本周的学习重心依旧是深度学习,主要实践项目为基于TensorFlow深度学习框架的字母、数字组成的验证码识别。在上周进行了mnist手写数字识别之后,本以为验证码识别是一件很简单的事,但实践起来发现并不是那么回事,首先在训练量上,手写数字识别的识别类型只有0-9十个数字十种类型,且仅有一个手写数字参与识别,而验证码识别的识别类型有字母+数字共26+26+10=62种,且每次有四个字符参与识别,即,每次可能的结果有62的4次方 种。再然后就是数据集,手写数字有TensorFlow入门级的mnist数据集,网上有现成的可以直接下载使用,而验证码则没有一套专门的数据集,再加上验证码图片大小的不一致性,给数据集的处理又增加了难度。
训练神经网络的验证码数据集由代码生成,由于数量过多没有保存数据集文件,只保存了训练好的神经网络模型(本意是将识别准确率提高到98%以上,但实践中发现达到92%都很难,在训练时间达到十个小时的时候识别准确率在87%左右,在训练时间达到十九个小时的时候识别准确率仍在88%左右徘徊,并且很少出现90%+的情况,时间问题在准确率出现92.25%时停止了训练,共训练52000次,每次64个验证码数据被喂入)
由于网上没有验证码的数据集,所以参考了百度生成验证码图片的博文,几乎所有博文都用的相同方法生成数据集,在此不具体列出链接
另参考腾讯视频TensorFlow相关课程
程序源码如下:
1 import tensorflow as tf 2 from captcha.image import ImageCaptcha 3 import numpy as np 4 from PIL import Image 5 import matplotlib.pyplot as plt 6 import os 7 import tkinter.filedialog 8 import random 9 10 number = ['0','1','2','3','4','5','6','7','8','9'] 11 alphabet = ['a','b','c','d','e','f','g','h','i','j','k','l','m','n','o','p','q','r','s','t','u','v','w','x','y','z'] 12 ALPHABET = ['A','B','C','D','E','F','G','H','I','J','K','L','M','N','O','P','Q','R','S','T','U','V','W','X','Y','Z'] 13 14 # 传入数据集,从数据集中随机选择四个元素,然后返回这四个元素 15 def random_captcha_text(char_set=number+alphabet+ALPHABET, captcha_size=4): 16 # def random_captcha_text(char_set=number, captcha_size=4): 17 captcha_text = [] 18 for i in range(captcha_size): 19 c = random.choice(char_set) 20 captcha_text.append(c) 21 return captcha_text 22 23 # 生成验证码图片,返回图片转化后的numpy数组,以及验证码字符文本 24 def gen_captcha_text_and_image(): 25 image = ImageCaptcha() 26 captcha_text = random_captcha_text() 27 captcha_text = ''.join(captcha_text) 28 captcha = image.generate(captcha_text) 29 # image.write(captcha_text, captcha_text + '.jpg') # 将图片保存到硬盘 30 captcha_image = Image.open(captcha) 31 captcha_image = captcha_image.convert('L') 32 captcha_image = captcha_image.point(lambda i: 255 - i) 33 # 将图片取反,黑色变为白色,白色变为黑色,这样模型收敛更块 34 captcha_image = np.array(captcha_image) 35 return captcha_text, captcha_image 36 37 def text2vec(text): 38 text_len = len(text) 39 if text_len > MAX_CAPTCHA: 40 raise ValueError('验证码最长4个字符') 41 vector = np.zeros(MAX_CAPTCHA*CHAR_SET_LEN) 42 def char2pos(c): 43 if c =='_': 44 k = 62 45 return k 46 k = ord(c)-48 47 if k > 9: 48 k = ord(c) - 55 49 if k > 35: 50 k = ord(c) - 61 51 if k > 61: 52 raise ValueError('No Map') 53 return k 54 for i, c in enumerate(text): 55 idx = i * CHAR_SET_LEN + char2pos(c) 56 vector[idx] = 1 57 return vector 58 59 # 向量转回文本 60 def vec2text(vec): 61 char_pos = vec.nonzero()[0] 62 text = [] 63 for i, c in enumerate(char_pos): 64 char_at_pos = i # c/63 65 char_idx = c % CHAR_SET_LEN 66 if char_idx < 10: 67 char_code = char_idx + ord('0') 68 elif char_idx < 36: 69 char_code = char_idx - 10 + ord('A') 70 elif char_idx < 62: 71 char_code = char_idx - 36 + ord('a') 72 elif char_idx == 62: 73 char_code = ord('_') 74 else: 75 raise ValueError('error') 76 text.append(chr(char_code)) 77 return "".join(text) 78 79 def get_next_batch(batch_size=64): 80 batch_x = np.zeros([batch_size, IMAGE_HEIGHT * IMAGE_WIDTH]) 81 batch_y = np.zeros([batch_size, MAX_CAPTCHA * CHAR_SET_LEN]) 82 83 # 有时生成图像大小不是(60,160,3) 84 def wrap_get_label_and_image(): 85 # 获取一张图,判断其是否符合(60,160,3) 86 while True: 87 text, image = gen_captcha_text_and_image() 88 if image.shape == (60, 160, 3): 89 return text, image 90 91 for i in range(batch_size): 92 text, image = gen_captcha_text_and_image() 93 batch_x[i, :] = image.flatten() # 将二维数组拉平为一维 94 batch_y[i, :] = text2vec(text) 95 96 return batch_x, batch_y 97 98 # 把彩色图像转为灰度图像(色彩对识别验证码没有什么用) 99 def convert2gray(img): 100 if len(img.shape) > 2: 101 gray = np.mean(img, -1) 102 # 上面的转法较快,正规转法如下 103 # r, g, b = img[:,:,0], img[:,:,1], img[:,:,2] 104 # gray = 0.2989 * r + 0.5870 * g + 0.1140 * b 105 return gray 106 else: 107 return img 108 109 def crack_captcha_cnn(w_alpha=0.01, b_alpha=0.1): 110 x = tf.reshape(X, shape=[-1, IMAGE_HEIGHT, IMAGE_WIDTH, 1]) 111 112 # 第一层卷积-池化 113 w_c1 = tf.Variable(tf.random_normal([3, 3, 1, 32], stddev=w_alpha)) 114 b_c1 = tf.Variable(tf.random_normal([32], stddev=b_alpha)) 115 conv1 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(x, w_c1, strides=[1, 1, 1, 1], padding='SAME'), b_c1)) 116 conv1 = tf.nn.max_pool(conv1, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') 117 conv1 = tf.nn.dropout(conv1, keep_prob) 118 119 # 第二层卷积-池化 120 w_c2 = tf.Variable(tf.random_normal([3, 3, 32, 64], stddev=w_alpha)) 121 b_c2 = tf.Variable(tf.random_normal([64], stddev=b_alpha)) 122 conv2 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(conv1, w_c2, strides=[1, 1, 1, 1], padding='SAME'), b_c2)) 123 conv2 = tf.nn.max_pool(conv2, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') 124 conv2 = tf.nn.dropout(conv2, keep_prob) 125 126 # 第三层卷积-池化 127 w_c3 = tf.Variable(tf.random_normal([3, 3, 64, 64], stddev=w_alpha)) 128 b_c3 = tf.Variable(tf.random_normal([64], stddev=b_alpha)) 129 conv3 = tf.nn.relu(tf.nn.bias_add(tf.nn.conv2d(conv2, w_c3, strides=[1, 1, 1, 1], padding='SAME'), b_c3)) 130 conv3 = tf.nn.max_pool(conv3, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME') 131 conv3 = tf.nn.dropout(conv3, keep_prob) 132 133 # 全连层 134 w_d = tf.Variable(tf.random_normal([8 * 32 * 40, 1024], stddev=w_alpha)) 135 b_d = tf.Variable(tf.random_normal([1024], stddev=b_alpha)) 136 dense = tf.reshape(conv3, [-1, w_d.get_shape().as_list()[0]]) 137 dense = tf.nn.relu(tf.add(tf.matmul(dense, w_d), b_d)) 138 