本章主要讨论,在Spark2.4 Structured Streaming读取kafka数据源时,kafka的topic数据是如何被执行的过程进行分析。
以下边例子展开分析:
SparkSession sparkSession = SparkSession.builder().getOrCreate(); Dataset<Row> sourceDataset = sparkSession.readStream().format("kafka").option("", "").load(); sourceDataset.createOrReplaceTempView("tv_test"); Dataset<Row> aggResultDataset = sparkSession.sql("select ...."); StreamingQuery query = aggResultDataset.writeStream().format("kafka").option("", "") .trigger(Trigger.Continuous(1000)) .start(); try { query.awaitTermination(); } catch (StreamingQueryException e1) { e1.printStackTrace(); }
上边例子业务,使用structured streaming读取kafka的topic,并做agg,然后sink到kafka的另外一个topic上。
DataSourceReader#load方法
要分析DataSourceReader#load方法返回的DataSet的处理过程,需要对DataSourceReader的load方法进行分析,下边这个截图就是DataSourceReader#load的核心代码。
在分析之前,我们来了解一下测试结果:
package com.boco.broadcast trait MicroBatchReadSupport { } trait ContinuousReadSupport { } trait DataSourceRegister { def shortName(): String } class KafkaSourceProvider extends DataSourceRegister with MicroBatchReadSupport with ContinuousReadSupport{ override def shortName(): String = "kafka" } object KafkaSourceProvider{ def main(args:Array[String]):Unit={ val ds=classOf[KafkaSourceProvider].newInstance() ds match { case s: MicroBatchReadSupport => println("MicroBatchReadSupport") case s:ContinuousReadSupport=> println("ContinuousReadSupport") } } }
上边这个执行结果时只会执行输出“MicroBatchReadSupport”,永远走不到ConitnuousReadSupport match分支,后边会单独介绍这个事情。。。
带着这个测试结果,我们分析DataSourceReader的load方法代码:
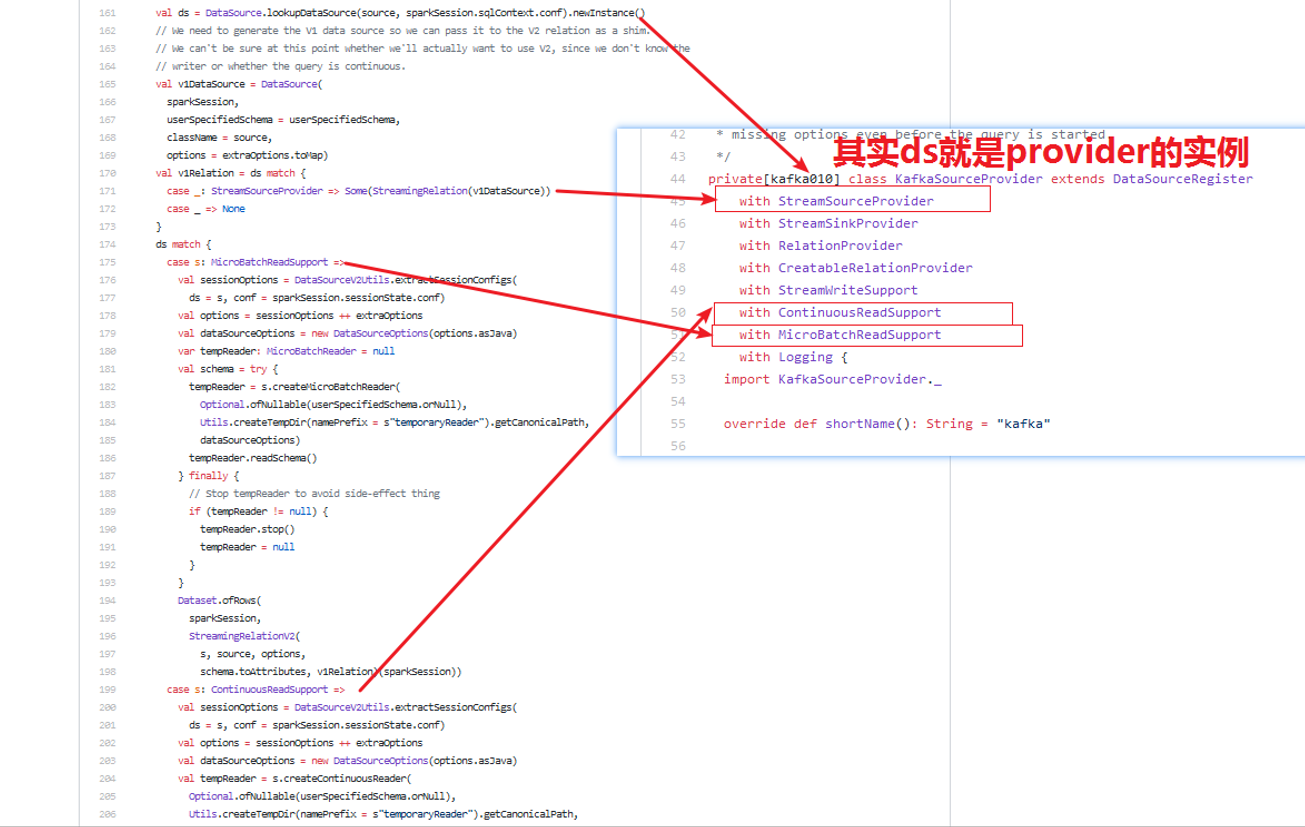
1)经过上篇文章《Spark2.x(六十):在Structured Streaming流处理中是如何查找kafka的DataSourceProvider? 》分析,我们知道DataSource.lookupDataSource()方法,返回的是KafkaSourceProvider类,那么ds就是KafkaSourceProvider的实例对象;
