导航
第十章 Collections
10.1 概述
在第7章,"数组"里,我们已经介绍了Array类实现的数组和接口。这种数组是定长的(fixed)。假如你想动态的设置元素的个数,你需要使用集合类而非数组。
List<T>是一个集合类,我们可以用来跟数组进行比较。当然我们还有很多其他类型的集合类,如:队列,栈,链表,字典和数据集(set)。这些不同的集合类有着不同的API访问各自集合中的元素,并且它们在内存中存储元素的内部结构也往往不同。本章将会介绍这些集合类以及它们的区别,包括性能差异。
10.2 集合接口和类型
大部分的泛型类都位于System.Collections或者System.Collections.Generic命名空间下,其中泛型集合类主要位于后者。专门为某些特定类型服务的集合类位于System.Collections.Specialized命名空间下,如BitVector32、HybridDictionary等。线程安全(Thread-safe)的集合类则是位于System.Collections.Concurrent命名空间下。不可变(ImmutableCollection)的集合类位于System.Collections.Immutable命名空间下。
当然,也有其他的方式来为集合进行归类。集合类也可以根据其所实现的不同集合类接口而分为列表、集合与字典。
注意:你可以在第七章的时候了解到更多关于IEnumerable和IEnumerator接口的详细信息。
下面的表格描述了集合和列表实现的大部分重要接口:
| 接口 | 描述 |
|---|---|
| IEnumerable<T> | foreach语句实现的需要。 定义了GetEumerator方法,返回 IEnumerator类型的迭代器。 |
| ICollection<T> | 泛型集合类实现的接口。 接口定义了Count属性用来获取集合 的元素数量,定义了Copy方法将集 合拷贝成一个数组,定义了添加、删 除、清理元素的方法。 |
| IList<T> | 列表实现的接口,提供了按位置访问 元素的能力。接口定义了索引器,可 以很方便地插入和移除元素。接口继 承自ICollection<T>。 |
| ISet<T> | 数据集实现的接口。数据集允许多个 不同的数据集形成一个联合数据集。 获取两个数据集之间的交集,检车它 们之间是否有重叠的部分。接口也继 承自ICollection<T>。 |
| IDictionary<TKey,TValue> | 接口由带有Key和Value键值对的泛型 集合类实现。通过接口你可以访问键 值对,也可以通过索引器进行访问, 同样也可以添加或删除元素。 |
| ILookup<TKey,TValue> | 跟上面的IDictionary<TKey,TValue> 有点相似,本接口也包含键值对。然 而不同的是上面的接口是一一对应的 ,而本接口一个Key可以对应多个Value。 |
| IComparer<T> | 本接口通过实现一个比较器,可以通过 Compare方法对集合类中的元素进行排 序。 |
| IEqualityComparer<T> | 实现了一个可以应用字典中键值的比较 器,通过本接口你可以比较objects。 |
10.3 列表
对于允许任意元素个数(resizable)的List,.NET提供了泛型类型List<T>,这个类实现了IList,ICollection,IEnumerable, IList<T>,ICollection<T>以及IEnumerable<T>接口。
接下来的例子中,我们将使用Racer类作为成员元素,添加到一个代表一级方程式赛车手(represent a Formula-1 racer)的集合中。Racer类含有5个属性:Id,FirstName,LastName,Country和Wins(胜利次数)。通过构造函数,我们可以为所有属性都赋初值。我们将重写ToString方法来返回赛车手的全名。Racer类还实现了IComparable<T>接口方便后续排序,并且也实现了IFormattable接口。代码如下所示:
public class Racer: IComparable<Racer>, IFormattable
{
public int Id { get; }
public string FirstName { get; }
public string LastName { get; }
public string Country { get; }
public int Wins { get; }
public Racer(int id, string firstName, string lastName, string country) :this(id, firstName, lastName, country, wins: 0)
{ }
public Racer(int id, string firstName, string lastName, string country,int wins)
{
Id = id;
FirstName = firstName;
LastName = lastName;
