本地模式
环境介绍
一共三台测试机
master 192.168.4.91
slave1 192.168.4.45
slave2 192.168.4.96
操作系统配置
1、Centos7操作系统
2、防火墙,selinux都关闭(在学习的时候,基本都是关闭防火墙,生产环境,防火墙都是打开的,不仅有Linux自带的主机防火墙,还有其他的物理防火墙)
*** 以下操作需要root权限 *** (1) Centos7关闭防火墙命令 #systemctl stop firewalld #systemctl disable firewalld Centos6关闭防火墙 #/etc/init.d/iptables stop #chkconfig iptables off (2) 关闭Selinux #sed -i 's/enforcing/disabled/g' /etc/selinux/config 通常情况下,设置完selinux需要重启操作系统,如果不想重启,可以临时关闭selinux。 #setenforce 0 表示临时关闭selinux (3) 修改操作系统ulimit的限制(可以使用ulimit -a参数看当前系统的ulimit限制值) #echo "* - nofile 65535" >> /etc/security/limits.conf 修改最大文件数。 #echo "* - nproc 65535" >> /etc/security/limits.d/20-nproc.conf 修改最大进程数 注意:修改完以后,如果想要生效,需要重新打开会话。 (4) 关闭ipv6 #echo "net.ipv6.conf.all.disable_ipv6 = 1" >> /etc/sysctl.conf #echo "net.ipv6.conf.default.disable_ipv6 = 1" >> /etc/sysctl.conf #sysctl -p (5) 修改/etc/hosts文件,添加主机名和ip的映射 (6) 创建管理集群的用户 #useradd -m -d /home/hadoop hadoop #passwd hadoop #修改密码 (7) 创建数据目录 #mkdir /data/hadoop #chown hadoop:hadoop /data/hadoop #su - hadoop #切换到hadoop用户 (8) 设置主机之间免密登录 #ssh-keygen -t rsa -N '' -f ~/.ssh/id_rsa (在每台机器执行) 拷贝分发秘钥
下载软件包
下载Hadoop:http://www.apache.org/dyn/closer.cgi/hadoop/common/hadoop-2.9.2/hadoop-2.9.2.tar.gz
如果想下载最新版的二进制包,到官网下载。
安装配置JDK和Hadoop
1、安装JDK以及配置环境变量
$ tar zxvf jdk-8u181-linux-x64.tar.gz -C /data/hadoop $ cd /data/hadoop $ ln -s jdk1.8.0_181/ jdk $ vim ~/.bashrc 文件最后追加 export JAVA_HOME=/data1/hadoop/jdk export PATH=${JAVA_HOME}/bin:$PATH $source /etc/profile #让jdk生效 $java -version #查看jdk是否生效,如果输入如下,说明配置成功。 java version "1.8.0_181" Java(TM) SE Runtime Environment (build 1.8.0_181-b13) Java HotSpot(TM) 64-Bit Server VM (build 25.181-b13, mixed mode)
2、安装Hadoop以及配置
解压
$ tar zxvf tar zxvf hadoop-2.9.2.tar.gz -C /data/hadoop/
$ cd /data/hadoop
$ ln -s hadoop-2.9.2/ hadoop
配置环境变量
$ vim ~/.bashrc,追加如下配置
export HADOOP_HOME=/data1/hadoop/hadoop/
export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
$ source ~/.bashrc
3、本地模式下,各个进程运行在一台机器上,占用的jvm进程数为1,在跑MapReduce时,从本地读取文件,输出到本地文件。
(1)、在本地系统创建一个文件
#cat test.txt
11 22 33
22 33 44
44 22 11
运行hadoop自带的MapReduce程序
$ hadoop jar /data/hadoop-2.9.2/share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount test.txt test.out

