优化excel_utils 类
代码地址:https://gitee.com/todayisgoodday/PythonRequest
- 优化excel_utils
上一章节我们说到了读取excel文件数据,并且处理合并单元格的数据,这节课我们优化一下excel_utils 将它调整为我们的指定模板格式
期望的数据格式 :

[{'做菜步骤': '蛋炒饭', '步骤序号': 'step_01', '操作': '油锅烧热', '是否完成': 100.0}, {'做菜步骤': '蛋炒饭', '步骤序号': 'step_02', '操作': '放油', '是否完成': 100.0}, {'做菜步骤': '蛋炒饭', '步骤序号': 'step_03', '操作': '放鸡蛋', '是否完成': 100.0}, {'做菜步骤': '蛋炒饭', '步骤序号': 'step_04', '操作': '放米饭', '是否完成': 80.0}, {'做菜步骤': '辣椒炒肉', '步骤序号': 'step_01', '操作': '油锅烧热', '是否完成': 100.0}, {'做菜步骤': '辣椒炒肉', '步骤序号': 'step_02', '操作': '放油', '是否完成': 100.0}, {'做菜步骤': '辣椒炒肉', '步骤序号': 'step_03', '操作': '放肉', '是否完成': 100.0}, {'做菜步骤': '辣椒炒肉', '步骤序号': 'step_04', '操作': '放辣椒', '是否完成': 80.0}]
- 首先我们导入昨天封装好的 excel_utils
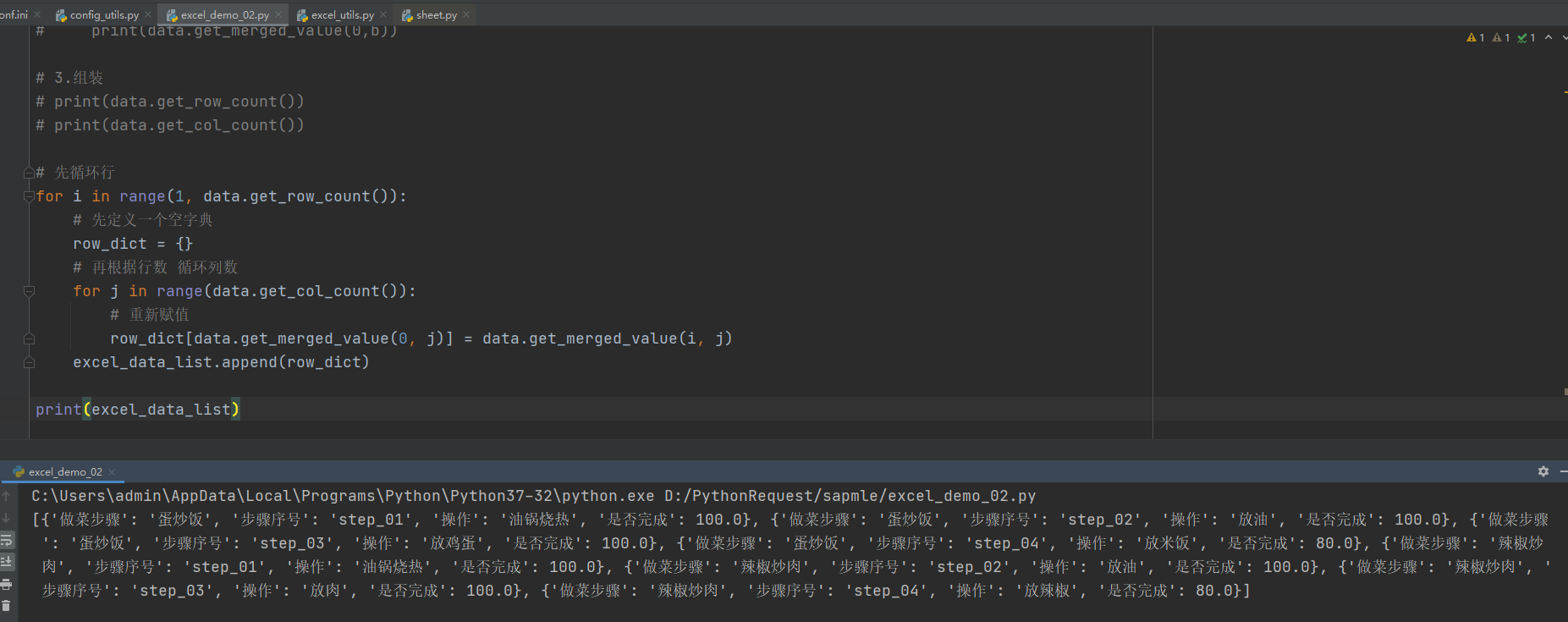
- excel_demo_02.py
# -*- coding: utf-8 -*- # @Time : 2021/12/9 10:23 # @Author : Limusen # @File : excel_demo_02 import xlrd3 from common.excel_utils import ExcelUtils excel_data_list = [] data = ExcelUtils("做饭秘籍.xlsx", "Sheet1") expect_list = [ {'做菜步骤': '蛋炒饭', '步骤序号': 'step_01', '操作': '油锅烧热', '是否完成': 