一、概念
使用BlukLoad方式利用Hbase的数据信息是 按照特点格式存储在HDFS里的特性,直接在HDFS中生成持久化的Hfile数据格式文件,然后完成巨量数据快速入库的操作,配合MapReduce完成这样的操作。
二、优点
1、不占用Region资源
2、不会产生巨量的写入I/O、
3、只需要较少的CPU和网络资源
三、实现原理
通过一个MapReduce Job来实现的,通过job直接生成一个Hbase的内部HFile格式文件 ,用来形成一个特殊的Hbase数据表,然后直接将数据文件加载到运行的集群中,与使用Hbase API相比,使用BulkLoad导入数据占用更少的CPU和网络资源
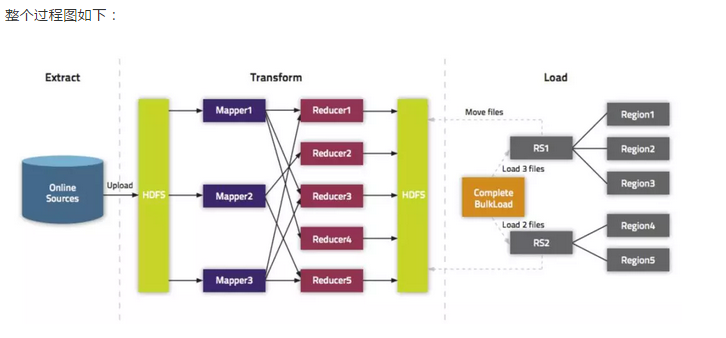
四、BulkLoad过程主要包括三部分:
1、从数据源(通常是文本文件或其他的数据库)提取数据并上传到HDFS,抽取数据到HDFS和Hbase。
2、利用MapReduce作业处理事先准备的数据,并且大多数情况下需要我们自己编写Map函数,而Reduce函数不需要我们考虑,由Hbase提供。
该作业需要使用rowkey(行键)作为输出key;keyvalue、put或者delete作为输出value。MapReduce作业需要使用HFileOutputFormat2
来生成Hbase数据文件。为了有效的导入数据,需要配置HFileOutputFormat2使得每一个输出文件都在一个合适的区域中。为达到这个目的,
MapReduce作业会使用Hadoop的TotalOrderPartitioner类根据表的key值将输出分割开来。HFileOutputFormat2的方法configureIncrementalLoad()
会自动的完成上面的工作。
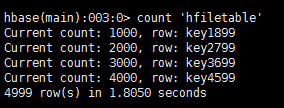
3、告诉RegionServers数据的位置并导入数据,通常使用LoadIncrementalHFiles(更为人所知是completebulkload工具),将文件在HDFS上的位置传递给它,它会利用RegionServer将数据导入到相应的区域
五、实践操作(kerberos认证)
1、创建表
create 'hfiletable','fm1','fm2'
2、数据准备
**
* @Author: xiaolaotou
* @Date: 2018/11/29
*/
public class CreateData {
public static void main(String[] args) throws IOException, InterruptedException {
StringBuffer str = new StringBuffer();
String rowkey="key";
String family1="fm1:name";
String family2="fm2:age";
String value="za";
Integer age=12;
for(int i=1;i<5000;i++) {
str=str.append(rowkey + i + " " + family1 + " " + value+i + "
" + rowkey+i + " " + family2 + " " +i+"
");
System.out.println(str);
}
//写入本地文件
String fileTxt="/mnt/sata1/yang/BulkLoadHbase/data.txt";
File file=new File(fileTxt);
if(!file.getParentFile().exists()){
file.getParentFile().mkdirs();
}
if(!file.exists()){
file.createNewFile();
FileWriter fw=new FileWriter(file,false);
BufferedWriter bw=new BufferedWriter(fw);
System.out.println("写入完成");
bw.write(String.valueOf(str));
bw.flush();
bw.close();
fw.close();
}
PutDataToHdfs();
}
//将数据文件上传到hdfs
public static void PutDataToHdfs() throws IOException, InterruptedException {
Configuration conf = new Configuration();
FileSystem fs = org.apache.hadoop.fs.FileSystem.get(URI.create("hdfs://172.20.237.104:9000"),conf,"root");
//上传文件到hdfs
fs.copyFromLocalFile(new Path("/mnt/sata1/yang/BulkLoadHbase/data.txt"),new Path("/yang"));
}
}
注意:在hdfs开启kerberos认证这个将数据上传到hdfs不能用,采用生成数据手动上传

3、使用Mapreduce将数据通过Bulkload入到hbase表中
/**
* @Author: xiaolaotou
* @Date: 2018/11/27
* 使用MapReduce生成HFile文件
*/
public class BulkLoadMapper extends Mapper<LongWritable,Text,ImmutableBytesWritable,Put> {
public void map(LongWritable key, Text value, Mapper.Context context) throws IOException, InterruptedException {
String[] valueStrSplit = value.toString().split(" ");//划分一行数据
String hkey = valueStrSplit[0];//rowkey