这里可以看到job ID中有local字样,说明是运行在本地模式下的。
(2)查看输出的文件。在本地模式下,输出文件是在本地。
# ll test.out
输出目录中有_SUCCESS文件说明JOB运行成功;part-r-00000是输出结果文件,r说明是reduce产生的结果,如果是m的话,则是map阶段产生的。
如果要查看具体的信息:
# cat test.out/part-r-00000
伪分布搭建
特点:伪分布模式下,多个进程运行在不同的jvm内
以下配置只在master节点操作
Hadoop配置
1、配置hadoop-env.sh
$ cd /data/hadoop/hadoop/etc/hadoop/
$ echo "export JAVA_HOME=/data/hadoop/jdk" >> hadoop-env.sh
2、配置core-site.xml文件
在<configuration>下面添加 fs.defaultFS参数配置的是HDFS的地址。 <property> <!-- hdfs 地址 --> <name>fs.defaultFS</name> <value>hdfs://master:8020</value> </property> <!-- 指定hadoop临时目录 --> <property> <name>hadoop.tmp.dir</name> <value>/data/hadoop/hadoop/tmp</value> </property> hadoop.tmp.dir 是hdfs文件系统产生数据所存放的临时目录 创建目录: $ mkdir /data/hadoop/hadoop/tmp
3、配置hdfs-site.xml文件
在<configuration>下面添加 <property> <name>dfs.replication</name> #这里指定hdfs产生数据时备份的机器数量,由于只有一台机器,所以为1. <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>/data/hadoop/hadoop/name</value> #指定namenode数据存放的目录 </property> <property> <name>dfs.datanode.data.dir</name> <value>/data/hadoop/hadoop/data</value> #指定datanode数据存放的目录 </property> $ mkdir /data/hadoop/hadoop/name $ mkdir /data/hadoop/hadoop/data
4、接下来格式化hdfs
$ hadoop namenode -format
格式化是对HDFS这个分布式文件系统中的DataNode进行分块,统计所有分块后的初始元数据的存储在NameNode中。
格式化后,查看core-site.xml里hadoop.tmp.dir(本例是/data/hadoop/hadoop/目录)指定的目录下是否有了dfs目录,如果有,说明格式化成功。
$ ll /data/hadoop/hadoop/name/current,以下图片可能目录不正确,我查看的是以前安装的集群信息

fsimage_XXX 是namenode元数据存满以后持久化到磁盘的文件。
fsimage*.md5 是校验文件,校验fsimage的完整性。
seen_txid 是hadoop的版本
$ cat VERSION
namespaceID=271252846 #namenode的唯一id
clusterID=CID-97e864b1-262d-4ce0-93d9-9dd96953ecc5 #集群id
cTime=1533545685716
storageType=NAME_NODE #存储类型
blockpoolID=BP-1051333686-192.168.4.91-1533545685716
layoutVersion=-63
当然,NameNode和DataNode的集群ID应该一致,表明这是一个集群,datenode的id可以到/data/hadoop/hadoop/data 这个目录下查看。
♥ 启动namenode、datanode、SecondaryNameNode
$ hadoop-daemon.sh start namenode $ hadoop-daemon.sh start datanode $ hadoop-daemon.sh start secondarynamenode
使用jps命令查看是否启动成功
$ jps
3022 NameNode
10578 Jps
2099 DateNode
12768 SecondaryNameNode
♥ hdfs分布式文件系统测试
在hdfs上创建目录:
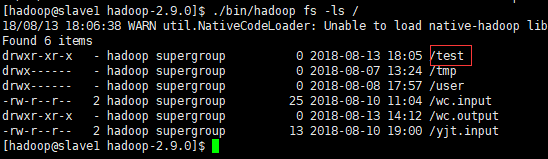
$ hadoop fs -mkdir /test
查看目录:
# 
上传本地文件到hdfs:
$ ./bin/hadoop fs -put wc.input /test