Country = country;
Wins = wins;
}
public override string ToString() => $"{FirstName} {LastName}";
public string ToString(string format, IFormatProvider formatProvider)
{
if (format == null) format = "N";
switch (format.ToUpper())
{
case "N": // name
return ToString();
case "F": // first name
return FirstName;
case "L": // last name
return LastName;
case "W": // Wins
return $"{ToString()}, Wins: {Wins}";
case "C": // Country
return $"{ToString()}, Country: {Country}";
case "A": // All
return $"{ToString()}, Country: {Country} Wins: {Wins}";
default:
throw new FormatException(String.Format(formatProvider, $"Format {format} is not supported"));
}
}
public string ToString(string format) => ToString(format, null);
public int CompareTo(Racer other)
{
int compare = LastName?.CompareTo(other?.LastName) ?? -1;
if (compare == 0)
{
return FirstName?.CompareTo(other?.FirstName) ?? -1;
}
return compare;
}
}
10.3.1 创建列表
你可以通过调用默认的构造函数创建List对象。如果是通过泛型类List<T>进行创建的话,你需要事先声明列表元素的值类型。下面的代码分别创建了一个int类型和Racer类型的列表。多提一句,ArrayList是一个非泛型的列表,它允许任何类型成为它的元素。
var intList = new List<int>();
var racers = new List<Racer>();
使用默认构造函数将会创建一个空列表。一旦第一个元素开始添加到列表,列表的容量会首先扩展到4个元素。当第5个元素需要添加时,它的容量将会扩展到8个,假如8个还不够,就接着扩展到16,每次都是翻倍地扩容。
每当列表的容量改变的时候,整个集合将会在内存区重新进行分配。List<T>实际上是创建了一个T类型的数组。每次需要重新分配内存时,一个新的数组就会被创建,并且使用Array.Copy方法从旧的数组将值拷贝到新数组中。为了节省时间,假如你事先能知道列表的元素数量的话,你可以通过构造函数提前设置列表的大小。下面这段代码就是设置了列表元素数量为10。但当你要添加更多的元素时,它的容量将会先扩成20,然后40,依然是翻倍扩容:
List<int> intList = new List<int>(10);
你可以通过列表的Capacity属性来得到它当前的容量,当然你也可以修改它:
intList.Capacity = 20;
Capacity属性并非和集合里当前拥有的元素数量一致,你可以通过Count属性来获取集合里当前拥有的元素数量。当然,Capacity的数值永远大于等于Count值。当集合中未添加任何元素时,Count值为0:
Console.WriteLine(intList.Count);
当你已经完成所有列表元素的添加并且不想再添加新的了,你可以通过调用TrimExcess方法来移除没有用到的容量;然而,因为移除容量也会造成内存的重新分配,因此当实际元素数量超过集合容量的90%的时候,该方法不起效:
intList.TrimExcess();
10.3.1.1 集合初始化器
你可以在集合初始化的时候直接给它赋值,语法和数组的赋值很像,通过大括号将值括起来进行赋值,如下所示:
var intList = new List<int>() {1, 2};
var stringList = new List<string>() { "one", "two" };
注意:这种赋值方式并不会在程序集中生成特别的IL代码,编译器仅仅只是为每一个指定的元素都分别调用了Add方法。
10.3.1.2 新增元素
你可以像下面的例子这样,通过Add方法为列表新增元素,泛型版本的列表也定义了Add方法:
var intList = new List<int>();
intList.Add(1);
intList.Add(2);
var stringList = new List<string>();
stringList.Add("one");
stringList.Add("two");