2)从上边截图我们可以清楚的知道KafkaSourceProvider(https://github.com/apache/spark/blob/master/external/kafka-0-10-sql/src/main/scala/org/apache/spark/sql/kafka010/KafkaSourceProvider.scala)的定义继承了DataSourceRegister,StreamSourceProvider,StreamSinkProvider,RelationProvider,CreatableRelationProvider,StreamWriteProvider,ContinuousReadSupport,MicroBatchReadSupport等接口
3) v1DataSource是DataSource类,那么我们来分析DataSource初始化都做了什么事情。
// We need to generate the V1 data source so we can pass it to the V2 relation as a shim. // We can't be sure at this point whether we'll actually want to use V2, since we don't know the // writer or whether the query is continuous. val v1DataSource = DataSource( sparkSession, userSpecifiedSchema = userSpecifiedSchema, className = source, options = extraOptions.toMap)
在DataSource初始化做的事情只有这些,并未加载数据。
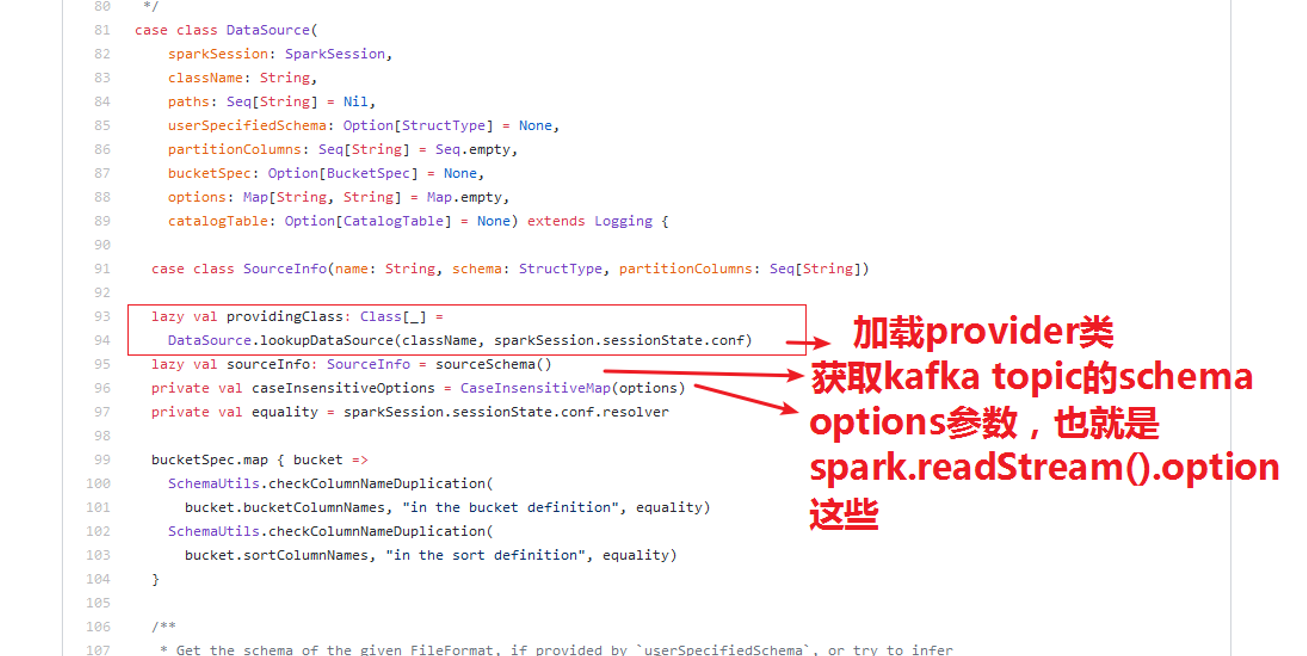
1)调用object DataSource.loopupDataSource加载provider class;
2)获取kafka的topic的schema;
3)保存option参数,也就是sparkSession.readStream().option相关参数;
4)获取sparkSession属性。
DataSource#sourceSchema()方法:
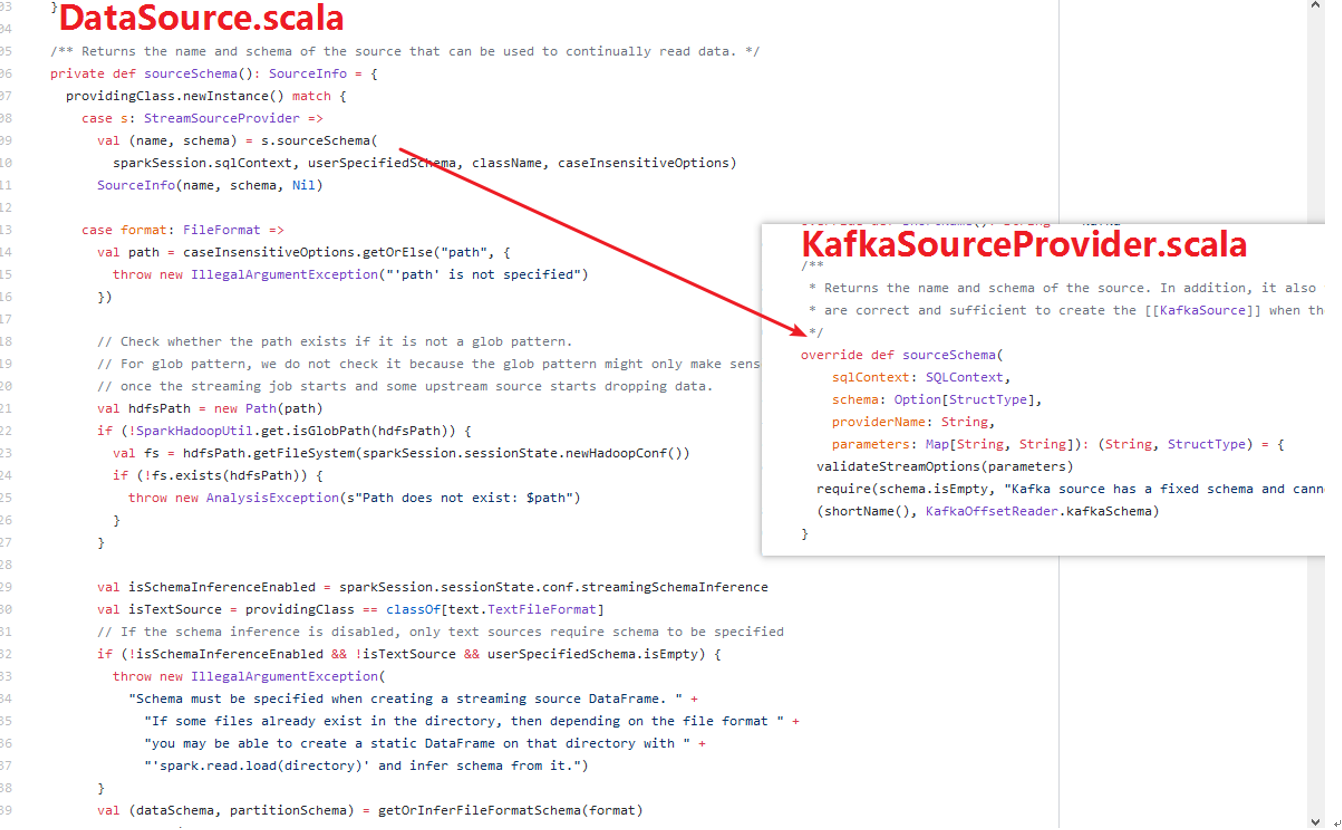
1)DataSource#sourceSchema方法内部调用KafkaSourceProvider的#sourceShema(。。。);
2)KafkaSourceProvider#sourceSchema返回了Map,(key:shourName(),value:KafkaOffsetReader.kafkaSchema)。
在DataSource的sourceSchema方法下边包含:
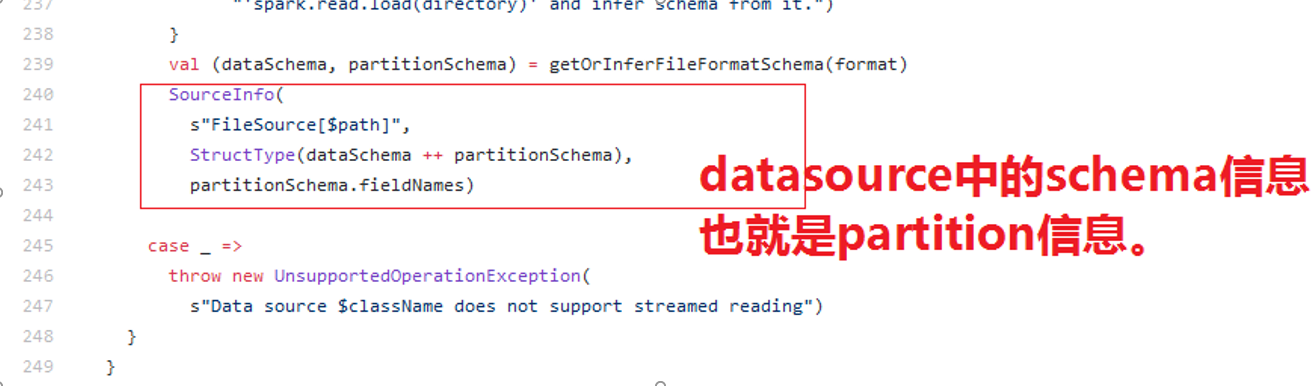
在KafkaOffsetReader中返回的schema信息包含:

代码分析到这里并未加载数据。
ds就是provider实例,
v1DataSource是实际上就是包含source的provider,source的属性(spark.readeStream.option这些参数[topic,maxOffsetsSize等等]),source的schema的,它本身是一个数据描述类。
ds支持MicroBatchReadSupport与ContinuousReadSuuport的分支:

两个主要区别还是在tempReader的区别:
MicroBatchReadSupport:使用KafkaSourceProvider的createMicroBatchReader生成KafkaMicroBatchReader对象;
ContinuousReadSuuport:使用KafkaSourceProvider的createContinuousReader生成KafkaContinuousReader对象。
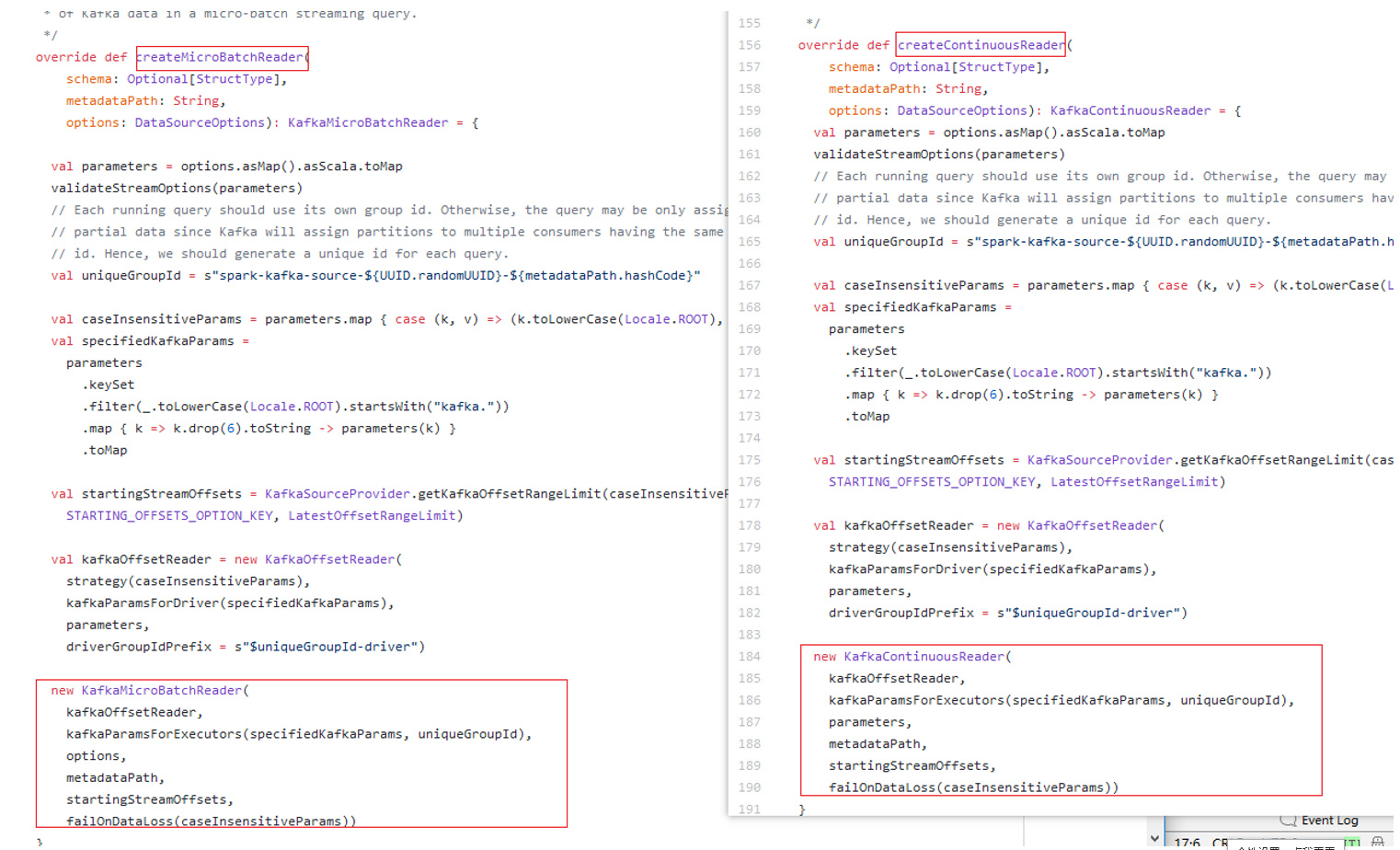
DataSourceReader的format为kafka时,执行的ds match分支分析
测试代码1:
package com.boco.broadcast import java.util.concurrent.TimeUnit import org.apache.spark.sql.streaming.{OutputMode, Trigger} import org.apache.spark.sql.{Row, SparkSession} object TestContinuous { def main(args:Array[String]):Unit={ val spark=SparkSession.builder().appName("test").master("local[*]").getOrCreate() val source= spark.readStream.format("kafka") .option("subscribe", "test") .option("startingOffsets", "earliest") .option("kafka.bootstrap.servers","localhost:9092") .option("failOnDataLoss",true) .option("retries",2) .option("session.timeout.ms",3000) .option("fetch.max.wait.ms",500) .option("key.serializer", "org.apache.kafka.common.serialization.StringSerializer") .option("value.serializer", "org.apache.kafka.common.serialization.StringSerializer") .load() source.createOrReplaceTempView("tv_test") val aggResult=spark.sql("select * from tv_test") val query=aggResult.writeStream .format("csv") .option("path","E:\test\testdd") .option("checkpointLocation","E:\test\checkpoint") .trigger(Trigger.Continuous(5,TimeUnit.MINUTES)) .outputMode(OutputMode.Append()) .start() query.awaitTermination() } }
测试代码2:
package com.boco.broadcast import java.util.concurrent.TimeUnit import org.apache.spark.sql.streaming.{OutputMode, Trigger} import org.apache.spark.sql.{Row, SparkSession} object TestContinuous { def main(args:Array[String]):Unit={ val spark=SparkSession.builder().appName("test").master("local[*]").getOrCreate() val source= spark.readStream.format("kafka") .option("subscribe", "test") .option("startingOffsets", "earliest") .option("kafka.bootstrap.servers","localhost:9092") .option("failOnDataLoss",true) .option("retries",2) .option("session.timeout.ms",3000) .option("fetch.max.wait.ms",500) .option("key.serializer", "org.apache.kafka.common.serialization.StringSerializer") .option("value.serializer", "org.apache.kafka.common.serialization.StringSerializer") .load() source.createOrReplaceTempView("tv_test") val