100.0}, {'做菜步骤': '蛋炒饭', '步骤序号': 'step_02', '操作': '放油', '是否完成': 100.0}, {'做菜步骤': '蛋炒饭', '步骤序号': 'step_03', '操作': '放鸡蛋', '是否完成': 100.0}, {'做菜步骤': '蛋炒饭', '步骤序号': 'step_04', '操作': '放米饭', '是否完成': 80.0}, {'做菜步骤': '辣椒炒肉', '步骤序号': 'step_01', '操作': '油锅烧热', '是否完成': 100.0}, {'做菜步骤': '辣椒炒肉', '步骤序号': 'step_02', '操作': '放油', '是否完成': 100.0}, {'做菜步骤': '辣椒炒肉', '步骤序号': 'step_03', '操作': '放肉', '是否完成': 100.0}, {'做菜步骤': '辣椒炒肉', '步骤序号': 'step_04', '操作': '放辣椒', '是否完成': 80.0}] # # 1.获取行的数据 i为循环的次数 # for i in range(1, data.get_row_count()): # print(data.get_merged_value(i, 0)) # # 2.获取列的数据 # for b in range(0, data.get_col_count()): # print(data.get_merged_value(0,b)) # 3.组装 # print(data.get_row_count()) # print(data.get_col_count()) # 先循环行 for i in range(1, data.get_row_count()): # 先定义一个空字典 row_dict = {} # 再根据行数 循环列数 for j in range(data.get_col_count()): # 重新赋值 row_dict[data.get_merged_value(0, j)] = data.get_merged_value(i, j) excel_data_list.append(row_dict) print(excel_data_list)
- 做好之后封装到excel_utils类中
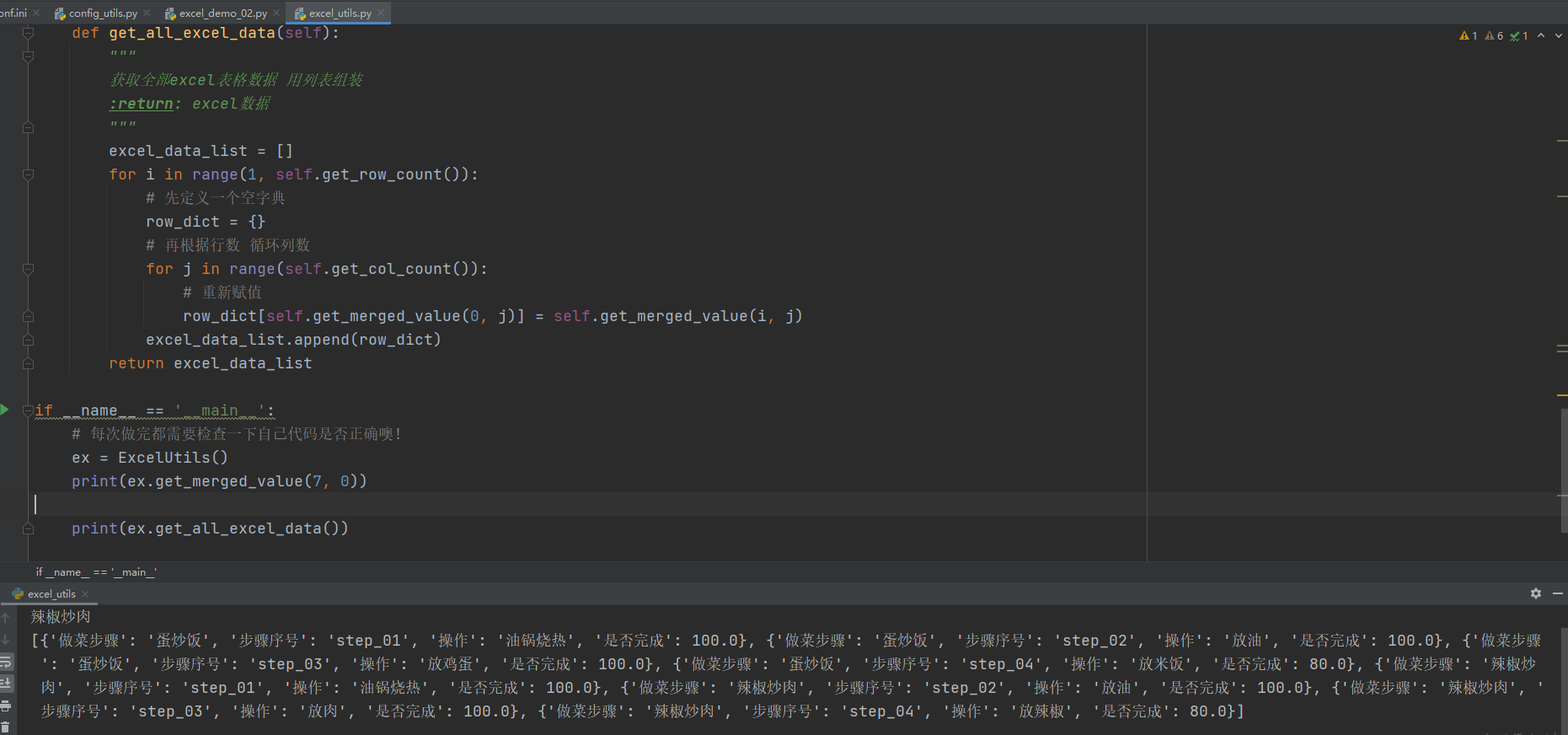
- excel_utils.py 新增 get_all_excel_data 方法