下面定义的变量racers是List<Racer>类型的列表,通过new操作符进行创建。因为List<T>类已经以明确的类型Racer进行实例化了,现在只有Racer实例对象才可以通过Add方法添加到racers列表中。在下面的示例代码里,我们创建了5个一级方程式赛车手的信息并将他们添加到集合里。前面3位选手我们通过初始化直接进行添加,而后两位选手则显示地调用了Add方法:
var graham = new Racer(7, "Graham", "Hill", "UK", 14);
var emerson = new Racer(13, "Emerson", "Fittipaldi", "Brazil", 14);
var mario = new Racer(16, "Mario", "Andretti", "USA", 12);
var racers = new List<Racer>(20) {graham, emerson, mario};
racers.Add(new Racer(24, "Michael", "Schumacher", "Germany", 91));
racers.Add(new Racer(27, "Mika", "Hakkinen", "Finland", 20));
你也可以使用AddRange方法来一次性为集合添加多个元素,因为该方法允许接收IEnumerable<T>类型的参数,因此你可以像下面代码这样直接给它传递一个数组:
racers.AddRange(new Racer[] {
new Racer(14, "Niki", "Lauda", "Austria", 25),
new Racer(21, "Alain", "Prost", "France", 51)});
注意:集合初始化器(collection initializer)的赋值方式仅仅只能在声明集合的时候使用。而Add和AddRange方法则是在集合初始化之后再进行调用。万一你需要根据数据动态地创建集合,你需要调用Add或者AddRange方法。
如果你在实例化列表的时候已经知道某些元素会属于该列表,你也可以直接向构造函数传递IEnumerable<T>类型的参数,这点和AddRange方法非常类似:
var racers = new List<Racer>(
new Racer[] {
new Racer(12, "Jochen", "Rindt", "Austria", 6),
new Racer(22, "Ayrton", "Senna", "Brazil", 41) });
10.3.1.3 插入元素
你可以使用Insert方法在指定位置插入元素:
racers.Insert(3, new Racer(6, "Phil", "Hill", "USA", 3));
而InsertRange方法则提供了插入多个元素的能力,它的使用方式和AddRange方法很像。假如你要插入的位置远大于集合允许的元素数量,将会引发ArgumentOutOfRangeException异常。
10.3.1.4 访问元素
所有实现了IList和IList<T>的类都提供了一个索引器,可以通过传递元素的序号访问指定元素。第一个元素的序号为0,因此当你指定racers[3]的时候,实际上你访问的是列表中的第4个元素:
Racer r1 = racers[3];
当你使用Count属性来获取元素数量的时候,你可以通过一个循环来遍历集合中的所有元素,因为你可以通过索引器访问每一个元素:
for (int i = 0; i < racers.Count; i++)
{
Console.WriteLine(racers[i]);
}
注意:索引可以在ArrayList,StringCollections和
List<T>中使用。
因为List<T>实现了IEnumerable接口,你也可以通过foreach语句来遍历集合里的所有元素:
foreach (var r in racers)
{
Console.WriteLine(r);
}
注意:第7章的时候阐释了foreach语句在编译器中实际上是如何转换成IEnumerable和IEnumerator接口的。
10.3.1.5 移除元素
你可以通过索引号来从队列里移除元素,例如下面代码移除的是第4个元素:
racers.RemoveAt(3);
你也可以通过Remove方法,给它直接传递一个Racer对象作为参数,来删除指定的元素。通过索引删除的速度更快一些,因为在删除的时候,集合需要对待删除的元素进行查找。Remove方法首先通过IndexOf方法获取元素在集合中的索引,然后再进行删除。IndexOf方法则会首先检查元素类型是否实现了IEquatable<T>接口,假如它实现了该接口,那么就会遍历集合中的所有元素,调用该接口的Equals方法进行一一比较,找出相等的元素,返回它的序号。假如元素未实现IEquatable<T>接口,则会调用基类Object的Equals方法进行比较,默认的Equals方法虽然在比较值类型上尚有可取之处,但是在比较对象的时候仅仅只比较它们之间的引用是否指向同一个位置。
