首先我们要了解:
1.MysqlDumpSlow是 mysql官方提供的慢查询日志分析工具。
2.慢查询日志记录的是记录执行时长超过阈值(即配置文件中long_query_time的值,这个值我们可以根据项目的情况自行定义)的sql语句日志。
一、在使用MysqlDumpSlow工具之前的准备工作:
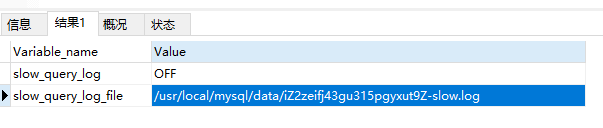
1.查询是否开启慢查询日志及日志文件的目录
show variables like '%slow_query_log%';
结果如下:默认的慢查询日志是关闭状态。(推荐:需要调优的时候才将此功能打开,日常使用会加大对mysql服务的压力。)
2.开启慢查询并设置阈值
set global slow_query_log=1;#开启慢查询,如果已开启可忽略
show variables like 'long_query_time%'; #查询慢查询的阈值,如果不满足需求,可以自行更改
set global long_query_time=3; #设置慢查询阈值,根据需求调整
3.补充:调优也可将没有使用索引的sql语句加入到日志中
show variables like 'log_queries_not_using_indexes'; #查询是否开启此功能 set global log_queries_not_using_indexes=1;#开启将未使用索引的sql写入日志功能
二、MysqlDumpSlow工具的使用
1.操作命令
1 /path/mysqldumpslow -s c -t 10 /database/mysql/slow-log
这会输出记录次数最多的10条SQL语句。
其中:
1 -s, 是sort的意思,表示按照何种方式排序,c、t、l、r分别是按照记录次数、时间、查询时间、返回的记录数来排序,ac、at、al、ar,表示相应的倒序; 2 -t, 是top n的意思,即为返回前面多少条的数据; 3 -g, 是grep的意思,后边可以写一个正则匹配模式,大小写不敏感的;
比如:
1 /path/mysqldumpslow -s r -t 10 /database/mysql/slow-log 2 得到返回记录集最多的10个查询。 3 /path/mysqldumpslow -s t -t 10 -g “left join” /database/mysql/slow-log 4 得到按照时间排序的前10条里面含有左连接的查询语句。
输出图表如下:
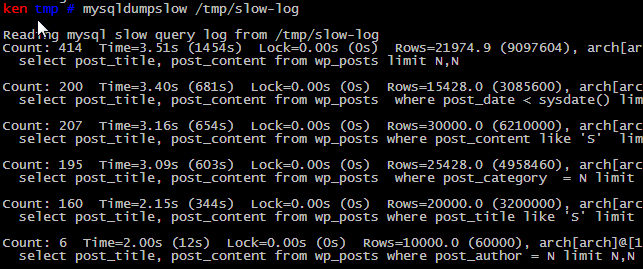
字段:
出现次数(Count), 执行最长时间(Time), 累计总耗费时间(Time), 等待锁的时间(Lock), 发送给客户端的行总数(Rows), 扫描的行总数(Rows), 用户以及sql语句本身(抽象了一下格式, 比如 limit 1, 20 用 limit N,N 表示).