机架感知实战案例
作者:尹正杰
版权声明:原创作品,谢绝转载!否则将追究法律责任。
一.网络拓扑与机架感知概述
1>.网络拓扑概述
有可能你会问,在本地网络中,两个节点被称为“彼此近邻”是什么意思?在海量数据处理中,其主要限制因素是节点之间传输的传输速率,即带宽很稀缺。这里的想法是将两个节点间的带宽作为距离的衡量标准。
不用衡量节点之间的带宽,实际上很难实现(它需要一个稳定的集群,并且在集群中两两节点对数量是节点数量的平方),Hadoop为此采用了一个简单的想法:把网络看作一棵树,凉凉节点间的距离是它们刀最近共同祖先的距离总和。该树种的层次是没有预先设定的,但是相对于数据中心,机架和正在运行的节点,通常可以设定等级。具体想法是针对以下每个场景,可用带宽依次递减: (1)同一个节点上的进程; (2)同一个机架上不同的节点; (3)同一个数据中心中不同机架上的节点; (4)不同数据中心的节点;
例如,假设又数据中心d1机架和r1中的节点n1。该节点可以表示为“/d1/r1/n1”。利用这种标记,这里给出四种距离描述: (1)distance(/d1/r1/n1,/d1/r1/n1) = 0(同一节点上的进程) (2)distance(/d1/r1/n1,/d1/r1/n2) = 2(同一个机架上不同的节点) (3)distance(/d1/r1/n1,/d1/r1/n3) = 4(同一数据中心不同机架上的节点) (4)distance(/d1/r1/n1,/d1/r1/n4) = 6(不同数据中心的节点)
最后,我们必须意识到Hadoop无法自动发现你的网络拓扑结构。它需要一些帮助(需要实现一些Java定义的接口)。不过默认情况下,假设网络是扁平化的只有一层,或换句话说,所有节点都在同一个数据中心的同一个机架上。规模小(比如集群节点小于20台,均放在同一个机架上)的集群可能如此,不需要进一步配置。

2>.机架感知概述(副本放置策略)
HDFS和YARN都支持机架感知策略(实际上是对交换机的感知),即集群中的节点都有彼此相对的位置这样一个概念。HDFS利用机架感知策略,确保将一个数据块复制到不同机架来实现容错的目的。这样,如果网络被关闭或者整个机架下架,仍然能够对数据进行访问。
ResourceManager利用机架感知策略优化资源的分配,使客户端尽可能访问距离最近的数据。NameNode和ResourceManager守护进程通过调用API(将DNS映射到机架ID)的方式获取机架信息。
在默认三副本备份的情况下,数据块一般存储在两个机架而非三个机架上,这在读取数据时,能够减少网络带宽占用。
如下图所示,展示了Hadoop如何利用机架感知策略,配合不同的机架帮助实现集群的冗余性。因为同一个机架节点间的网络流量相比于不同机架上节点之间的网络流量少,因此配置多个机架是有益的。
如果配置了多个机架,NameNode会尝试将数据复制到多个机架,从而提供更高的容错性。

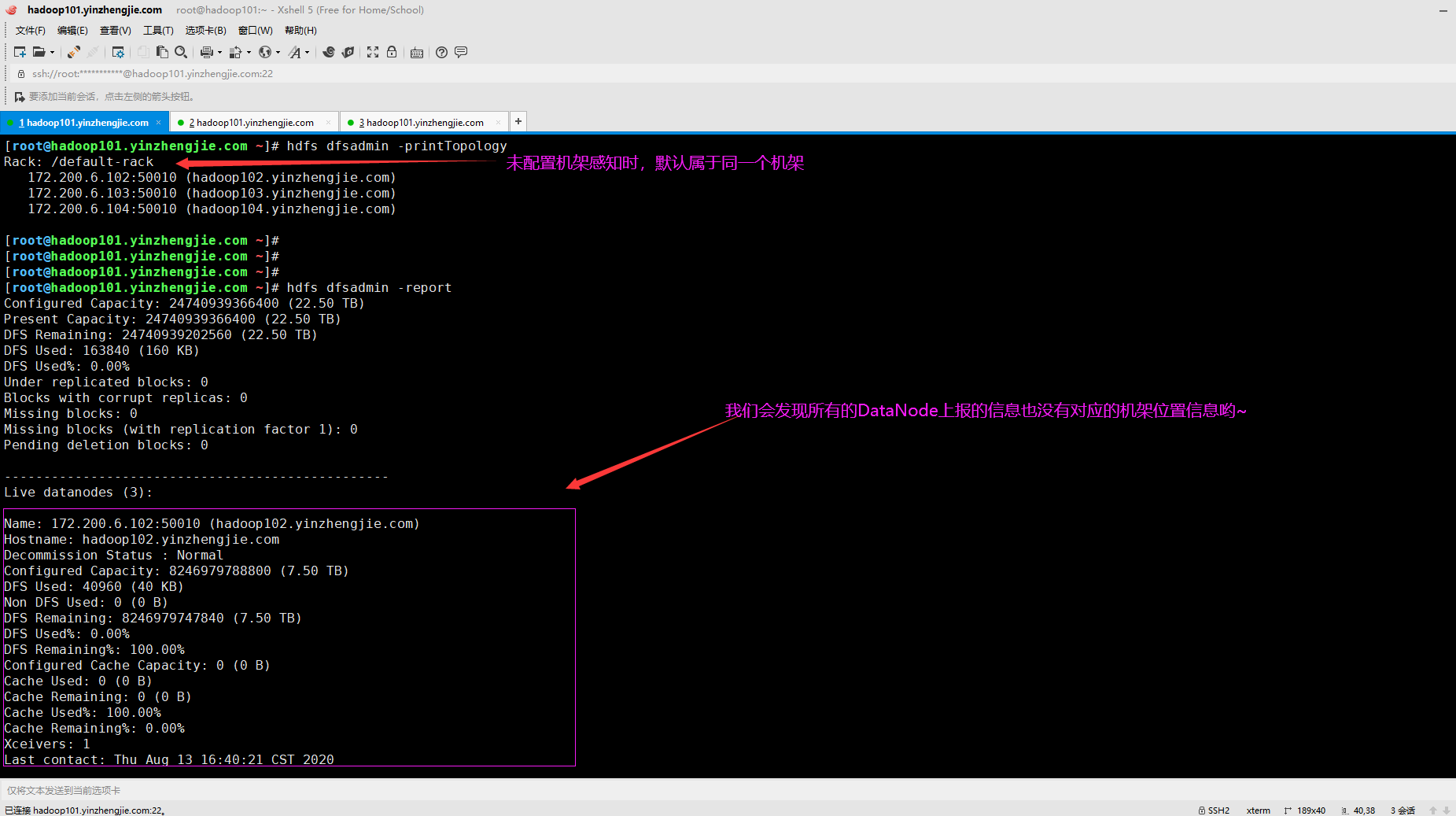
3>.默认情况下,Hadoop集群均在同一个机架"/default-rack"
将Hadoop集群中的节点安排到多个机架是很常见的。默认情况下,即使集群中的节点实际分属于多个机架,Hadoop也会将所有的节点都属于同一个机架。 如下所示,是我新搭建的测试集群,默认情况下均属于同一个机架,即"/default-rack"。 [root@hadoop101.yinzhengjie.com ~]# hdfs dfsadmin -printTopology Rack: /default-rack 172.200.6.102:50010 (hadoop102.yinzhengjie.com) 172.200.6.103:50010 (hadoop103.yinzhengjie.com) 172.200.6.104:50010 (hadoop104.yinzhengjie.com) [root@hadoop101.yinzhengjie.com ~]#
二.基于脚本配置机架感知策略
1>.如何在集群中配置机架感知策略
我们必须意识到Hadoop无法自动发现你的网络拓扑结构。它需要一些帮助比如:需要实现一些Java定义的接口,或者基于脚本的方式定义。
Hadoop提供了以脚本的方式来帮助配置集群的机架感知策略。Hadoop集群通过这个脚本确定节点在机架的位置。该脚本使用一个基本文件的控制文件,可以通过编辑该文件添加集群中节点信息(IP地址)。