注意:第6章,"操作符和强制转换"中介绍了如何重写基类的Equals方法。
在下面的例子中,我们将会从集合中移除变量graham引用的racer对象,这个变量是我们前面填充集合的时候创建的。因为Racer类并未实现IEquatable<T>接口,也没有重写Object.Equals方法,因此你无法通过创建一个同样内容的新对象当成参数传递给Remove方法来移除它,即使新对象内的属性都与它一模一样:
if (!racers.Remove(newGraham)) //原文这里是graham,但这个对象集合里本来就有,可以移除
{
Console.WriteLine("object not found in collection");
}
RemoveRange方法可以一次性从集合里移除多个元素。该方法第一个参数指定了要开始移除的位置,第二个参数则是待删除元素的个数:
int index = 3;
int count = 5;
racers.RemoveRange(index, count);
假如你想移除集合里的某些指定特征(specific characteristics)的元素,你可以使用RemoveAll方法,这个方法使用了Predicate<T>类型的参数来查找元素,我们会在下一小节详细介绍它。如果要移除所有元素,你可以使用ICollection<T>接口中定义的Clear方法。
10.3.2 检索
在集合中查找指定元素有多种方式。你可以通过索引来查找元素,或者通过元素本身查找索引。你可以使用的方法有很多,譬如:IndexOf,LastIndexOf,FindIndex,FindLastIndex,Find和FindLast。而如果要判断某个元素是否存在,你可以使用Exists方法。
IndexOf方法接收一个实例对象作为参数,假如能在集合中找到它,则返回该元素在集合中的索引,假如不存在,则返回-1。请记住IndexOf方法使用的是IEquatable<T>接口来比较元素:
int index1 = racers.IndexOf(mario);
IndexOf方法也支持只对部分集合进行搜索,通过指定搜索的起始位置和元素数量,可以只搜索部分元素。
除了IndexOf方法,你也可以使用FindIndex方法根据指定特征来搜索某个元素,它接收一个Predicate<T>类型的参数:
public int FindIndex(Predicate<T> match);
Predicate<T>类型是一个委托,接收T类型的参数,并返回一个布尔值。假如返回的是true,意味着条件匹配,找到了满足需要的元素,假如返回的是false,则当前元素不符合条件,接着进行查找:
public delegate bool Predicate<T>(T obj);
以上面我们创建的List<Racer>为例子,你可以为FindIndex方法传递一个T类型为Racer的委托作为参数,该委托接收一个Racer类型的参数并且返回一个bool值。如下面代码所示:
public class FindCountry
{
public FindCountry(string country) => _country = country;
private string _country;
public bool FindCountryPredicate(Racer racer) => racer?.Country == _country;
}
该代码用来查找某个国家的第一个赛车手,FindCountry类里的FindCountryPredicate方法签名和返回值都满足Predicate<T>委托类型,通过使用构造函数传递过来的变量country来进行查找。
在FindIndex方法中,你可以创建一个FindCountry类的新实例,在构造函数中传递你要查询的国家,然后将FindCountryPredicate方法地址作为参数传递给FindIndex,如下所示:
int index2 = racers.FindIndex(new FindCountry("Finland").FindCountryPredicate);
当存在Finland这个国家的赛车手时,index2将会被设置成racers列表中第一个满足条件的赛车手的索引。
如果你不想大费周章地创建一个带有委托方法的新类,你也可以在这里使用lambda表达式,结果跟前面也是一致的。如下所示:
int index3 = racers.FindIndex(r => r.Country == "Finland");
与IndexOf方法一样,你也可以为FindIndex方法指定开始查找的起始位置,你也可以使用FindLastIndex方法来从后往前搜索。
FindIndex方法返回的是满足搜索条件的元素的序号。你也可以直接通过Find方法获取集合中的元素而非它的序号。Find方法同样接收一个Predicate<T>委托类型的参数。考虑下面这个示例:
Racer racer = racers.Find(r => r.FirstName == "Niki");
它查找的是FirstName为Niki的第一个赛车手。当然,你也可以通过FindLast方法来查找满足搜索条件的最后一个元素。