aggResult=spark.sql("select * from tv_test") val query=aggResult.writeStream .format("kafka") .option("subscribe", "test_sink") .option("checkpointLocation","E:\test\checkpoint") .trigger(Trigger.Continuous(5,TimeUnit.MINUTES)) .outputMode(OutputMode.Append()) .start() query.awaitTermination() } }
测试代码的Pom文件:


<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"> <modelVersion>4.0.0</modelVersion> <groupId>com.boco.broadcast.test</groupId> <artifactId>broadcast_test</artifactId> <version>1.0-SNAPSHOT</version> <inceptionYear>2008</inceptionYear> <properties> <scala.version>2.11.12</scala.version> <spark.version>2.4.0</spark.version> </properties> <repositories> <repository> <id>scala-tools.org</id> <name>Scala-Tools Maven2 Repository</name> <url>http://scala-tools.org/repo-releases</url> </repository> </repositories> <pluginRepositories> <pluginRepository> <id>scala-tools.org</id> <name>Scala-Tools Maven2 Repository</name> <url>http://scala-tools.org/repo-releases</url> </pluginRepository> </pluginRepositories> <dependencies> <!--Scala --> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-reflect</artifactId> <version>${scala.version}</version> </dependency> <dependency> <groupId>org.scala-lang</groupId> <artifactId>scala-compiler</artifactId> <version>${scala.version}</version> </dependency> <!--Scala --> <!--Spark --> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.11</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-streaming_2.11</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.11</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql-kafka-0-10_2.11</artifactId> <version>${spark.version}</version> </dependency> <dependency> <groupId>org.apache.kafka</groupId> <artifactId>kafka-clients</artifactId> <version>2.3.0</version> </dependency> <!