# -*- coding: utf-8 -*- # @Time : 2021/12/8 16:40 # @Author : Limusen # @File : excel_utils import os import xlrd3 # 优化获取文件路径的方式 current_path = os.path.dirname(os.path.abspath(__file__)) # 这里分开写是为了适配mac跟windows之间的// 转义,这样更兼容 excel_file_path = os.path.join(current_path, '..', 'testcase_data', '做饭秘籍.xlsx') sheet_name = "Sheet1" class ExcelUtils: def __init__(self, excel_file_path=excel_file_path, sheet_name=sheet_name): self.excel_file_path = excel_file_path self.sheet_name = sheet_name self.sheet_obj = self.get_sheet_obj() def get_sheet_obj(self): """ 创建工作蒲对象 :return: """ workbook_obj = xlrd3.open_workbook(excel_file_path) sheet_obj = self.workbook_obj.sheet_by_name(sheet_name) return self.sheet_obj def get_row_count(self): """ 获取总行数 :return: """ return self.sheet_obj.nrows def get_col_count(self): """ 获取总列数 :return: """ return self.sheet_obj.ncols def get_merged_value(self, row_index, col_index): """ 查询指定单元格信息 :param row_index: 想要查询的行坐标 :param col_index: 想要查询的类坐标 :return: """ for (min_row, max_row, min_col, max_col) in