一、Netty介绍
- Netty是由JBOSS提供的一个java开源框架
- Netty是一个异步的、基于事件驱动的网络应用框架,用以快速开发高性能‘高可靠性的网络IO程序
- Netty主要针对在TCP协议下,面向Clients端的高并发应用,或者Peer-to-Peer场景下的大量数据持续传输的应用
- Netty本质是一个NIO框架,适用于服务器通讯相关的多种应用场景
- 要透彻理解Netty,需要先学习NIO。
二、IO模型
IO模型简单理解,就是用什么样的通道进行数据的发送和接收,很大程度上决定了程序通信的性能。
Java共支持3种网络编程模型IO模式:BIO、NIO、AIO
- Java BIO:同步并阻塞(传统阻塞型),服务器实现模式为一个连接一个线程,即客户端有连接请求时服务器端就需要启动一个线程进行处理,如果这个连接不做任何事情会造成不必要的线程开销。
- Java NIO:同步非阻塞,服务器实现模式为一个线程处理多个请求(连接),即客户端发送的连接请求都会注册到多路复用器上,多路复用器轮询到连接有IO请求就进行处理
- Java AIO(NIO.2):异步非阻塞,AIO引入异步通道的概念,采用了Proactor模式,简化了程序编写,有效的请求才启动线程,它的特点是先由操作系统完成后才通知服务端程序启动线程去处理,一般适用于连接数较多且连接时间较长的应用。
三种模式适用场景
- BIO适用于连接数目比较小且固定的架构,这种方式对服务器资源要求比较高,并发局限于应用中,JDK1.4以前的唯一选择,但程序简单易理解。
- NIO适用于连接数目多且连接比较短的架构,比如聊天服务器,弹幕系统,服务器间通讯等。编程比较复杂,JDK1.4开始支持。
- AIO适用于连接数目多且连接比较长的架构,比如相册服务器,充分调用OS参与并发操作,编程比较复杂,JDK7开始支持。
三、NIO与零拷贝
- 零拷贝是网络编程的关键,很多性能优化都离不开。
- 在Java程序中,常用的零拷贝有mmap(内存映射)和sendFile
- 零拷贝是指没有cpu拷贝
mmap优化
- mmap通过内存映射,将文件映射到内核缓冲区,同时,用户空间可以共享内核空间的数据。这样,在进行网络传输时,就可以减少内核空间到用户控件的拷贝。
sendFile优化
- Linux2.1版本提供了sendFile函数,其基本原理为:数据根本不经过用户态,直接从内核缓冲区进入到SocketBuffer,同时,由于和用户态完全无关,就减少了一次上下文切换。
- linux在2.4版本中,做了一些修改,避免了从内核缓冲区拷贝到SocketBuffer的操作,直接拷贝到协议栈,从而再一次减少了数据拷贝
mmap和sendFile的区别
- mmap适合小数据量读写,sendFile适合大文件传输。
- mmap需要4次上下文切换,3次数据拷贝;sendFile需要3次上下文切换,最少2次数据拷贝。
- sendFile可以利用DMA方式,减少CPU拷贝,mmap则不能(必须从内核拷贝到Socket缓冲区)
四、线程模型
- 不同的线程模型,对程序的性能有很大的影响。
- 目前存在的线程模型有:
- 传统阻塞I/O服务模型
- Reactor模式
- 根据Reactor的数量和处理资源池线程的数量不同,有3中典型的实现
- 单Reactor单线程
- 单Reactor多线程
- 主从Reactor多线程
- Netty线程模式(Netty主要基于主从Reactor多线程模型做了一定的改进,其中主从Reactor多线程模型有多个Reactor)