# 
从hdfs分布式文件系统上面下载文件到本地系统
$ ./bin/hadoop fs -get /test/wc.put
5、配置 mapred-site.xml
在 <configuration>下面添加
<!-- 指定mr运行在yarn框架上 --> <property> <name>mapreduce.framework.name</name> <value>yarn</value> </property>
6、配置yarn.site.xml
在 <configuration>下面添加
<property> <name>yarn.nodemanager.aux-services</name> #yarn默认混洗方式 <value>mapreduce_shuffle</value> </property> <property> <name>yarn.resourcemanager.hostname</name> #指定resourcemanager的主机名称 <value>master</value> </property>
♥启动resourcemanager
${HADOOP_HOME}/sbin/yarn-daemon.sh start resourcemanager
♥启动nodemanager
${HADOOP_HOME}/sbin/yarn-daemon.sh start nodemanager
使用jps查看是否启动成功,如果有 resourcemanager nodemanager 则说明成功。
♥ 查看yarn的外部界面,

如果你要在Windows里面通过主机名去访问Linux里面的主机,那么你需要在Windows的hosts主机里面添加Linux主机名和其IP地址的映射关系。
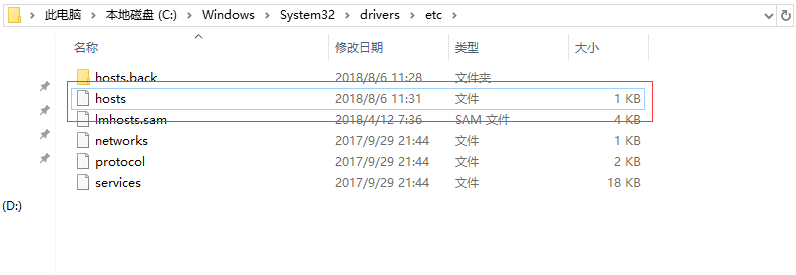

这样才能正常从Windows浏览器通过主机名访问Linux,当然,你直接输入IP地址就不需要这一步了。
有时候你在修改Windows 下的/etc/hosts完成以后,保存时提示没有权限,该怎么做呢:
如图:hosts文件右键——> 安全----->指定users用户,在权限这里,把允许下面的都勾选上。

♥ 允许MapReduce
在本地系统创建测试用的文件
#cat wc.put
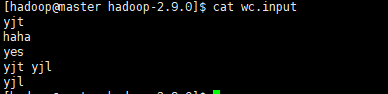
上传到hdfs文件系统
# hadoop fs -put wc.put /
运行Wordcount MapReduce job
$ cd /data/hadoop/hadoop $ hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.9.2.jar wordcount /wc.input /wc.output
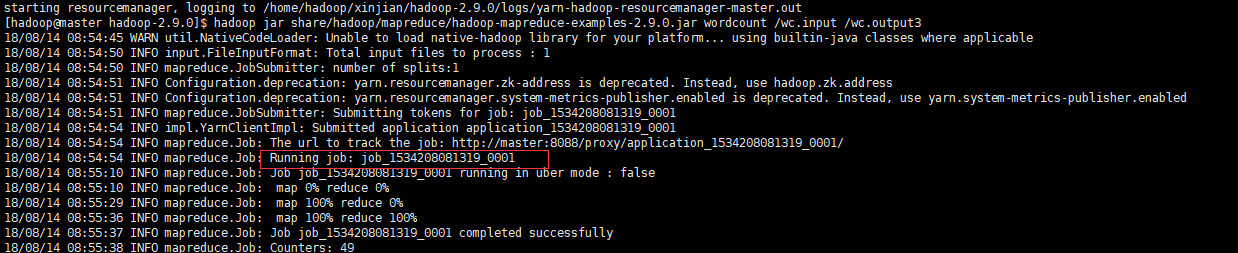
查看输出结果
$ hadoop fs -ls /wc.output/

有SUCCESS就代表这个job执行成功,这是一个空文件;part-r-00000既是输出结果,其中r表示是reduce阶段产生的结果,mapreduce程序执行时,可以没有reduce阶段,但是肯定会有map阶段,如果没有reduce阶段这个地方有是-m-,一个reduce会产生一个part-r-开头的文件。
• 查看结果
# hadoop fs -cat /wc.output/part-r-00000

其结果可以看出来是按照键值排好序的。
♥ 如何停止hadoop?
(1)一个一个进程慢慢停止
$./sbin/hadoop-daemon.sh stop namenode
$./sbin/hadoop-daemon.sh stop datenode
$ ./sbin/yarn-daemon.sh stop resourcemanager
$ ./sbin/yarn-daemon.sh stop nodemanager
(2) hadoop有一个脚本文件,可以直接停止集群,这个脚本文件分开来的话就是停止hdfs和yarn。启动整个集群也可以使用 ./sbin/start-all.sh
#./sbin/stop-all.sh
♥ 各个功能模块的介绍
(1) yarn
这是一个资源调度框架,在hadoop2.x中,主要就是管理整个集群资源的分配和调度,具体请查看 https://blog.csdn.net/liuwenbo0920/article/details/43304243
(2) hdfs
hdfs分布式文件系统主要用来将大文件分块以后进行分布式存储数据的,突破了单台机器磁盘存储限制,这是一个相对独立的模块,能够为yarn、hbase等模块提供服务。
(3)MapReduce
MapReduce是一个计算框架,通过map、reduce阶段来分布式的对数据进行流处理,适用于对数据的流处理,对实时性要求高的应用不太适合,在hadoop1.0中,MapReduce是出于霸主级别,但是在hadoop2.0中,提供了一个更高效的处理引擎--spark。
♥ 如何开启历史服务?