self.sheet_obj.merged_cells: if row_index >= min_row and row_index < max_row: if col_index >= min_col and col_index < max_col: # 是合并单元格,单元格的值等于 合并单元格中的第一个单元格的值 cell_value = self.sheet_obj.cell_value(min_row, min_col) break else: cell_value = self.sheet_obj.cell_value(row_index, col_index) else: cell_value = self.sheet_obj.cell_value(row_index, col_index) return cell_value def get_all_excel_data(self): """ 获取全部excel表格数据 用列表组装 :return: excel数据 """ excel_data_list = [] for i in range(1, self.get_row_count()): # 先定义一个空字典 row_dict = {} # 再根据行数 循环列数 for j in range(self.get_col_count()): # 重新赋值 row_dict[self.get_merged_value(0, j)] = self.get_merged_value(i, j) excel_data_list.append(row_dict) return excel_data_list if __name__ == '__main__': # 每次做完都需要检查一下自己代码是否正确噢! ex = ExcelUtils() print(ex.get_merged_value(7, 0)) print(ex.get_all_excel_data())
到此优化完成excel_utils 读取到我们想要的数据格式
封装testcase_data_utils类
excel文件长这样

- 上面说到我们可以获取到excel的全部数据,现在讲它组装成我们测试数据需要的格式
- 格式如下:

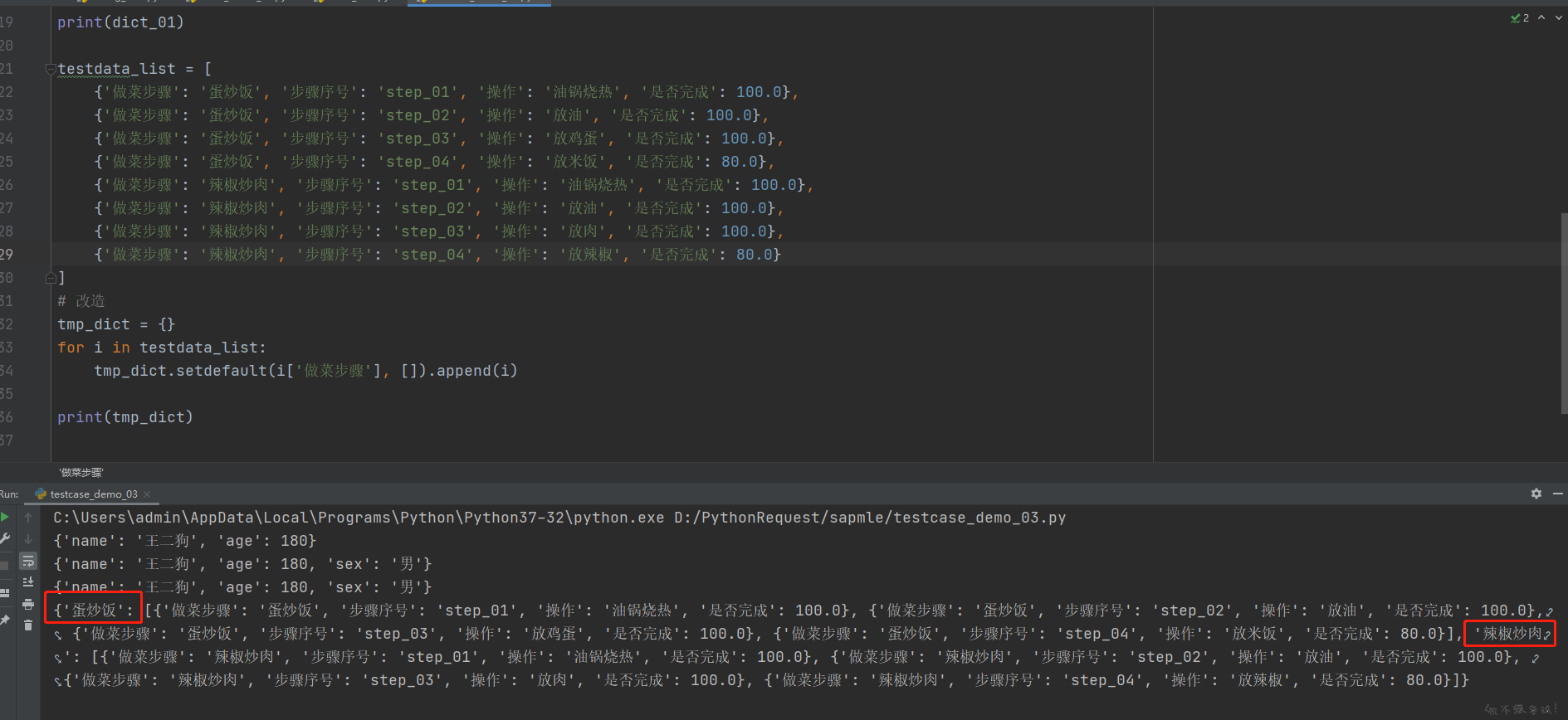
这里说到一个新的知识 字典的setdefault()