dense = tf.nn.dropout(dense, keep_prob) 139 140 # 输出层 141 w_out = tf.Variable(tf.random_normal([1024, MAX_CAPTCHA * CHAR_SET_LEN], stddev=w_alpha)) 142 b_out = tf.Variable(tf.random_normal([MAX_CAPTCHA * CHAR_SET_LEN], stddev=b_alpha)) 143 out = tf.add(tf.matmul(dense, w_out), b_out) 144 return out 145 146 def train_crack_captcha_cnn(): 147 output = crack_captcha_cnn() 148 # loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(output, Y)) 149 loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=output, labels=Y)) 150 # 最后一层用来分类的softmax和sigmoid,可以自己选择 151 # optimizer 为了加快训练 learning_rate应该开始大,然后慢慢衰 152 optimizer = tf.train.AdamOptimizer(learning_rate=0.001).minimize(loss) 153 154 predict = tf.reshape(output, [-1, MAX_CAPTCHA, CHAR_SET_LEN]) 155 max_idx_p = tf.argmax(predict, 2) 156 max_idx_l = tf.argmax(tf.reshape(Y, [-1, MAX_CAPTCHA, CHAR_SET_LEN]), 2) 157 correct_pred = tf.equal(max_idx_p, max_idx_l) 158 accuracy = tf.reduce_mean(tf.cast(correct_pred, tf.float32)) 159 160 saver = tf.train.Saver() 161 with tf.Session() as sess: 162 sess.run(tf.global_variables_initializer()) 163 164 step = 0 165 while True: 166 batch_x, batch_y = get_next_batch(64) 167 sess.run(optimizer, feed_dict={X: batch_x, Y: batch_y, keep_prob: 0.8}) 168 # 每10 step计算一次准确率 169 if step % 10 == 0: 170 batch_x_test, batch_y_test = get_next_batch(100) 171 acc, loss_ = sess.run([accuracy, loss], feed_dict={X: batch_x_test, Y: batch_y_test, keep_prob: 0.8}) 172 print("step=%d, loss=%g, acc=%g"%(step, loss_, acc)) 173 saver.save(sess, "./model/crack_capcha1.model", global_step=step) 174 # 如果准确率大于98%,保存模型,完成训练 175 if acc > 0.9: 176 saver.save(sess, "./model/crack_capcha.model", global_step=step) 177 break 178 step += 1 179 180 181 182 def crack_captcha(captcha_image): 183 output = crack_captcha_cnn() 184 185 saver = tf.train.Saver() 186 with tf.Session() as sess: 187 saver.restore(sess, r"F:pyProgramverification_codemodelcrack_capcha1.model-52000") 188 189 predict = tf.argmax(tf.reshape(output, [-1, MAX_CAPTCHA, CHAR_SET_LEN]), 2) 190 text_list = sess.run(predict, feed_dict={X: [captcha_image], keep_prob: 1}) 191 # text_list = sess.run(predict, feed_dict={X: [captcha_image]}) 192 193 text = text_list[0].tolist() 194 vector = np.zeros(MAX_CAPTCHA*CHAR_SET_LEN) 195 i = 0 196 for n in text: 197 vector[i*CHAR_SET_LEN + n] = 1 198 i += 1 199 return vec2text(vector) 200 201 if __name__ == '__main__': 202 # 图像大小 203 IMAGE_HEIGHT = 60 204 IMAGE_WIDTH = 160 205 MAX_CAPTCHA = 4 206 print("验证码文本字符数", MAX_CAPTCHA) 207 char_set = number + alphabet + ALPHABET 208 # char_set = number 209 CHAR_SET_LEN = len(char_set) 210 211 X = tf.placeholder(tf.float32, [None, IMAGE_HEIGHT * IMAGE_WIDTH]) 212 Y = tf.placeholder(tf.float32, [None, MAX_CAPTCHA * CHAR_SET_LEN]) 213 keep_prob = tf.placeholder(tf.float32) # dropout 214 215 # train_crack_captcha_cnn() 216 root = tkinter.Tk() 217 root.withdraw() 218 default_dir = r"C:UsersanimatorDesktop" 219 file_path = tkinter.filedialog.askopenfilename(title=u'选择文件', initialdir=(os.path.expanduser(default_dir))) 220 image = Image.open(file_path) 221 plt.imshow(image) 222 image = np.array(image) 223 image = convert2gray(image) 224 image = image.flatten() / 255 225 print("预测结果:"+crack_captcha(image)) 226 plt.show()
为了防止错过最佳训练模型,对每个训练模型都进行了保存,后来在出现92.25%的训练结果后手动结束了程序,训练过程如下:
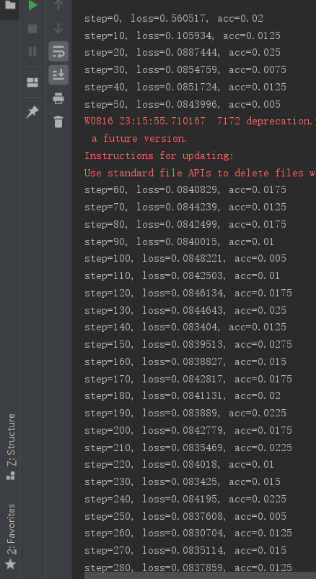
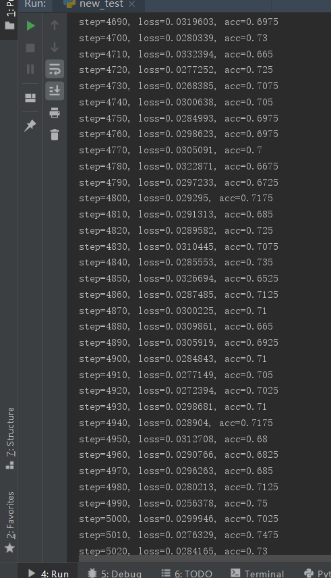

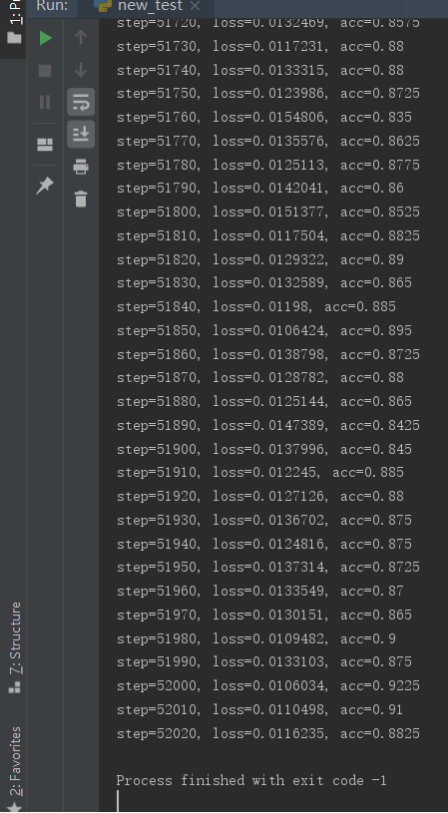
可见第52000次训练结果0.9225
删掉多余的训练模型后剩余
测试结果(图片位于桌面,百度随机下载的一张验证码图片)


图片中验证码为1TjV,但是识别结果为1TJY,大小写识别和部分易混淆字母识别不准确
解决思路:由于神经网络训练模型单个数字或字母的识别率很高,且模型训练较容易,可以增加图片的分割操作将所有字符一个一个的分开识别,这样的好处一是提高识别精度,二是避免验证码字符个数限制,可以识别任意个字符组成的验证码
目前只有思路,时间问题还未具体实践
java的学生管理系统样卷内容和小学期进行的学生管理系统差别不大,用Java代码实现起来也非常简单,这里不再列出其代码
除此之外,还实验了支持下载队列的多线程网络爬虫,代码如下:
1 from urllib import request 2 import re 3 from bs4 import BeautifulSoup 4 from time import ctime,sleep 5 import os,sys,io 6 import threading 7 # 在当前目录创建一个urls子目录,用于保存下载的HTML文件 8 os.makedirs('urls',exist_ok=True) 9 # 下载队列,入口点的URL会作为下载队列的第一个元素,这里以“极客教程”网站为例 10 insertURL = ["https://geekori.com"] 11 # 已经处理完的URL会添加到这个队列中 12 delURL = [] 13 # 负责下载和分析的HTML代码的函数,该函数会在多个线程中执行 14 def getURL(): 15 while(1): 16 global insertURL 17 global delURL 18 try: 19 if len(insertURL)>0: 20 # 从队列头取一个URL 21 html = request.urlopen(insertURL[0]).read() 22 soup = BeautifulSoup(html,'lxml') 23 # 开始分析HTML代码 24 title = soup.find(name='title').get_text().replace(' ','') 25 fp = open("./urls/"+str(title)+".html","w",encoding='utf-8') 26 # 将HTML代码保存到相应的文件中 27 fp.write(str(html.decode('utf-8'))) 28 fp.close() 29 # 开始查找所有的a标签 30 href_ = soup.find_all(name='a') 31 # 对所有的a标签进行迭代 32 for each in href_: 33 urlStr = each.get('href') 34 if str(urlStr)[:4]=='http' and urlStr not in insertURL: 35 # 添加所有以http开头并且没有处理过的URL 36 insertURL.append(urlStr) 37 print(urlStr) 38 # 将处理完的URL添加到delURL队列中 39 delURL.append(insertURL[0]) 40 # 删除inserURL中处理完的URL 41 del insertURL[0] 42 except: 43 delURL.append(insertURL[0]) 44 del insertURL[0] 45 continue 46 sleep(2) 47 # 下面的代码启动了三个线程运行getURL函数 48 threads = [] 49 t1 = threading.Thread(target=getURL) 50 threads.append(t1) 51 t2 = threading.Thread(target=getURL) 52 threads.append(t2) 53 t3 = threading.Thread(target=getURL) 54 threads.append(t3) 55 56 if __name__=='__main__': 57 for t in threads: 58 t.setDaemon(True) 59 t.start() 60 for tt in threads: 61 tt.join()
运行效果如图:

urls目录下以下载的文件如图:
OK,以上就是本周所有内容了,往后几周将会复习巩固暑假的进度,准备开学的考核,加油!