String family = valueStrSplit[1].split(":")[0];//列族
String column = valueStrSplit[1].split(":")[1];//字段
String hvalue = valueStrSplit[2];//值
final byte[] rowKey = Bytes.toBytes(hkey);
final ImmutableBytesWritable HKey = new ImmutableBytesWritable(rowKey);
Put HPut = new Put(rowKey);
byte[] cell = Bytes.toBytes(hvalue);
HPut.add(Bytes.toBytes(family), Bytes.toBytes(column), cell);
context.write(HKey, HPut);
}
/**
* @Author: xiaolaotou
* @Date: 2018/11/27
*/
public class BulkLoadJob {
static Logger logger = LoggerFactory.getLogger(BulkLoadJob.class);
private static Configuration conf = null;
static {
Configuration HBASE_CONFIG = new Configuration();
HBASE_CONFIG.set("hbase.zookeeper.quorum", "172.20.237.104,172.20.237.105,172.20.237.106");
HBASE_CONFIG.set("hbase.master.kerberos.principal", "hbase/_HOST@TDH");
HBASE_CONFIG.set("hbase.regionserver.kerberos.principal", "hbase/_HOST@TDH");
HBASE_CONFIG.set("hbase.security.authentication", "kerberos");
HBASE_CONFIG.set("zookeeper.znode.parent", "/hyperbase1");
HBASE_CONFIG.set("hadoop.security.authentication", "kerberos");
conf = HBaseConfiguration.create(HBASE_CONFIG);
}
public static void main(String[] args) throws Exception {
UserGroupInformation.setConfiguration(conf);
UserGroupInformation.loginUserFromKeytab("hbase/gz237-104", "/etc/hyperbase1/conf/hyperbase.keytab");
String inputPath = "/yang/data.txt";
String outputPath = "/yang/BulkLoad";
Job job = Job.getInstance(conf, "BulkLoadToHbase");
job.setJarByClass(BulkLoadJob.class);
job.setMapperClass(BulkLoadMapper.class);
job.setMapOutputKeyClass(ImmutableBytesWritable.class);
job.setMapOutputValueClass(Put.class);
//拒绝推测式task的运行
job.setSpeculativeExecution(false);
job.setReduceSpeculativeExecution(false);
//in/out format
job.setInputFormatClass(TextInputFormat.class);
job.setOutputFormatClass(HFileOutputFormat2.class);
//指定来源
FileInputFormat.addInputPath(job, new Path(inputPath));
//指定输出地
FileOutputFormat.setOutputPath(job, new Path(outputPath));
HTable table = new HTable(conf, "hfiletable");
HFileOutputFormat2.configureIncrementalLoad(job, table);
boolean b = job.waitForCompletion(true);
if (b) {
FsShell shell = new FsShell(conf);
try {
shell.run(new String[]{"-chmod", "-R", "777", outputPath});
} catch (Exception e) {
logger.error("不能改变文件权限 ", e);
throw new IOException(e);
}
//加载到hbase表
LoadIncrementalHFiles loader = new LoadIncrementalHFiles(conf);
loader.doBulkLoad(new Path(outputPath), table);
System.out.println("执行成功");
} else {
System.out.println("执行失败");
logger.error("加载失败!");
System.exit(1);
}
}
}
过程中遇到的报错:
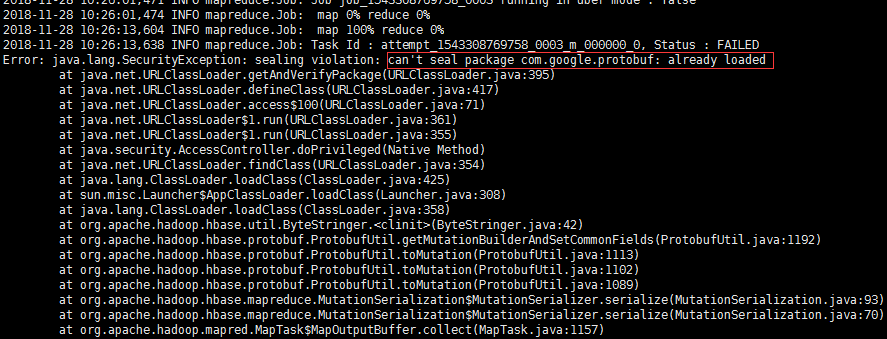
解决:protobuf-java-2.5.0.jar因为包冲突,由于我创建project时,结构为父模块和子模块,可能在导包的时候,被其他子模块的包给冲突了。因此,我新建了一个project重新打包到linux运行成功。