Python 字典 setdefault() 函数和 get()方法 类似, 如果键不存在于字典中,将会添加键并将值设为默认值。
如果字典中包含有给定键,则返回该键对应的值,否则返回为该键设置的值。
- 学习 setdefault() 方法
testcase_demo_03.py
# -*- coding: utf-8 -*- # @Time : 2021/12/9 11:10 # @Author : Limusen # @File : testcase_demo_03 # 字典设置默认值 dict_01 = {"name": "王二狗", "age": 180} print(dict_01) # 使用setdefault可以新增数据到字典 dict_01.setdefault("sex", "男") print(dict_01) # 尝试一下如果有值的情况,再试一下setdefault dict_01.setdefault("age", 29) # 这个时候发现 setdefault不会改变已有的值 print(dict_01) testdata_list = [ {'做菜步骤': '蛋炒饭', '步骤序号': 'step_01', '操作': '油锅烧热', '是否完成': 100.0}, {'做菜步骤': '蛋炒饭', '步骤序号': 'step_02', '操作': '放油', '是否完成': 100.0}, {'做菜步骤': '蛋炒饭', '步骤序号': 'step_03', '操作': '放鸡蛋', '是否完成': 100.0}, {'做菜步骤': '蛋炒饭', '步骤序号': 'step_04', '操作': '放米饭', '是否完成': 80.0}, {'做菜步骤': '辣椒炒肉', '步骤序号': 'step_01', '操作': '油锅烧热', '是否完成': 100.0}, {'做菜步骤': '辣椒炒肉', '步骤序号': 'step_02', '操作': '放油', '是否完成': 100.0}, {'做菜步骤': '辣椒炒肉', '步骤序号': 'step_03', '操作': '放肉', '是否完成': 100.0}, {'做菜步骤': '辣椒炒肉', '步骤序号': 'step_04', '操作': '放辣椒', '是否完成': 80.0} ] # 改造 tmp_dict = {} for i in testdata_list: tmp_dict.setdefault(i['做菜步骤'], []).append(i) print(tmp_dict)
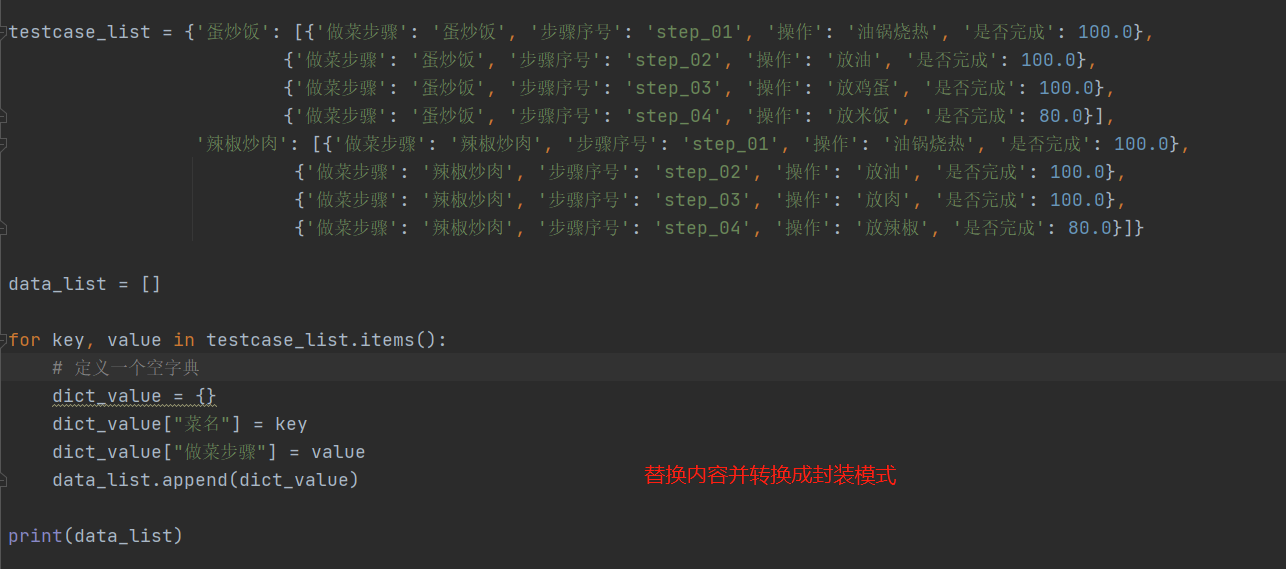