--Spark --> <dependency> <groupId>junit</groupId> <artifactId>junit</artifactId> <version>4.11</version> <scope>test</scope> </dependency> <dependency> <groupId>org.specs</groupId> <artifactId>specs</artifactId> <version>1.2.5</version> <scope>test</scope> </dependency> </dependencies> <build> <sourceDirectory>src/main/scala</sourceDirectory> <testSourceDirectory>src/test/scala</testSourceDirectory> <plugins> <plugin> <groupId>org.scala-tools</groupId> <artifactId>maven-scala-plugin</artifactId> <executions> <execution> <goals> <goal>compile</goal> <goal>testCompile</goal> </goals> </execution> </executions> <configuration> <scalaVersion>${scala.version}</scalaVersion> <args> <arg>-target:jvm-1.8</arg> </args> </configuration> </plugin> <plugin> <groupId>org.apache.maven.plugins</groupId> <artifactId>maven-eclipse-plugin</artifactId> <configuration> <downloadSources>true</downloadSources> <buildcommands> <buildcommand>ch.epfl.lamp.sdt.core.scalabuilder</buildcommand> </buildcommands> <additionalProjectnatures> <projectnature>ch.epfl.lamp.sdt.core.scalanature</projectnature> </additionalProjectnatures> <classpathContainers> <classpathContainer>org.eclipse.jdt.launching.JRE_CONTAINER</classpathContainer> <classpathContainer>ch.epfl.lamp.sdt.launching.SCALA_CONTAINER</classpathContainer> </classpathContainers> </configuration> </plugin> </plugins> </build> <reporting> <plugins> <plugin> <groupId>org.scala-tools</groupId> <artifactId>maven-scala-plugin</artifactId> <configuration> <scalaVersion>${scala.version}</scalaVersion> </configuration> </plugin> </plugins> </reporting> </project>
调试结果:
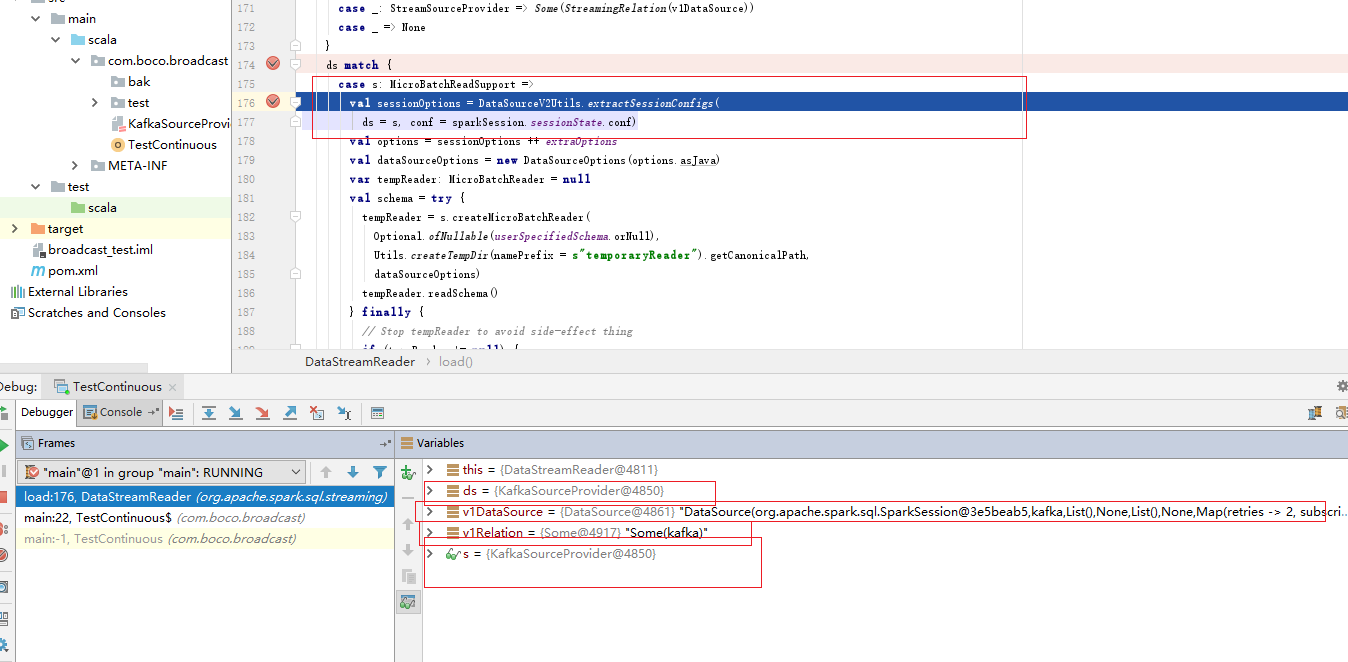
不管是执行“测试代码1” ,还是执行“测试代码2”,ds match的结果一样,都是只走case MicroBatchReadSupport分支,这里一个疑问:
为什么在Trigger是Continous方式时,读取kafka topic数据源采用的是“KafkaMicroBatchReader”,而不是“KafkaContinuousReader”?
DataSourceReader#load返回Dataset是一个LogicPlan
但是最终都被包装为StreamingRelationV2 extends LeafNode (logicPlan)传递给Dataset,Dataset在加载数据时,执行的就是这个logicplan
package org.apache.spark.sql.execution.streaming import org.apache.spark.rdd.RDD import org.apache.spark.sql.SparkSession import org.apache.spark.sql.catalyst.InternalRow import org.apache.spark.sql.catalyst.analysis.MultiInstanceRelation import org.apache.spark.sql.catalyst.expressions.Attribute import org.apache.spark.sql.catalyst.plans.logical.{LeafNode, LogicalPlan, Statistics} import org.apache.spark.sql.execution.LeafExecNode import org.apache.spark.sql.execution.datasources.DataSource import org.apache.spark.sql.sources.v2.{ContinuousReadSupport, DataSourceV2} object StreamingRelation { def apply(dataSource: DataSource): StreamingRelation = { StreamingRelation( dataSource, dataSource.sourceInfo.name, dataSource.sourceInfo.schema.toAttributes) } } /** * Used to link a streaming [[DataSource]] into a * [[org.apache.spark.sql.catalyst.plans.logical.LogicalPlan]]. This is only used for creating * a streaming [[org.apache.spark.sql.DataFrame]] from [[org.apache.spark.sql.DataFrameReader]]. * It should be used to create [[Source]] and converted to [[StreamingExecutionRelation]] when * passing to [[StreamExecution]] to run a query. */ case class StreamingRelation(dataSource: DataSource, sourceName: String, output: Seq[Attribute]) extends LeafNode with MultiInstanceRelation { override def isStreaming: Boolean = true override def toString: String = sourceName // There's no sensible value here. On the execution path, this relation will be // swapped out with microbatches. But some dataframe operations (in particular explain) do