Reactor模式
Reactor对应的叫法:1.反应器模式 2.分发者模式 3.通知者模式
- 基于I/O复用模型:多个连接共用一个阻塞对象,应用程序只需要在一个阻塞对象等待,无需阻塞等待所有连接。当某个连接有新的数据可以处理时,操作系统通知应用程序,线程从阻塞状态返回,开始进行业务处理。
- 基于线程池复用线程资源:不必再为每个连接创建线程,将连接完成后的业务处理任务分配给线程进行处理,一个线程可以处理多个连接的业务。
Reactor模式中核心组成:
- Reactor:Reactor在一个单独的线程中运行,负责监听和分发事件,分发给适当的处理程序来对IO事件做出反应。它就像公司的电话接线员,它接听来自客户的电话并将线路转移到适当的联系人。
- Handlers:处理程序执行I/O事件要完成的实际事件,类似于客户想要与之交谈的公司的实际官员。Reactor通过调度适当的处理程序来响应I/O事件,处理程序执行非阻塞操作。
单Reactor单线程
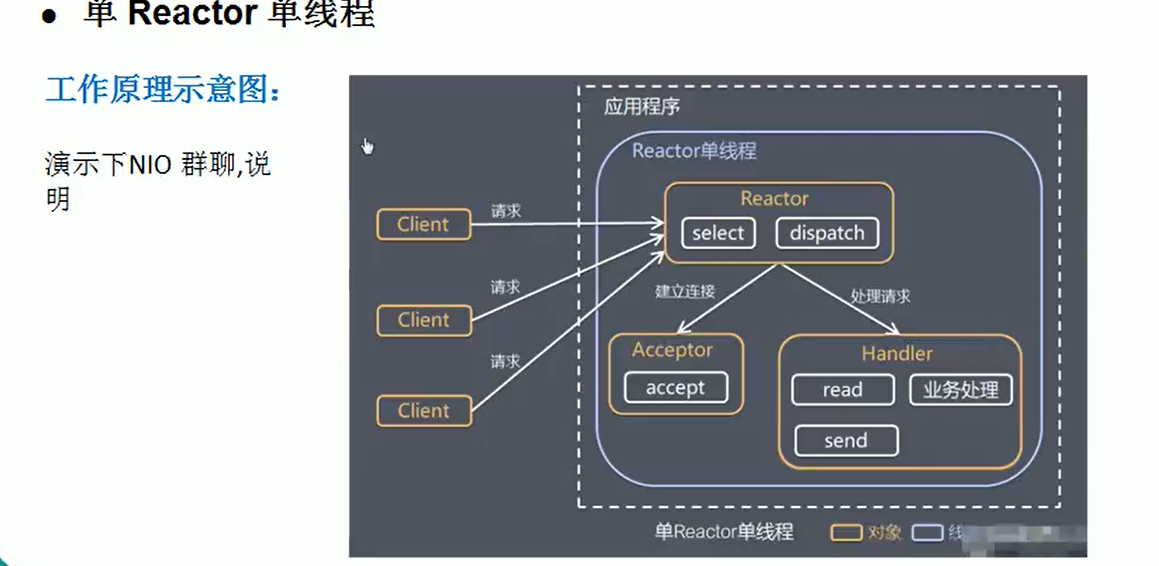
- Select是前面I/O复用模型介绍额标准网络编程API,可以实现应用程序通过一个阻塞对象监听多路连接请求
- Reactor对象通过Select监控客户端请求事件,受到事件后通过Dispatch进行分发
- 如果是建立连接请求事件,则由Acceptor通过Accept处理连接请求,然后创建一个Handler对象处理连接完成后的后续业务处理。
- 如果不是简介事件,则Reactor会分发调用连接对应的Handler来响应
- Handler会完成Read-》业务处理-》Send的完整业务流程。
优缺点:
- 优点:模型简单,没有多线程、进程通信、竞争问题,全部都在一个线程中完成。
- 缺点:性能问题,只有一个线程,无法发挥多核CPU性能。Handler在处理某个连接上的业务时,整个进程无法处理其他连接事件,很容易导致性能瓶颈。
- 缺点:可靠性问题,线程意外终止,或者进入死循环,会导致整个系统通信模块不可用,不能接受和处理外部消息,造成节点故障。
单Reactor多线程
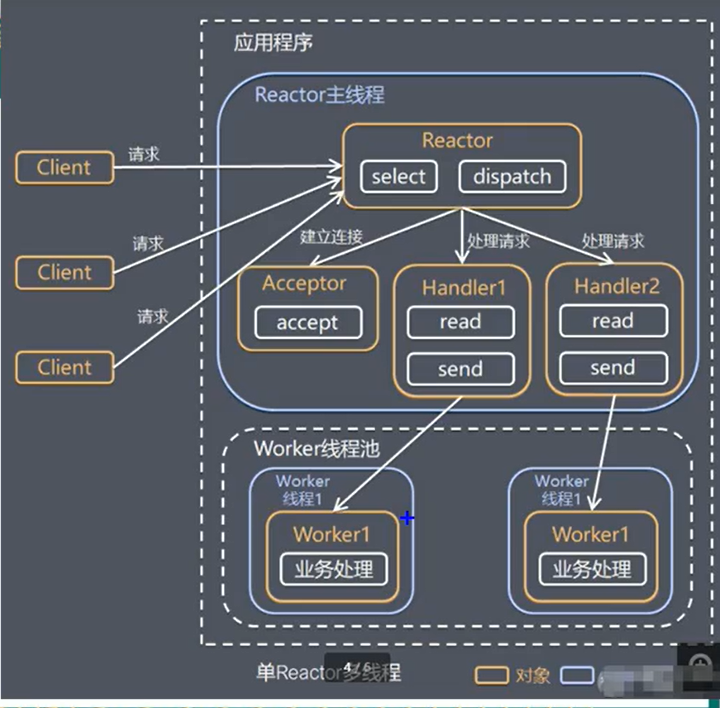
handler只负责响应事件,不做具体的业务处理,会分发给后面的worker线程池的某个线程处理。
优缺点:
- 优点:可以充分利用多核CPU性能
- 缺点:多线程数据共享和访问比较复杂,reactor处理所有的事件的监听和响应,在单线程运行,在高并发场景容易出现瓶颈。
主从Reactor多线程
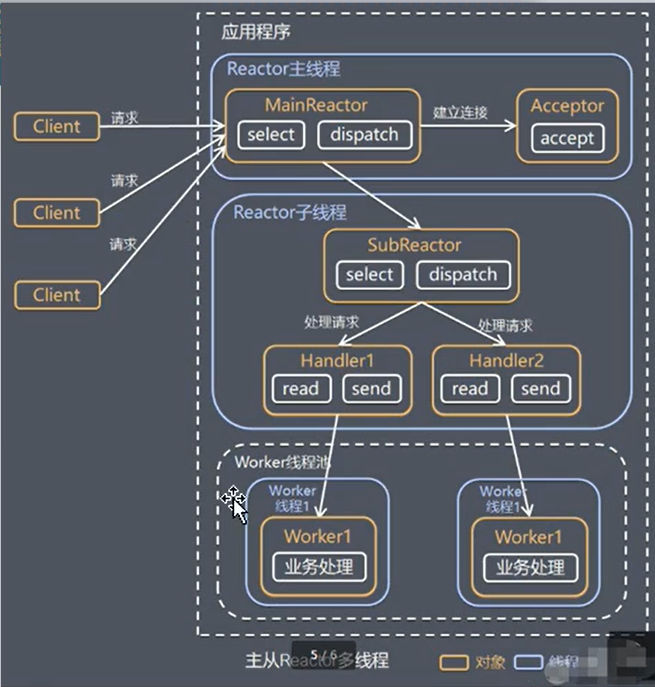
优缺点:
- 优点:父线程与子线程的数据交互简单职责明确,父线程只需要接收新连接,子线程完成后续业务处理
- 优点:父线程与子线程的数据交互简单,Reactor主线程只需要把新连接传给子线程,子线程无需返回数据。
- 缺点:编程复杂度较高。
Netty模型
Netty主要基于主从Reactors多线程模型。
- BossGroup线程维护Selector,只关注Accept
- 当接收到Accept事件,获取到对应的SocketChannel,封装成NIOSocketChannel并注册到Workder线程(事件循环),并进行维护
- 当Worker线程监听到selector中通道发生自己感兴趣的事件后,就进行处理(交由handler),注意handler已经加入到通道。