执行脚本时,Hadoop会根据机架信息文本中提供的IP地址得到一份机架名称列表。为了让机架感知策略生效,需要修改Hadoop的核心配置文件(core.site.xml)
2>.在NameNode节点配置Hadoop的核心文件(注意参数"net.topology.script.file.name")
[root@hadoop101.yinzhengjie.com ~]# vim ${HADOOP_HOME}/etc/hadoop/core-site.xml [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# cat ${HADOOP_HOME}/etc/hadoop/core-site.xml <?xml version="1.0" encoding="UTF-8"?> <?xml-stylesheet type="text/xsl" href="configuration.xsl"?> <!-- Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with the License. You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0 Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the specific language governing permissions and limitations under the License. See accompanying LICENSE file. --> <!-- Put site-specific property overrides in this file. --> <configuration> <!-- core-site.xml文件中包含核心Hadoop属性的值,可以使用此文件覆盖core-default.xml文件中的默认参数值. --> <property> <name>fs.defaultFS</name> <value>hdfs://hadoop101.yinzhengjie.com:9000</value> <description>指定默认文件系统的名称(这里指定的是hdfs)以及NameNode服务的主机和端口信息,该属性指定集群NameNode的URI。DataNode将使用此URI向NameNode注册,使应用程序可以访问存储在DataNod es上的数据。客户端还将使用此URI来检索HDFS中数据块的位置,通常使用9000端口,但是如果你愿意,可以使用不同的端口(在Hadoop 1.x版本中该属性名称为"fs.default.name",官方宣布该参数已被废弃).</description>
</property>
<property> <name>hadoop.http.staticuser.user</name> <value>yinzhengjie</value> <description>指定HDFS web UI的默认用户名,默认值为"dr.who"(在Hadoop 1.x版本中该属性名称为"dfs.web.ugi",官方宣布该参数已被废弃).</description> </property> <!-- 虽然上面两个参数可以使集群运行,但包括下述这两个配置参数是现阶段更好的选择. --> <property> <name>fs.trash.interval</name> <value>4320</value> <description>指定删除检查点的分钟数,如果为0(官方默认即为0),垃圾箱功能将被禁用。我这里指定了4320分钟(3天),删除文件72小时后,Hadoop会将其从HDFS存储中永久删除.</description> </property> <property> <name>hadoop.tmp.dir</name> <value>/yinzhengjie/data/hadoop/fully-mode/hdfs</value> <description>指定本地文件系统和HDFS中基本临时目录,该配置参数将被其它的配置文件引用(比如hdfs-site.xml我们就会引用"hadoop.tmp.dir"变量),其默认值是"/tmp/hadoop-${user.name}",建议将该 目录设置为"/tmp"以外的目录,因为某些环境会定期运行脚本来清理"/tmp"目录下的所有内容.</description> </property> <!