主要配置
bind 0.0.0.0 #bind 默认情况下,Sentinel不能从不同的接口访问localhost,(默认只监听127.0.0.1),可以使用'bind'指令绑定到网络列表接口
protected-mode no #禁用保护模式
daemonize yes #是否以守护进程的方式启动
port 26379 #默认比redis端口的大20000
dir "/data/redis/sentinel_26379" #工作目录 自定义目录先创建
logfile "/data/redis/logs/sentinel_26379.log" #日志 自定义文件先创建
sentinel monitor mymaster 10.16.134.65 6379 2 #指定sentinel监控某个master。并且如果master进入O_DOWN 状态,至少需要<quorum> 个 sentinel 同意。注意,无论ODOWN quorum 数是多少,一个sentinel需要被大多数已知的sentinel选举才能开始故障迁移,所以不能在少数sentinel选举的情况下执行故障切换。slave 是自动发现的,因此不需要在配置文件中明确指定。sentinel发现slave后会自动重写配置文件。需要注意的是,当一个slave提升为master时,sentinel配置也会被重写
sentinel down-after-milliseconds mymaster 30000 #多少毫秒内,master 不可达就会被sentinel 认为是进入了 S_DOWN 状态。如果服务器在给定的毫秒数之内,没有返回Sentinel发送的PING命令的回复,或者返回一个错误,那么Sentinel将这个服务器标记为主观下线(subjectively down,简称SDOWN)。默认是30s
sentinel parallel-syncs mymaster 1 #这个配置项指定了在发生failover主备切换时最多可以有多少个slave同时对新的master进行 同步,这个数字越小,完成failover所需的时间就越长,但是如果这个数字越大,就意味着越 多的slave因为replication而不可用。可以通过将这个值设为 1 来保证每次只有一个slave 处于不能处理命令请求的状态。
sentinel failover-timeout mymaster 180000 #如果在多少毫秒内没有把宕掉的那台Master恢复,那Sentinel认为这是一次真正的宕机。在下一次选取时排除该宕掉的Master作为可用的节点,然后等待一定的设定值的毫秒数后再来探测该节点是否恢复,如果恢复就把它作为一台Slave加入Sentinel监测节点群,并在下一次切换时为他分配一个”选取号”。默认是3分钟
cat sentinel.conf |grep -v "#" | grep -v "^$" > sentinel_26379.conf
启动sentinel
[root@localhost bin]# /usr/local/redis/bin/redis-sentinel /usr/local/redis/sentinel_26379.conf
[root@localhost bin]# ps -ef |grep redis
root 2474 1 0 10:18 ? 00:00:34 /usr/local/redis/bin/redis-server 0.0.0.0:6379
root 18255 1820 0 14:25 pts/0 00:00:00 ./redis-cli
root 26125 1 6 15:10 ? 00:00:00 /usr/local/redis/bin/redis-sentinel 0.0.0.0:26379 [sentinel]
root 26226 19663 0 15:10 pts/1 00:00:00 grep redis
[root@localhost redis]# cat sentinel_26379.conf #配置文件发生改变
port 26379
daemonize yes
bind 0.0.0.0
protected-mode no
pidfile "/var/run/redis-sentinel.pid"
logfile "/data/redis/logs/sentinel_26379.log"
dir "/data/redis/sentinel_26379"
sentinel myid 2e39c78f08bf6ff52d1fba99a5e86577f840c40a