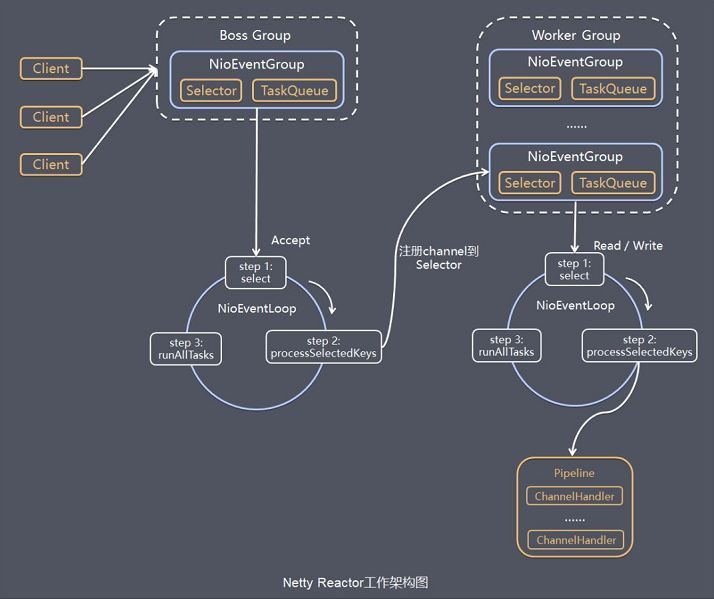
- Netty抽象出两组线程池BossGroup专门负责接收客户端的连接,WorkerGroup专门负责网络的读写。
- BossGroup和WorkerGroup类型都是NioEventLoopGroup
- NioEventLoopGroup相当于一个事件循环组,这个组中含有多个事件循环,每一个事件循环是NioEventLoop
- NioEventLoop表示一个不断循环的执行处理任务的线程,每个NioEvenLoop都有一个selector,用于监听绑定在其上的socket的网络通讯
- NioEventLoopGroup可以有多个线程,即可以含有多个NioEventLoop
- 每个Boss NioEventLoop循环执行的步骤有三步
- 轮询accept事件
- 处理accept事件,与client建立连接,生成NioSocketChannel,并将其注册到某个worker NioEventLoop上的selector
- 处理任务队列的任务,即runAllTasks
- 每个worker NioEventLoop循环执行的步骤
- 轮询read,write事件
- 处理I/O事件,即read,write事件在对应NioSocketChannel处理
- 处理任务队列的任务,即runAllTasks
- 每个Worker NioEventLoop处理业务时,会使用pipeline,pipeline中包含了channel,即通过pipeline可以获取到对应通道。管道中维护了很多处理器。
方案再说明
- Netty抽象出两组线程池,BossGroup专门负责接收客户端连接,WorkerGroup专门负责网络读写操作。
- NioEventLoop表示一个不断循环执行处理任务的线程,每个NioEventLoop都有一个selector,用于监听绑定在其上的socket网络通道。
- NioEventLoop内部采用串行化设计,从消息的读取-》编码-》发送,始终由IO线程NioEventLoop负责
- NioEventLoopGroup下包含多个NioEventLoop
- 每个NioEventLoop中包含有一个Selector,一个taskQueue
- 每个NioEventLoop的Selector上可以注册监听多个NioChannel
- 每个NioChannel只会绑定在唯一的NioEventLoop上
- 每个NioChannel都绑定有一个自己的ChannelPipeline
五、异步模型
- 异步的概念和同步相对。当一个异步过程调用发出后,调用者不能立刻得到结果。实际处理这个调用的组件在完成后,通过状态、通知和回调来通知调用者。
- Netty中的I/O操作是异步的,包括Bind、Write、Connect等操作会简单的返回一个ChannelFuture。
- 调用者并不能立即获得结果,而是通过Future-Listener机制,用户可以方便的主动获取或者通过通知机制获取IO操作结果
- Netty的异步模型是建立在future和callback之上的。重点说Future,它的核心思想是:假设一个方法fun,计算过程可能非常耗时,等待fun返回显然不合适。那么可以在调用fun的时候,立马返回一个future,后序可以通过Future去监控方法fun的处理过程(即:Future-Listener机制)
Future-Listener机制