假如你不仅仅只是为了得到某一个满足条件的结果,而是需要查找所有符合条件的元素的话,你可以使用FindAll方法,它使用同样的委托参数,但当找到第一个满足条件的元素时它不会停下来,它会持续遍历整个集合,为每一个元素进行匹配并进行输出。在下面的例子里,我们查找的是所有Wins次数大于20的选手,并且将它们加到bigWinners列表中:
List<Racer> bigWinners = racers.FindAll(r => r.Wins > 20);
通过foreach语句遍历bigWinners:
foreach (Racer r in bigWinners)
{
Console.WriteLine($"{r:A}");
}
你可以看到:
Michael Schumacher, Germany Wins: 91
Niki Lauda, Austria Wins: 25
Alain Prost, France Wins: 51
这个结果没有进行排序,但你会在下一节中看到如何处理它。
注意:格式化字符(Format specifiers)和IFormattable接口的细节我们在第9章,"字符串和正则表达式"中已经介绍过。
10.3.3 排序
List<T>类允许你使用Sort方法来对它包含的元素进行排序。Sort方法使用的是快速排序算法。你可以使用多个Sort方法的重载版本,它的参数可以是泛型委托Comparison<T>、泛型接口IComparer<T>或者带上指定范围等等:
public void List<T>.Sort();
public void List<T>.Sort(Comparison<T>);
public void List<T>.Sort(IComparer<T>);
public void List<T>.Sort(Int32, Int32, IComparer<T>);
只有当集合中的元素实现了IComparable接口时你才可以直接使用无参的Sort方法。在这里,Racer类实现了IComparable<T>接口来通过LastName进行排序:
racers.Sort();
假如你想使用默认支持方式以外的排序,你需要使用其他的技巧,譬如传递一个实现了IComparer<T>接口的对象。考虑下面的代码:
public class RacerComparer : IComparer<Racer>
{
public enum CompareType
{
FirstName,
LastName,
Country,
Wins
}
private CompareType _compareType;
public RacerComparer(CompareType compareType)
{
_compareType = compareType;
}
public int Compare(Racer x, Racer y)
{
if (x == null && y == null) return 0;
if (x == null) return -1;
if (y == null) return 1;
int result;
switch (_compareType)
{
case CompareType.FirstName:
return string.Compare(x.FirstName, y.FirstName);
case CompareType.LastName:
return string.Compare(x.LastName, y.LastName);
case CompareType.Country:
result = string.Compare(x.Country, y.Country);
if (result == 0)
return string.Compare(x.LastName, y.LastName);
else
return result;
case CompareType.Wins:
return x.Wins.CompareTo(y.Wins);
default:
throw new ArgumentException("Invalid Compare Type");
}
}
}
RacerComparer类为Racer类实现了IComparer<T>接口,它使得你可以通过姓氏,名字,国家或者胜场来进行排序。这种排序实际上是由内置的枚举变量CompareType实现的。CompareType则是在RacerComparer类的构造函数里进行设置。IComparer<T>接口定义了在排序过程中实际调用的比较方法Compare。在上面实现的Compare以及内部调用的CompareTo方法中,我们用到了string和int类型。
注意:当传递给Compare方法的两个元素相等的时候,它返回0。如果方法返回的是负数,就意味着第一个参数比第二个参数小,反之则意味着第一个参数比第二个参数大。参数为null的时候也做了处理,我们认为null比任何值都小,除非两个参数都为null的时候他们才相等。否则仅当第一个参数为null时,则会返回-1;而仅当第二个参数为null时,则返回+1。