lead // to this node surviving analysis. So we satisfy the LeafNode contract with the session default // value. override def computeStats(): Statistics = Statistics( sizeInBytes = BigInt(dataSource.sparkSession.sessionState.conf.defaultSizeInBytes) ) override def newInstance(): LogicalPlan = this.copy(output = output.map(_.newInstance())) } 。。。。 // We have to pack in the V1 data source as a shim, for the case when a source implements // continuous processing (which is always V2) but only has V1 microbatch support. We don't // know at read time whether the query is conntinuous or not, so we need to be able to // swap a V1 relation back in. /** * Used to link a [[DataSourceV2]] into a streaming * [[org.apache.spark.sql.catalyst.plans.logical.LogicalPlan]]. This is only used for creating * a streaming [[org.apache.spark.sql.DataFrame]] from [[org.apache.spark.sql.DataFrameReader]], * and should be converted before passing to [[StreamExecution]]. */ case class StreamingRelationV2( dataSource: DataSourceV2, sourceName: String, extraOptions: Map[String, String], output: Seq[Attribute], v1Relation: Option[StreamingRelation])(session: SparkSession) extends LeafNode with MultiInstanceRelation { override def otherCopyArgs: Seq[AnyRef] = session :: Nil override def isStreaming: Boolean = true override def toString: String = sourceName override def computeStats(): Statistics = Statistics( sizeInBytes = BigInt(session.sessionState.conf.defaultSizeInBytes) ) override def newInstance(): LogicalPlan = this.copy(output = output.map(_.newInstance()))(session) }
那两个reader是microbatch和continue获取数据的根本规则定义。
StreamingRelation和StreamingRelationV2只是对datasource的包装,而且自身继承了catalyst.plans.logical.LeafNode,并不具有其他操作,只是个包装类。
实际上这些都是一个逻辑计划生成的过程,生成了一个具有逻辑计划的Dataset,以便后边触发流处理是执行该逻辑计划生成数据来使用。
Dataset的LogicPlan怎么被触发?