- 当Future对象刚刚创建时,处于非完成状态,调用者可以通过返回的ChannelFuture来获取操作执行的状态,注册监听函数来执行完成后的操作。
- 常见如下操作:
- 通过isDone方法来判断当前操作是否完成
- 通过isSuccess方法来判断已完成的当前操作是否成功。
- 通过getCause方法来获取当前操作失败的原因
- 通过isCancelled方法来判断已完成的当前操作是否被取消
- 通过addListener方法来注册监听器,当操作已完成(isDone方法返回完成),将会通知指定的监听器;如果Future对象已完成,则通知指定的监听器
六、核心模块
Bootstap、ServerBootstrap
- BootStrap意思是引导,一个Netty应用通常由一个Bootstrap开始,主要作用是配置整个Netty程序,串联各个组件,Netty中Bootstrap类是客户端程序的启动引导类,ServerBootstrap是服务端启动引导类。
- 常见方法有:
- public ServerBootstrap group(EventLoopGroup parentGroup, EventLoopGroup childGroup),该方法用于服务器端,用来设置两个EventLoop
- public B group(EventLoopGroup group),该方法用于客户端,用来设置一个EventLoop
- public B channel(Class<? extends C> channelClass),该方法用来设置一个服务器端的通道实现
- public
B option(ChannelOption option, T value) ,用来给ServerChannel添加配置 - public
ServerBootstrap childOption(ChannelOption childOption, T value),用来给接收到的通道添加配置 - public ServerBootstrap childHandler(ChannelHandler childHandler),该方法用来设置业务处理类(自定义handler)
- public ChannelFuture bind(int inetPort),该方法应用于服务器端,用来设置占用的端口号
- public ChannelFuture connect(String inetHost,int inetPort),该方法用于客户端,用来连接服务器
Future、ChannelFuture
- Netty中所有IO操作都是异步的,不能立刻得知是否被正确处理。但是可以过一会等它执行完成或直接注册一个监听,具体的实现就是通过Future和ChannelFutures,他们可以注册一个监听,当操作执行成功或失败时监听会自动触发注册的监听事件。
- 常用方法:
- Channel channel(),返回当前正在进行IO操作的通道
- ChannelFuture sync(),等待异步操作执行完毕
Selector
- Netty基于Selector对象实现I/O多路复用,通过Selector一个线程可以监听多个连接的Channel事件。
- 当向一个Selector中注册Channel后,Selector内部的机制就可以自动不断地查询(select)这些注册的Channel是否有已经就绪的I/O事件,这样程序就可以简单地使用一个线程高效地管理多个Channel
ChannelHandler及其实现类
- ChannelHandler是一个接口,处理I/O事件或拦截I/O操作,并将其转发到其ChannelPipeline中的下一个处理程序。
