第一次个人项目作业
python实现简单论文查重
| 这个作业属于哪个课程 | 课程链接 |
|---|---|
| 作业要求 | 作业要求 |
| 这个作业的目标 | 论文查重 |
| github项目地址:https://github.com/wptr-777/3119005439 |
词句解析
使用jieba分词库,可以对中文进行分词处理,具体可参照github
import jieba
seg_list = jieba.cut("他来自中国")
print(", ".join(seg_list))
运行结果

读取文件内容
读取文件中的内容
def get_file(path):
content = ''
with open(path) as fd:
content = fd.read()
return content
过滤特殊符号
使用正则表达式过滤特殊符号,再用jieba分词
def filter_string(string):
my_re = re.compile(u"[^a-zA-Z0-9u4e00-u9fa5]")
string = my_re.sub("", string)
result = jieba.lcut(string)
return result
计算相似度
使用gensim库计算余弦相似度,实现方法如下
def calc_similarity(text1,text2):
texts=[text1,text2]
dictionary = gensim.corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
similarity = gensim.similarities.Similarity('-Similarity-index', corpus, num_features=len(dictionary))
test_corpus_1 = dictionary.doc2bow(text1)
cosine_sim = similarity[test_corpus_1][1]
return cosine_sim
代码实现
import gensim
import jieba
import re
import sys
def get_file(path):
with open(path) as fd:
content = fd.read()
return content
def filter_string(string):
my_re = re.compile(u"[^a-zA-Z0-9u4e00-u9fa5]")
string = my_re.sub("", string)
result = jieba.lcut(string)
return result
def calc_similarity(text1, text2):
texts = [text1, text2]
dictionary = gensim.corpora.Dictionary(texts)
corpus = [dictionary.doc2bow(text) for text in texts]
similarity = gensim.similarities.Similarity('-Similarity-index', corpus, num_features=len(dictionary))
test_corpus_1 = dictionary.doc2bow(text1)
cosine_sim = similarity[test_corpus_1][1]
return cosine_sim
def main():
try:
# path1 = "../test_txt/orig.txt"
# path2 = "../test_txt/orig_0.8_add.txt"
# save_path = "../result.txt"
path1 = sys.argv[1] # 论文原文的文件的绝对路径
path2 = sys.argv[2] # 抄袭版论文的文件的绝对路径
save_path = sys.argv[3] # 输出结果绝对路径
