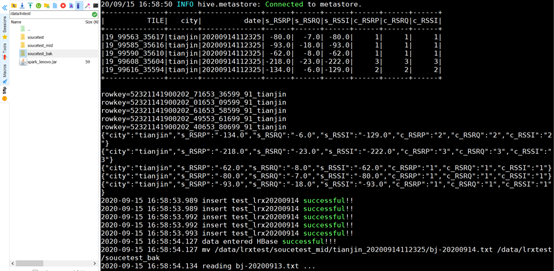
上传jar包至Linux的其中一台spark节点服务器上
执行命令:
spark-submit --class lenovo.didi202009demo --master local /data/lrxtest/spark.jar
(4)Q&A
A. org.apache.hadoop.mapred.InvalidInputException: Input path does not exist: hdfs://Master11:9000/user
在写spark 读取本地文件命令的时候报hdfs上文件不存在的错…
读取文件是分两种情况:
(首先要确保文件路径写对了!!!!!)
1. 如果读取hdfs上的文件时报这个错,那么去看hdfs上是否有这个文件!!
hdfs dfs -ls / ( / 后面写要读取的文件的路径)
1
如果没有那么就创建文件,或者把本地文件上传到hdfs上:
上传本地文件:
hdfs dfs -put /usr/local/spark/test.txt /user/
创建文件:
hdfs dfs -mkdir -p /user/test/
2. 如果读取的是本地文件,那么就好好看看命令,读取本地文件的时候文件路径前面要加 file:
我出错就是因为没加file: 这个单词
错误的命令:
scala> sc.textFile("/usr/local/spark/test.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect
准确的命令:
sc.textFile("file:/usr/local/spark/test.txt").flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).collect