(1) #./sbin/mr-jobhistory-daemon.sh start historyserver
开启以后通过web界面可以查看,点开下图的history,可以查看历史信息。

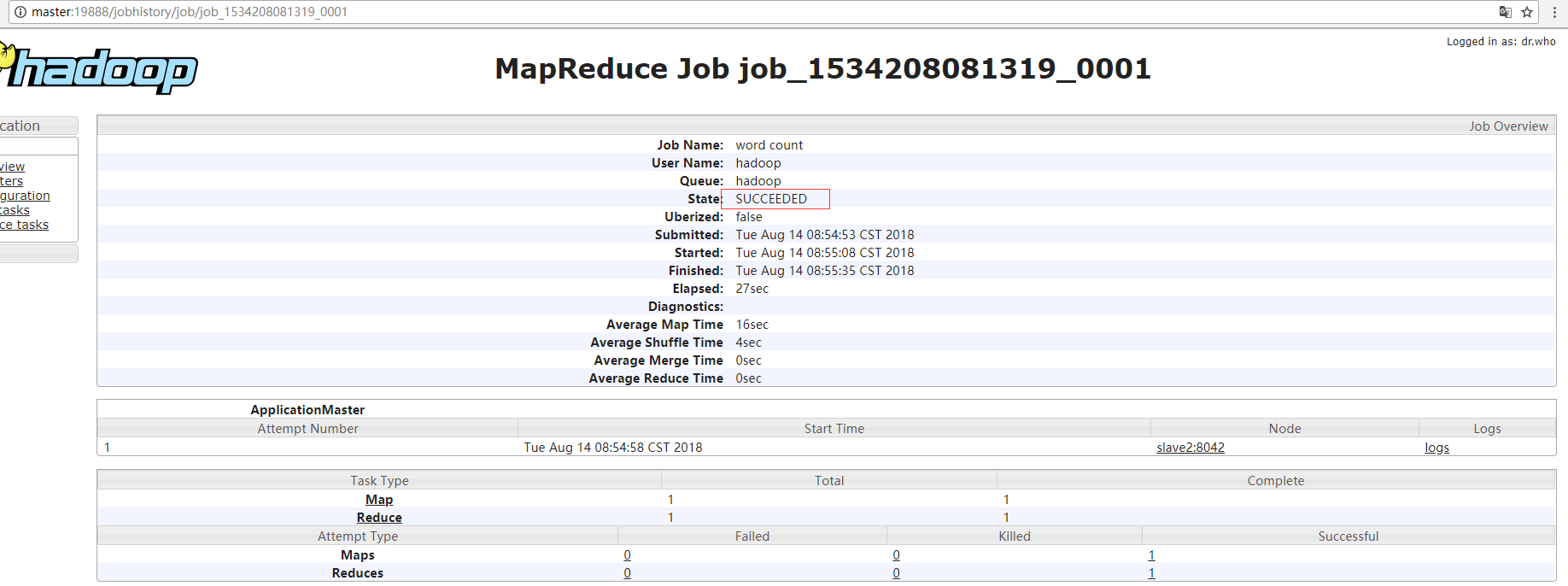
历史服务器的端口是19888.