text1 = filter_string(get_file(path1))
text2 = filter_string(get_file(path2))
similarity = calc_similarity(text1, text2)
print("文章相似度: %.4f" % similarity)
fd = open(save_path, 'w')
fd.write("文章相似度: %.4f" % similarity)
fd.close()
result = round(similarity.item(), 2) # 取小数点后两位
except Exception as e:
print(e)
finally:
return result
if __name__ == '__main__':
main()
运行结果
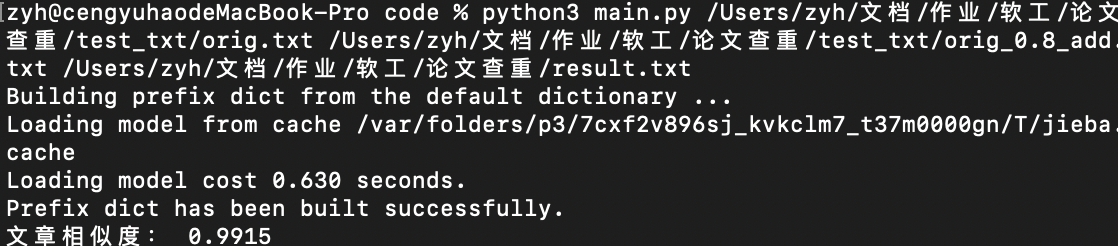
文章相似度99%
单元测试
此处使用unittest库用于单元测试,新建unit_test.py用于单元测试
unit_test.py
import unittest
from main import main
class MyTestCase(unittest.TestCase):
def my_test(self):
self.assertEqual(main(), 0.99) # 预测运行结果
if __name__ == '__main__':
unittest.main()
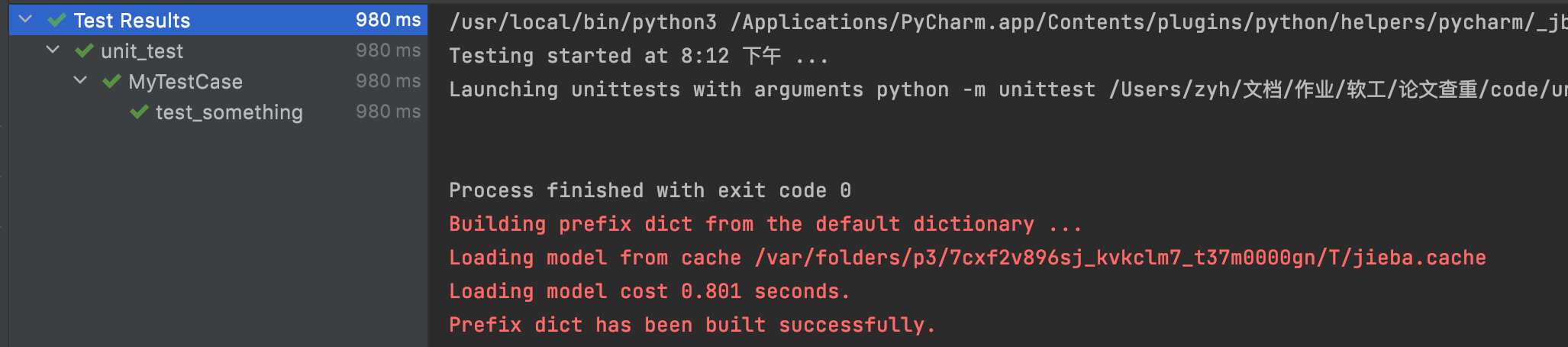
预测结果正确
此处可更换论文路径对余下样例,进行测试
代码覆盖率
使用python库coverage生成代码覆盖率报告
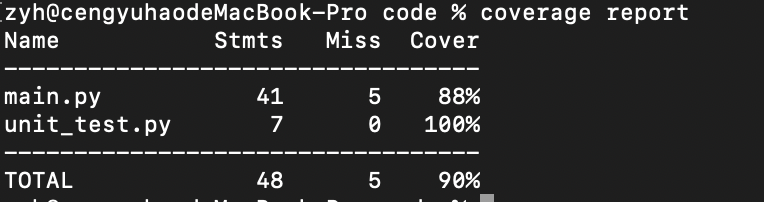
使用如下命令生成网页版代码覆盖率报告
coverage html -d report
使用浏览器查看
没有被覆盖的地方都是异常处理部分的代码
性能分析
使用pycharm的插件进行性能分析

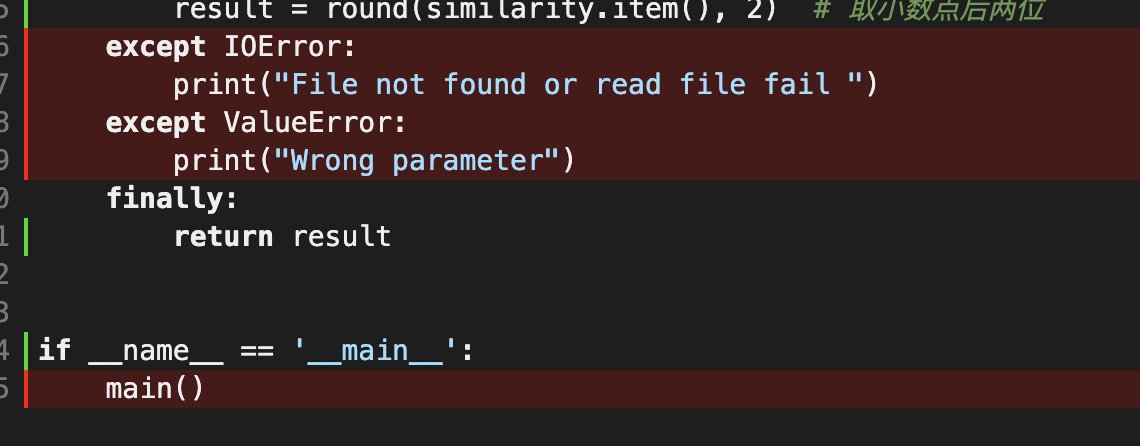
异常处理
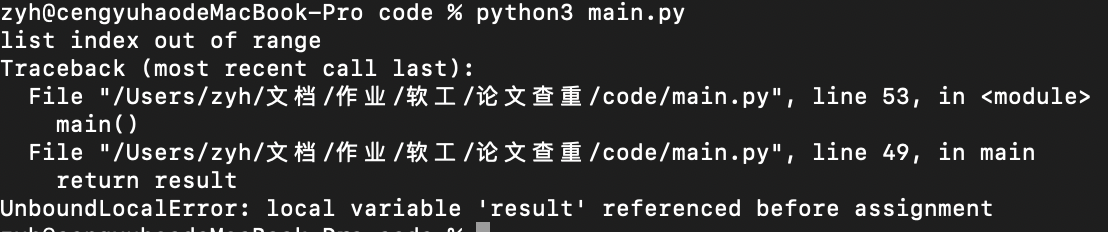
对于参数不合理的情况,进行异常处理
except Exception as e:
print(e)
PSP表格记录
| PSP | Personal Software Process | 预估耗时(分钟) | 实际耗时(分钟) |
|---|---|---|---|
| Planning计划 | 计划 | 120 | 150 |
| Estimate | · 估计这个任务需要多少时间 | 120 | 150 |
| Development | 开发 | 480 | 300 |
| · Analysis | · 需求分析 (包括学习新技术) | 120 | 100 |
| · Design Spec | · 生成设计文档 | 30 | 10 |
| · Design Review | · 设计复审 | 30 | 10 |
| · Coding Standard | · 代码规范 (为目前的开发制定合适的规范) | 20 | 5 |
| · Design | · 具体设计 | 10 | 5 |
| · Coding | · 具体编码 | 120 | 120 |
| · Code Review | · 代码复审 | 20 | 5 |
| · Test | · 测试(自我测试,修改代码,提交修改) | 20 | 20 |
| Reporting | 报告 | 30 | 20 |
| · Test Repor | · 测试报告 | 20 | 10 |
| · Size Measurement | · 计算工作量 | 5 | 5 |
| · Postmortem & Process Improvement Plan | · 事后总结, 并提出过程改进计划 | 5 | 5 |
| Total | 总计 | 1150 | 915 |