-- 以下参数用于配置机架感知,生产环境中如果大数据集群使用的机架数超过2个以上,建议启动该功能. --> <property> <name>net.topology.script.file.name</name> <value>/yinzhengjie/softwares/hadoop/etc/hadoop/conf/toplogy.py</value> <description>配置机架感知策略文件</description> </property> </configuration> [root@hadoop101.yinzhengjie.com ~]#
3>.编辑主机和机架的对应关系
[root@hadoop101.yinzhengjie.com ~]# vim /yinzhengjie/softwares/hadoop/etc/hadoop/conf/host-rack.txt [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# cat /yinzhengjie/softwares/hadoop/etc/hadoop/conf/host-rack.txt #生产环境中建议你根据实际服务器和对应的机架编号进行命名,我这里仅是为了测试方便。 172.200.6.101,/rack001 172.200.6.102,/rack001 172.200.6.103,/rack002 172.200.6.104,/rack002 172.200.6.105,/rack003 [root@hadoop101.yinzhengjie.com ~]#
4>.编写python脚本并添加执行权限
[root@hadoop101.yinzhengjie.com ~]# mkdir -v ${HADOOP_HOME}/etc/hadoop/conf #创建存放机架感知相关配置文件的目录 mkdir: created directory ‘/yinzhengjie/softwares/hadoop/etc/hadoop/conf’ [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# vim ${HADOOP_HOME}/etc/hadoop/conf/toplogy.py #编辑脚本内容 [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# cat ${HADOOP_HOME}/etc/hadoop/conf/toplogy.py #!/usr/bin/env python #_*_conding:utf-8_*_ #@author :yinzhengjie #blog:http://www.cnblogs.com/yinzhengjie import sys DEFAULT_RACK="/prod/default-rack" HOST_RACK_FILE="/yinzhengjie/softwares/hadoop/etc/hadoop/conf/host-rack.txt" host_rack = {} for line in open(HOST_RACK_FILE): (host,rack) = line.split(",") host_rack[host] = rack for host in sys.argv[1:]: if host in host_rack: print host_rack[host] else: print DEFAULT_RACK [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# ll /yinzhengjie/softwares/hadoop/etc/hadoop/conf/toplogy.py -rw-r--r-- 1 root root 463 Aug 13 18:33 /yinzhengjie/softwares/hadoop/etc/hadoop/conf/toplogy.py [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# chmod +x /yinzhengjie/softwares/hadoop/etc/hadoop/conf/toplogy.py #一定要添加执行权限,否则启动Hadoop集群时会报错权限被拒绝。 [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# ll /yinzhengjie/softwares/hadoop/etc/hadoop/conf/toplogy.py -rwxr-xr-x 1 root root 463 Aug 13 18:33 /yinzhengjie/softwares/hadoop/etc/hadoop/conf/toplogy.py [root@hadoop101.yinzhengjie.com ~]#