- ChannelHandler本身并没有提供很多方法,因为这个接口有许多的方法需要实现,方便调用期间,可以继承它的子类。
ChannelPipeline
- ChannelPipeline是一个Handler的集合,它负责处理和拦截inbound或者outbound的事件和操作,相当于一个贯穿Netty的链(可以这样理解:ChannelPipeline是保存ChannelHandler的List,用于处理或拦截Channel的入站事件和出站操作)
- ChannelPipeline实现了一种高级形式的拦截过滤器模式,使用户可以完全控制事件的处理方式,以及Channel中各个的ChannelHandler如何相互交互
- 在Netty中每个Channel都有且只有一个ChannelPipeline与之对应。
- 一个Channel包含一个ChannelPipeline,而ChannelPipeline中又维护了一个由ChannelHandlerContext组成的双向链表,并且每个ChannelHandlerContext中又关联着一个ChannelHandler
- 入站事件和出站事件在一个双向链表中,入站事件会从链表head往后传递到最后一个入站的handler,出站事件会从链表tail往前传递到最前一个出站的handler,两种类型的handler互不干扰。
ChannelHandlerContext
- 保存Channel相关的所有上下文信息,同时关联一个ChannelHandler对象
- 即ChannelHandlerContext中包含一个具体的事件处理器ChannelHandler,同时ChannelHandlerContext中也绑定了对应的pipeline和Channel的信息,方便对ChannelHandler进行调用
- 常用方法:
- ChannelFuture close(),关闭通道
- ChannelOutboundInvoker flush(),刷新
- ChannelFuture writeAndFlush(Object msg),将数据写到ChannelPipeline中当前ChannnelHandler的下一个ChannelHandler开始处理
ChannelOption
- Netty在创建Channel实例后,一般都需要设置ChannelOption参数
- 参数如下:
- ChannelOption.SO_BACKLOG:对应TCP/IP协议listen函数中的backlog参数,用来初始化服务器可连接队列大小。服务端处理客户端连接请求是顺序处理的,所以同一时间只能处理一个客户端连接。多个客户端来的时候,服务端将不能处理的客户端连接请求放在队列中等待处理,backlog参数指定了队列的大小
- ChannelOption.SO_KEEPALIVE:一直保持连接活动状态
EventLoopGroup和其实现类NioEventLoopGroup
- EventLoopGroup是一组EventLoop的抽象,Netty为了更好的利用多核CPU资源,一般会有多个EventLoop同时工作,每个EventLoop维护者一个Selector实例。
- EventLoopGroup提供next接口,可以从组里面按照一定规则获取其中一个EventLoop来处理任务。在Netty服务器端编程中,我们一般都需要提供两个EventLoopGroup,例如:BossEventLoopGroup和WorkerEventLoopGroup