sentinel deny-scripts-reconfig yes
sentinel monitor mymaster 10.16.134.65 6379 2
sentinel config-epoch mymaster 0
sentinel leader-epoch mymaster 0
# Generated by CONFIG REWRITE
maxmemory 3gb
sentinel known-replica mymaster 10.16.134.75 6379
sentinel known-replica mymaster 10.16.134.85 6379
sentinel current-epoch 0
故障转移测试
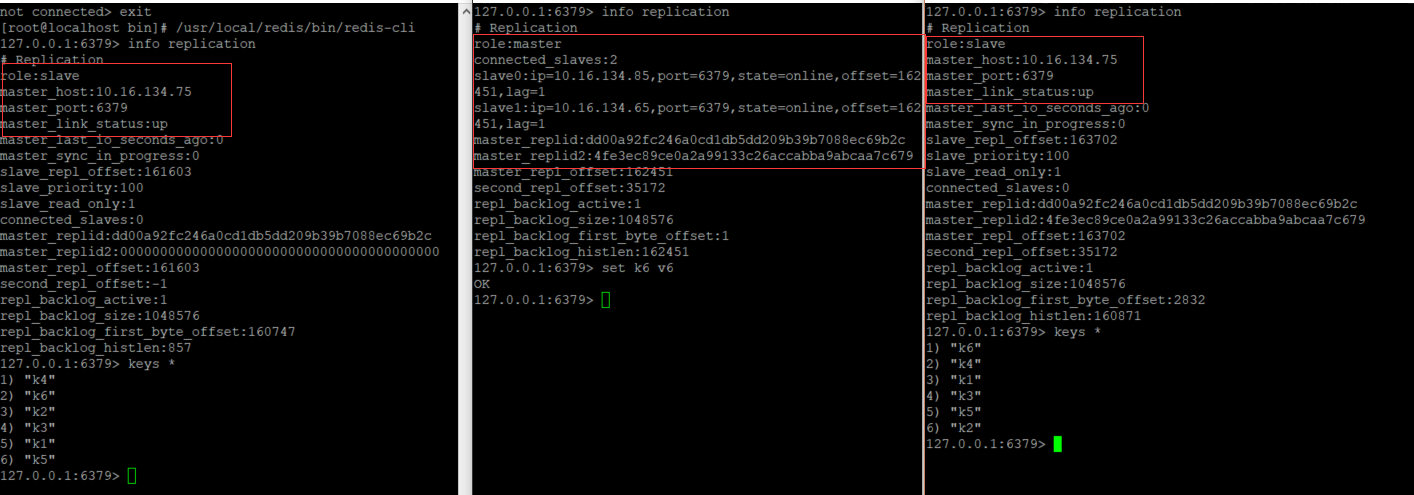
正常运行一主两从

master宕机 *从机配置 protected-mode no 开启,不然salve无法切换*

原来的master恢复变成slave
三个定时任务
1)每10秒每个sentinel对master和slave执行info
2)每2秒每个sentinel通过master节点的channel交换信息(pub/sub)
-
通过_sentinel_:hello频道交换
-
交换对节点的"看法"和自身信息
3)每1秒每个sentinel对其他sentinel和redis执行ping
主观下线和客官下线
sentinel monitor mymaster 10.16.134.65 6379 2 #指定sentinel监控某个master。并且如果master进入O_DOWN 状态,至少需要<quorum> 个 sentinel 同意。注意,无论ODOWN quorum 数是多少,一个sentinel需要被大多数已知的sentinel选举才能开始故障迁移,所以不能在少数sentinel选举的情况下执行故障切换。slave 是自动发现的,因此不需要在配置文件中明确指定。sentinel发现slave后会自动重写配置文件。需要注意的是,当一个slave提升为master时,sentinel配置也会被重写
sentinel down-after-milliseconds mymaster 30000 #多少毫秒内,master 不可达就会被sentinel 认为是进入了 S_DOWN 状态。如果服务器在给定的毫秒数之内,没有返回Sentinel发送的PING命令的回复,或者返回一个错误,那么Sentinel将这个服务器标记为主观下线(subjectively down,简称SDOWN)。默认是30s
-
主观下线 : 每个sentinel节点对redis节点失败的"偏见"
-
客观下线 : 所有sentinel节点对redis节点失败"达成共识" (超过quorum个统一 *建议三个节点设置为2,超过3个节点设置为 节点数/2+1*)
领导者选举
原因 : 只有一个sentinel节点完成故障转移
选举 : 通过sentinel is-master-down-by-addr命令都希望成为领导者
-
每个做主观下线的sentinel节点向其他sentinel节点发送命令,要求将它设置为领导者
-
收到命令的sentinel节点如果没有同意其他sentinel节点发送的命令,那么将同意该请求,否则拒绝
-
如果该sentinel节点发现自己的票数已经超过sentinel集合半数且超过quorum,那么它将成为领导者
-
如果此过程中有多个sentinel节点成为领导者,那么将等待一段时间重新进行选举
故障转移
-
在salve节点中选出一个"合适的"节点作为新的master节点
-
对上面的slave节点执行slaveof no one命令让其成为master节点
-
想剩余的slave节点发送命令,让它们成为新master节点的slave节点,复制规则和parallel-syncs参数相关
-
更新对原来master节点配置为slave,并保持对其"关注",当其恢复后命令它去复制新的master节点
选择"合适的"slave节点
-
选择slave-priority(slave节点优先级)最高的slave节点,如果存在则返回,不存在则继续 *默认不配置,除非slave有一台配置好的,希望master宕机后由这台成为master*
-
选择复制偏移量最大的slave节点(复制的相对完整),如果存在则返回,不存在则继续
-
选择runId最小的slave节点(启动最早的)