- 继续优化
- testcase_demo_04.py
# -*- coding: utf-8 -*- # @Time : 2021/12/9 13:36 # @Author : Limusen # @File : testcase_demo_04 testcase_list = {'蛋炒饭': [{'做菜步骤': '蛋炒饭', '步骤序号': 'step_01', '操作': '油锅烧热', '是否完成': 100.0}, {'做菜步骤': '蛋炒饭', '步骤序号': 'step_02', '操作': '放油', '是否完成': 100.0}, {'做菜步骤': '蛋炒饭', '步骤序号': 'step_03', '操作': '放鸡蛋', '是否完成': 100.0}, {'做菜步骤': '蛋炒饭', '步骤序号': 'step_04', '操作': '放米饭', '是否完成': 80.0}], '辣椒炒肉': [{'做菜步骤': '辣椒炒肉', '步骤序号': 'step_01', '操作': '油锅烧热', '是否完成': 100.0}, {'做菜步骤': '辣椒炒肉', '步骤序号': 'step_02', '操作': '放油', '是否完成': 100.0}, {'做菜步骤': '辣椒炒肉', '步骤序号': 'step_03', '操作': '放肉', '是否完成': 100.0}, {'做菜步骤': '辣椒炒肉', '步骤序号': 'step_04', '操作': '放辣椒', '是否完成': 80.0}]} data_list = [] for key, value in testcase_list.items(): # 定义一个空字典 dict_value = {} dict_value["菜名"] = key dict_value["做菜步骤"] = value data_list.append(dict_value) print(data_list)
- 接下来封装testcase_data_utils.py 完成我们的封装读取测试数据类
将测试数据转换成字典格式
testcase_data_utils.py