start()方法返回的是一个StreamingQuery对象,StreamingQuery是一个接口类定义在:
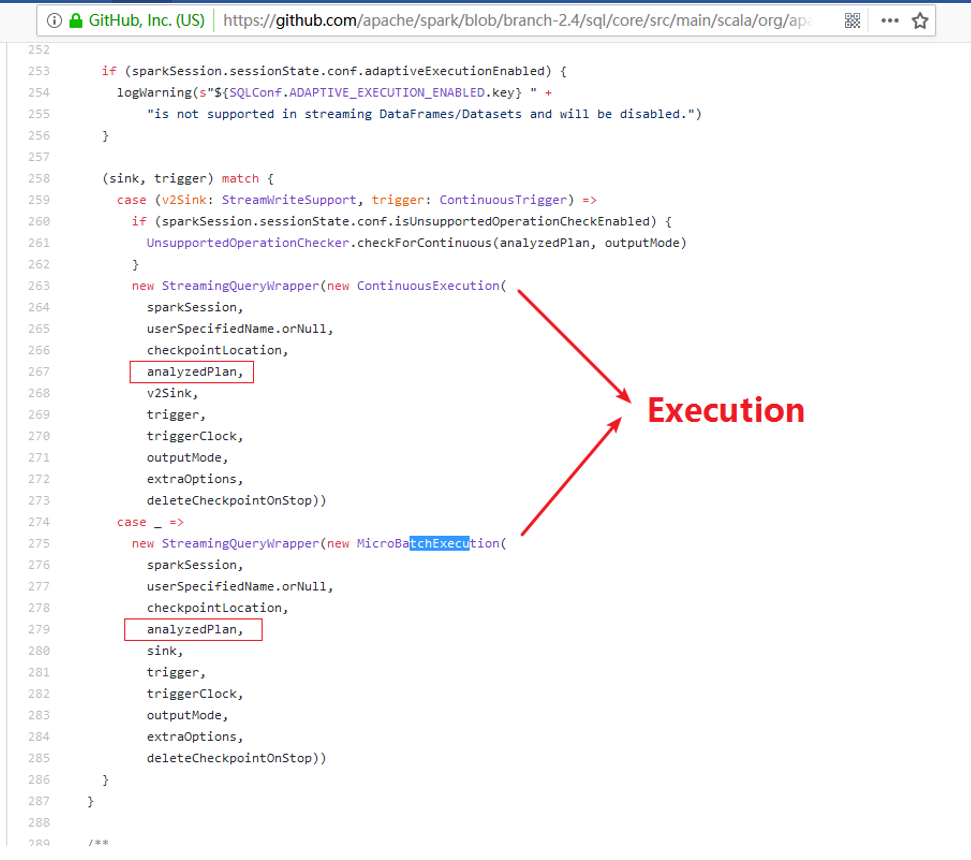
aggResult.wirteStream.format(“kafka”).option(“”,””).trigger(Trigger.Continuous(1000)),它是一个DataStreamWriter对象:
在DataStreamWriter中定义了一个start方法,在这个start方法是整个流处理程序开始执行的入口。
DataStreamWriter的start方法内部走的分支代码如下:

上边的DataStreamWriter#start()最后一行调用的StreamingQueryManager#startQuery()