4>.重启HDFS集群(无需分发到DataNode节点),并观察日志信息
[root@hadoop101.yinzhengjie.com ~]# manage-hdfs.sh restart hadoop101.yinzhengjie.com | CHANGED | rc=0 >> stopping namenode hadoop105.yinzhengjie.com | CHANGED | rc=0 >> stopping secondarynamenode hadoop104.yinzhengjie.com | CHANGED | rc=0 >> stopping datanode hadoop103.yinzhengjie.com | CHANGED | rc=0 >> stopping datanode hadoop102.yinzhengjie.com | CHANGED | rc=0 >> stopping datanode Stoping HDFS: [ OK ] hadoop101.yinzhengjie.com | CHANGED | rc=0 >> starting namenode, logging to /yinzhengjie/softwares/hadoop-2.10.0-fully-mode/logs/hadoop-root-namenode-hadoop101.yinzhengjie.com.out hadoop105.yinzhengjie.com | CHANGED | rc=0 >> starting secondarynamenode, logging to /yinzhengjie/softwares/hadoop/logs/hadoop-root-secondarynamenode-hadoop105.yinzhengjie.com.out hadoop102.yinzhengjie.com | CHANGED | rc=0 >> starting datanode, logging to /yinzhengjie/softwares/hadoop/logs/hadoop-root-datanode-hadoop102.yinzhengjie.com.out hadoop104.yinzhengjie.com | CHANGED | rc=0 >> starting datanode, logging to /yinzhengjie/softwares/hadoop/logs/hadoop-root-datanode-hadoop104.yinzhengjie.com.out hadoop103.yinzhengjie.com | CHANGED | rc=0 >> starting datanode, logging to /yinzhengjie/softwares/hadoop/logs/hadoop-root-datanode-hadoop103.yinzhengjie.com.out Starting HDFS: [ OK ] [root@hadoop101.yinzhengjie.com ~]#

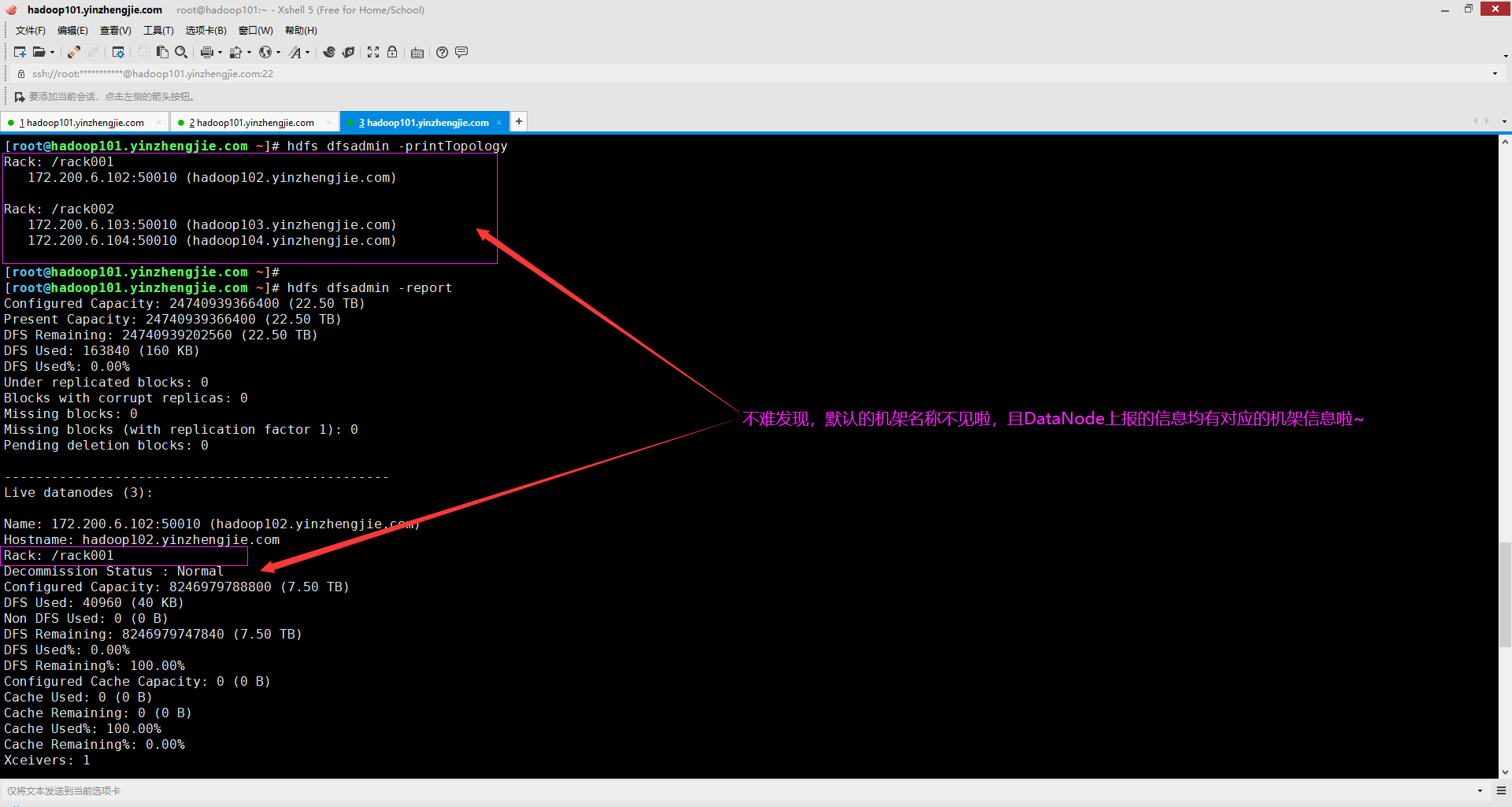
5>. 查看集群的机架信息
[root@hadoop101.yinzhengjie.com ~]# hdfs dfsadmin -printTopology Rack: /rack001 172.200.6.102:50010 (hadoop102.yinzhengjie.com) Rack: /rack002 172.200.6.103:50010 (hadoop103.yinzhengjie.com) 172.200.6.104:50010 (hadoop104.yinzhengjie.com) [root@hadoop101.yinzhengjie.com ~]# [root@hadoop101.yinzhengjie.com ~]# hdfs dfsadmin -report Configured Capacity: 24740939366400 (22.50 TB) Present Capacity: 24740939366400 (22.50 TB) DFS Remaining: 24740939202560 (22.50 TB) DFS Used: 163840 (160 KB) DFS Used%: 0.00% Under replicated blocks: 0 Blocks with corrupt replicas: 0 Missing blocks: 0 Missing blocks (with replication factor 1): 0 Pending deletion blocks: 0 ------------------------------------------------- Live datanodes (3): Name: 172.200.6.102:50010 (hadoop102.yinzhengjie.com) Hostname: hadoop102.yinzhengjie.com Rack: /rack001 Decommission Status : Normal Configured Capacity: 8246979788800 (7.50 TB) DFS Used: 40960 (40 KB) Non DFS Used: 0 (0 B) DFS Remaining: 8246979747840 (7.50 TB) DFS Used%: 0.00% DFS Remaining%: 100.00% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Thu Aug 13 18:44:52 CST 2020 Last Block Report: Thu Aug 13 18:41:01 CST 2020 Name: 172.200.6.103:50010 (hadoop103.yinzhengjie.com) Hostname: hadoop103.yinzhengjie.com Rack: /rack002 Decommission Status : Normal Configured Capacity: 8246979788800 (7.50 TB) DFS Used: 61440 (60 KB) Non DFS Used: 0 (0 B) DFS Remaining: 8246979727360 (7.50 TB) DFS Used%: 0.00% DFS Remaining%: 100.00% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Thu Aug 13 18:44:52 CST 2020 Last Block Report: Thu Aug 13 18:41:01 CST 2020 Name: 172.200.6.104:50010 (hadoop104.yinzhengjie.com) Hostname: hadoop104.yinzhengjie.com Rack: /rack002 Decommission Status : Normal Configured Capacity: 8246979788800 (7.50 TB) DFS Used: 61440 (60 KB) Non DFS Used: 0 (0 B) DFS Remaining: 8246979727360 (7.50 TB) DFS Used%: 0.00% DFS Remaining%: 100.00% Configured Cache Capacity: 0 (0 B) Cache Used: 0 (0 B) Cache Remaining: 0 (0 B) Cache Used%: 100.00% Cache Remaining%: 0.00% Xceivers: 1 Last contact: Thu Aug 13 18:44:52 CST 2020 Last Block Report: Thu Aug 13 18:41:01 CST 2020 [root@hadoop101.yinzhengjie.com ~]#
三.基于自定义代码配置机架感知策略
博主推荐阅读: https://www.cnblogs.com/yinzhengjie/p/9142230.html