# -*- coding: utf-8 -*- # @Time : 2021/12/9 13:42 # @Author : Limusen # @File : testcase_data_utils import os from common.excel_utils import ExcelUtils current = os.path.dirname(os.path.abspath(__file__)) excel_file_path = os.path.join(current, '..', 'testcase_data', 'testcase_infos.xlsx') excel_sheet_name = "Sheet1" class TestCaseDataUtils: def __init__(self): self.ex = ExcelUtils(excel_file_path=excel_file_path, sheet_name=excel_sheet_name) def test(self): print(self.ex.get_all_excel_data()) def convert_data_info_dict(self): """ 将测试数据转换成字典 :param testcase_info: :return: """ test_case_dict = {} for testcase in self.ex.get_all_excel_data(): test_case_dict.setdefault(testcase['测试用例编号'], []).append(testcase) return test_case_dict if __name__ == '__main__': print(TestCaseDataUtils().convert_data_info_dict())
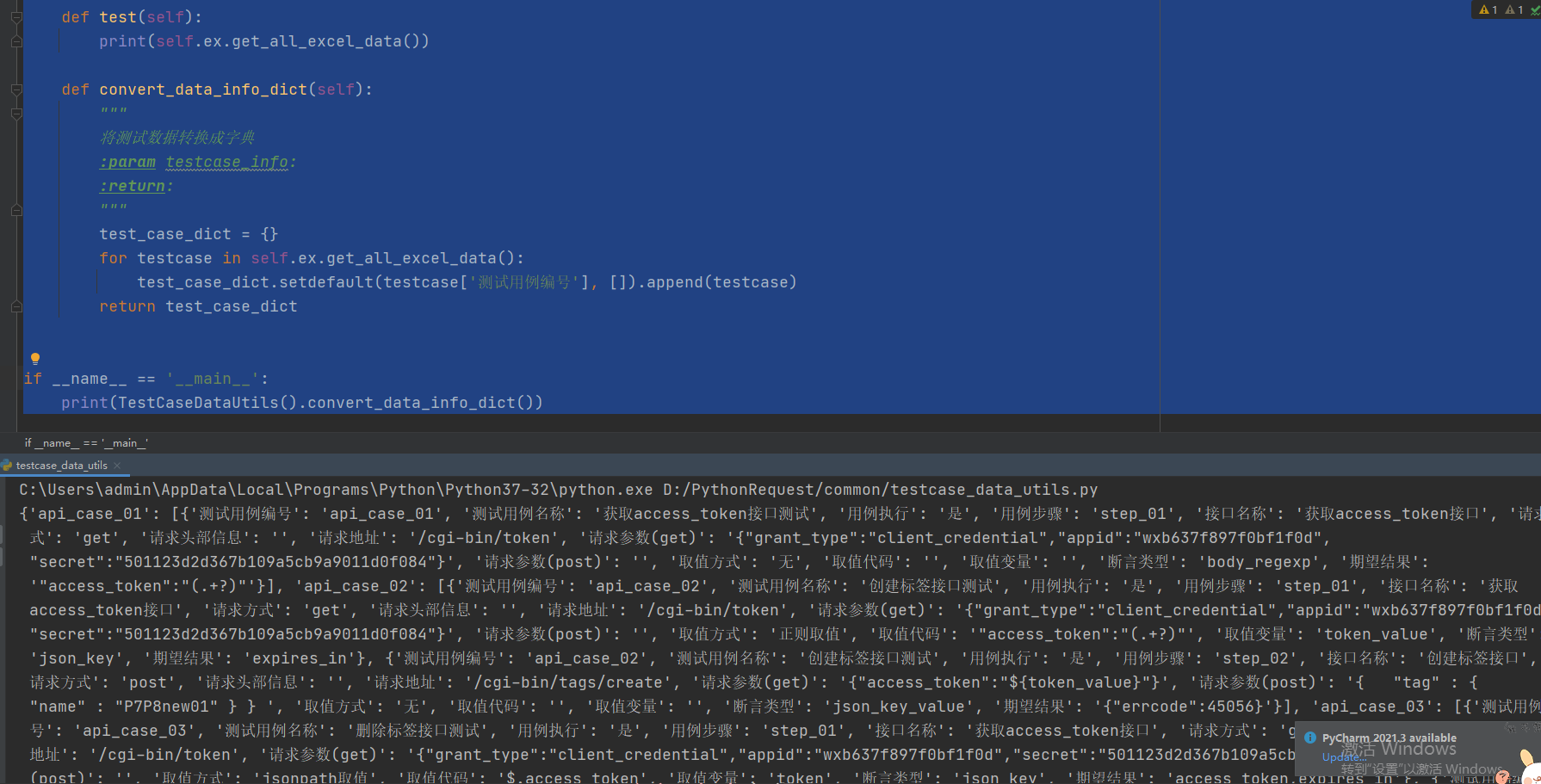
- 继续优化,封装转换成列表包夹字典
testcase_data_utils.py
# -*- coding: utf-8 -*- # @Time : 2021/12/9 13:42 # @Author : Limusen # @File : testcase_data_utils import os from common.excel_utils import ExcelUtils current = os.path.dirname(os.path.abspath(__file__)) excel_file_path = os.path.join(current, '..', 'testcase_data', 'testcase_infos.xlsx') excel_sheet_name = "Sheet1" class TestCaseDataUtils: def __init__(self): self.ex = ExcelUtils(excel_file_path=excel_file_path, sheet_name=excel_sheet_name) def test(self): print(self.ex.get_all_excel_data()) def convert_data_info_dict(self): """ 将测试数据转换成字典 :param testcase_info: :return: """ test_case_dict = {} for testcase in self.ex.get_all_excel_data(): test_case_dict.setdefault(testcase['测试用例编号'], []).append(testcase) return test_case_dict def convert_data_info_list(self): test_case_list = [] for key, value in self.convert_data_info_dict().items(): type_dict = {} type_dict["case_id"] = key type_dict["case_step"] = value test_case_list.append(type_dict) return test_case_list if __name__ == '__main__': print(TestCaseDataUtils().convert_data_info_list())
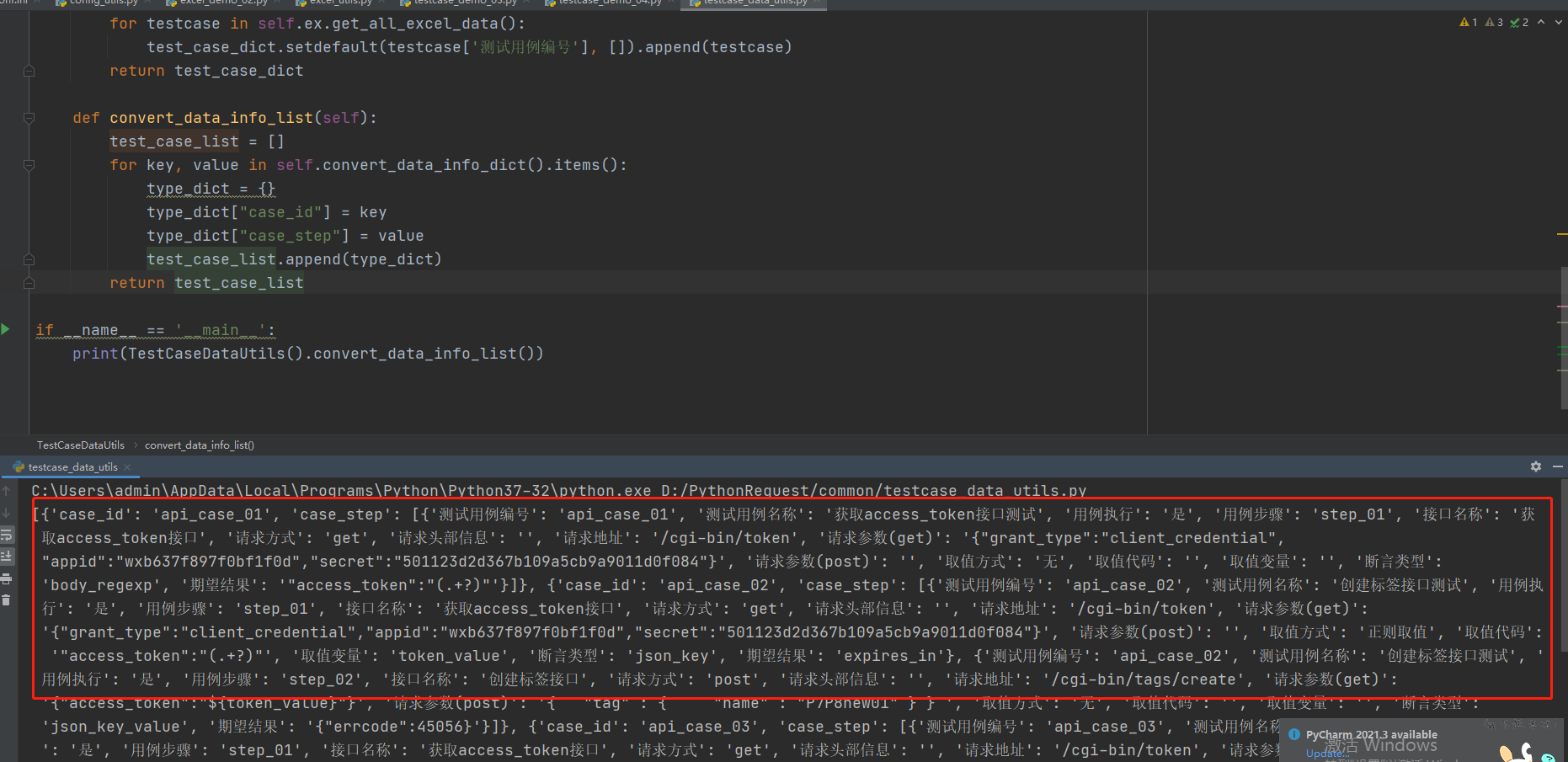
到此我们的excel封装就结束咯 ~
- 现在的项目框架图
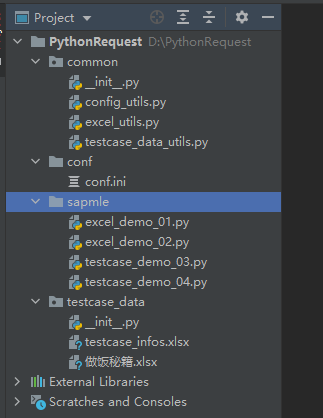
读取excel跟testcase都已经好了 下一章节要对request请求进行封装
欢迎转载 请注明出处: https://www.cnblogs.com/yushengaqingzhijiao/p/15665812.html