- 通常一个服务端口即一个ServerSocketChannel对应一个Selector和一个EventLoop线程。BossEventLoop负责接收客户端的连接并将SocketChannel交给WorkerEventLoopGroup来进行IO处理
Unpooled类
- 是Netty提供的一个专门用来操作缓冲区(即Netty的数据容器)的工具类
- 常用方法如下
- public static ByteBuf copiedBuffer(CharSequence string, Charset charset)。
心跳检测机制
Netty通过IdleStateHandler来处理空闲状态。
/**
* IdleStateHandler:Netty提供的处理空闲状态的处理器
* long readerIdleTime:表示多长时间没有读,就会发送一个心跳检测包检测是否连接
* long writerIdleTime:表示多长时间没有写,就会发送一个心跳检测包检测是否连接
* long allIdleTime:表示多长时间没有读写,就会发送一个心跳检测包检测是否连接
* IdleStateEvent触发后,就会传递给管道的下一个handler去处理,通过调用下一个handler的userEventTriggered,在该方法中处理
*/
public IdleStateHandler(
long readerIdleTime, long writerIdleTime, long allIdleTime,
TimeUnit unit) {
this(false, readerIdleTime, writerIdleTime, allIdleTime, unit);
}
pipeline.addLast(new IdleStateHandler(3,5,7, TimeUnit.SECONDS));
通过WebSocket编程实现服务器和客户端长连接
protected void initChannel(SocketChannel ch) throws Exception {
ChannelPipeline pipeline = ch.pipeline();
//基于http协议,使用http编码和解码器
pipeline.addLast(new HttpServerCodec());
//以块方式写,添加ChunkedWriteHandler处理器
pipeline.addLast(new ChunkedWriteHandler());
/**
* http数据在传输的过程中是分段,HttpObejctAggregator,可以将多个段聚合
*/
pipeline.addLast(new HttpObjectAggregator(8192));
/**
* websocket的数据以帧(frame)形式传递
* 浏览器请求时ws://localhost:9999/hello 表示请求的uri
* WebSocketServerProtocolHandler 核心功能是将http协议升级为ws协议,保持长连接
*/
pipeline.addLast(new WebSocketServerProtocolHandler("/hello"));
七、Google Protobuf
在编写网络应用程序时,因为数据在网络中传输的都是二进制字节码数据,在发送数据时就需要编码,接收数据时需要解码。