♥ 如果想在web界面查看日志该如何做呢?那就是开启日志聚集,日志聚集是在yarn框架的,所以在配置的时候是在yarn.site.xml文件里面配置
(1)日志聚集介绍
MapReduce是在各个机器上运行的,在运行过程中产生的日志存在于各个机器上,为了能够统一查看各个机器的运行日志,将日志集中存放在HDFS上,这个过程就是日志聚集。
(2)日志聚集默认是未开启的,通过配置yarn.site.xml来开启。
<property> <name>yarn.log-aggregation-enable</name> # 是否开启日志聚集 <value>true</value> </property> <property> <name>yarn.log-aggregation.retain-seconds</name> #日志保存时间,以秒为单位。 <value>106800</value> </property>
(3)配置完以后重启yarn进程
# stop-yarn.sh
# start-yarn.sh
(4)现在就可以去web界面查看map、reduce阶段产生的日志。
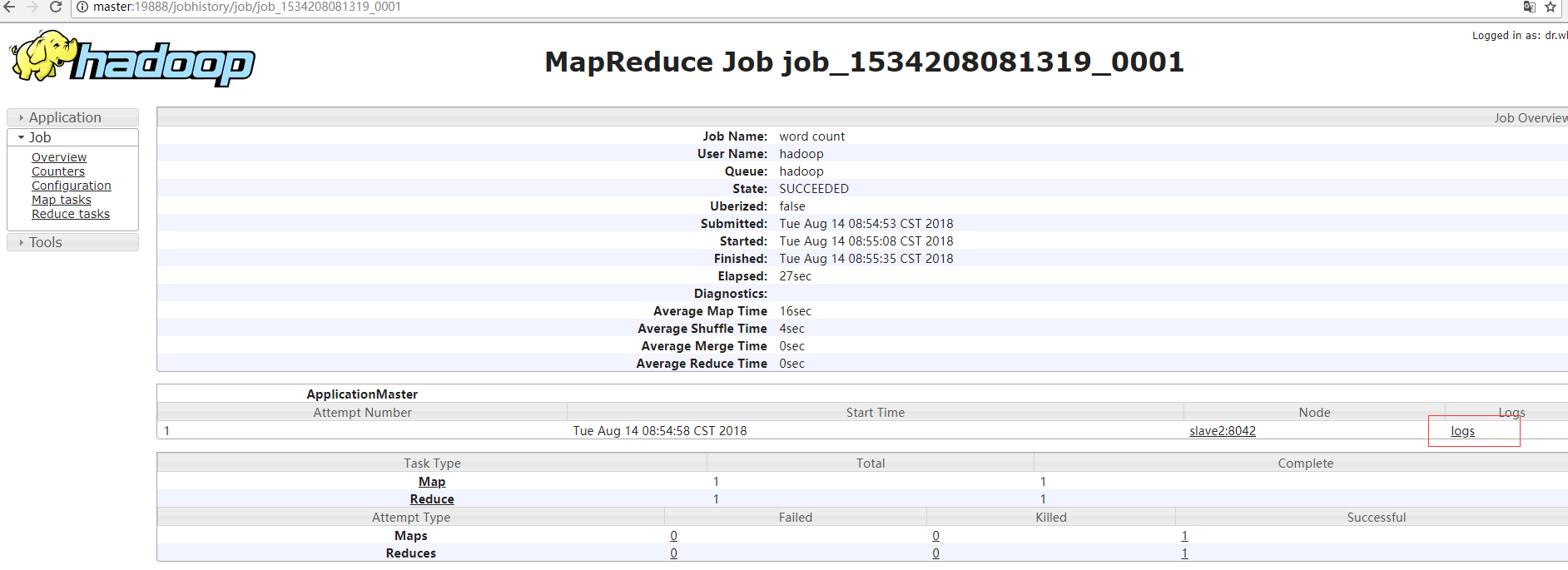
当然,在执行这一步的时候,是因为我们上面刚刚跑过MapReduce程序,如果你没有跑MapReduce,则这个界面不会有这些信息。
如果是在完全分布式或者ha完全分布式集群里面,当配置完成以后,需要把配置文件拷贝到其他节点在重新启动yarn进程。
分布式模式
前提是前面的JDK在三台机器都已经安装好。
1、停止伪分布式模式下搭建的集群
$ stop-all.sh
2、删除伪分布式模式下生成的数据
$ rm -rf /data/hadoop/hadoop/name
$ rm -ff /data/hadoop/hadoop/data
3、修改/data/hadoop/hadoop/etc/hadoop/slaves,添加需要启动的datanode、nodemanagerjied
slave1
slave2
4、分发hadoop到其他机器
$ scp -r /data/hadoop/hadoop slave1:/data/hadoop
$ scp -r /data/hadoop/hadoop slave2:/data/hadoop
5、启动集群
$ start-all.sh