netty本身也提供了一些解编码器,但是底层使用的仍是java序列化技术,而java序列化技术本身效率就不高,,存在以下问题:
- 无法跨语言
- 序列化后的体积太大,是二进制编码的5倍多
- 序列化性能太低。
使用protobuf进行结构化数据传输
先编写Student.proto文件
syntax = "proto3"; //版本
option java_outer_classname = "StudentPOJO";//生成的类名,同时也是文件名
//protobuf使用message管理数据
message Student{ //会在StudentPOJO外部内生成一个内部类Student,它是真正发送的POJO对象
int32 id = 1; //Student类中有一个属性名字为id,类型为int32,protobuf的类型,在不同语言中对应的类型不同
// 1表示序号,不是值
string name = 2;
}
再进行编译生成java文件
protoc --java_out=. Student.proto
将生成的文件加入到项目中,并且在服务端和客户端都需要配置对应的编码器和解码器
pipeline.addLast("encoder",new ProtobufEncoder());
ch.pipeline().addLast("decoder",new ProtobufDecoder(StudentPOJO.Student.getDefaultInstance()))
构造对象的方式
StudentPOJO.Student student = StudentPOJO.Student.newBuilder().setId(4).setName("xxx").build();
ctx.writeAndFlush(student);
八、handler的调用机制
- ChannelHandler充当了处理入站和出站数据的应用逻辑的容器。例如,实现ChannelInboundHandler接口(或ChannelInboudHandlerAdapter),你就可以接收入站事件和数据,这些数据会被业务逻辑处理。当要给客户端发送响应时,也可以从ChannelInboundHandler冲刷数据。业务逻辑通常写在一个或者多个ChannelInboundHandler中。ChannelOutboundHandler原理一样,只不过它是用来处理出站数据的。
- ChannelPipeline提供了ChannelHandler链的容器。以客户端应用程序为例,如果事件的运动方向是从pipeline到socket,那么我们称这些事件为出站的,即客户端发送给服务端的数据会通过pipeline中的一系列ChannelOutboundHandler,并被这些Handler处理,反之则称为入站的。
九、TCP粘包拆包原理
- TCP是面向连接的,面向流的,提供高可用性服务。收发两端(客户端和服务端)都要有一一成对的socket,因此,发送端为了将多个发给接收端的包,更为有效的发给对方,使用了优化方案(Nagle算法),将多次间隔较小且数据量小的数据,合并成一个大的数据块,然后进行封包。这样做虽然提高了效率,但是接收端就难于分辨成完整的数据包了,因为面向流的通信是无消息保护边界的。
- 由于TCP无消息保护边界,需要在接收端处理消息边界问题,也就是我们所说的粘包、拆包问题
解决方案
- 使用自定义协议+编解码器来解决
- 关键就是要解决服务器每次读取数据长度的问题,这个问题解决,就不会出现服务器多读或少读数据的问题,从而避免的TCP粘包、拆包问题