你可以在Sort方法里使用RacerComparer的实例,如下所示,我们将RacerComparer.CompareType.Country传递给了构造函数,这样我们的排序就是通过Country属性来进行的:
racers.Sort(new RacerComparer(RacerComparer.CompareType.Country));
另外一种排序的方式是使用List<T>中重载的Sort方法,它需要一个Comparison<T>委托作为参数:
public void List<T>.Sort(Comparison<T>);
Comparison<T>委托拥有两个T类型的参数,并返回int类型。假如两个参数相等,返回值必须是0;假如第一个参数小于第二个参数,应该返回一个负值;反过来则返回一个正数。
public delegate int Comparison(T x, T y);
现在你可以像下面这样子,通过给Sort方法传递一个lambda表达式来完成根据胜场进行的排序:
racers.Sort((r1, r2) => r2.Wins.CompareTo(r1.Wins));
两个参数是Racer类型的,通过CompareTo方法里对胜场Wins属性进行比较并返回一个int值来实现整个比较过程。在这个方法实现当中,r2和r1的次序跟参数顺序是反过来的,因此最终得到的是一个倒序排序的结果。当这个方法被调用过后,racers列表中就是按照胜场进行排序的了。
你还可以通过调用Reverse方法,来把整个集合调转,例如上面得到的胜场倒序排列的列表,对它调用Reverse之后,你就得到按胜场正序排列的列表了。
10.3.4 只读集合
当你创建完集合后,他们通常是可以读写的,否则你无法用任何值来填充他们。然而,当你填充完你的集合之后,你可以通过它创建一个只读的集合。举个例子,你可以通过调用List<T>的AsReadOnly方法来返回一个ReadOnlyCollection类型的对象。ReadOnlyCollection类跟List<T>实现了同样的接口,然而任何试图修改ReadOnlyCollection实例的操作都会导致一个NotSupportedExcception。除了实现List<T>的接口之外,ReadOnlyCollection类还实现了IReadOnlyCollection<T>和IReadOnlyList<T>接口,通过这些接口成员,最终实现了ReadOnlyCollection的只读性。
10.4 队列
队列是一种先进先出(FIFO,First In First Out)的元素集合,这意味着第一个进入队列的元素会第一个被读取。在我们生活中有很多队列的例子,如飞机场的航班,HR处理员工申请,打印机里的打印队列,循环等待CPU响应的线程等等。有时候,队列里的元素拥有不同的优先级。举个例子,在一趟航班中,商务舱的旅客可以比经济舱的旅客更早登机。在这种情况下,我们就需要根据优先级使用不同的队列。事实上在机场登机的时候,商务舱和经济舱的旅客有不同的检票口。同样地,对于打印任务和线程来说,也可以类似地进行处理。你可以创建不同队列,根据优先级来将相同优先级的条目(item)置于同一队列中。只是在每个队列内部,因为优先级是一致的,它们依然遵循FIFO原则进行处理。
注意:在本章稍后的部分会介绍一种不同的链表实现,用来定义一组优先级。
队列通过定义在System.Collections.Generic命名空间下的Queue<T>来实现。在它内部,实际上是定义了一个T类型的数组,跟前面提到的List<T>实现很像。同样地,队列实现了IEnumerable和ICollcection接口,但是它没有实现ICollection<T>接口,因为其中定义的Add和Remove方法不适合队列使用。
Queue<T>没有实现IList<T>接口,所以你无法通过索引来访问队列。队列仅允许你通过Enqueue方法,为其在队尾增加一个元素,或者通过Dequeue方法移除队头第一个元素。Dequeue方法获取到队头第一个元素,并将其从队列里移除。再次调用Dequeue方法则会接着移除下一个元素。
Queue<T>类的部分成员如下表所示:
| 部分成员 | 描述 |
|---|---|
| Count | 返回队列元素的个数。 |
| Enqueue | 在队列末尾增加一个元素。 |
| Dequeue | 从队列队头读取一个元素并将其从队列里移除。 如果队列没有任何元素,将会抛出一个异常。 |
| Peek | 从队列队头读取一个元素,但并不移除。 |
| TrimExcess | 调整队列的容量,虽然Dequeue方法会移除队列 元素,但它并不会调整队列的容量。如果要回收 那些空元素占用的内存空间的话,调用本方法。 |
创建队列的构造函数,跟List<T>类型很像。你可以通过无参构造函数来创建一个空队列,也可以在构造函数里直接指定队列的容量。假如你没有指定队列的容量,当新增的元素超过队列的大小时,那么队列大小就会按4,8,16,32这样子依次递增。跟List<T>类很像,容量每次都是翻倍地增加。非泛型版本的Queue类有一点点不同,它的无参构造函数默认创建的是一个初始容量为32的空数组。通过其它重载的构造函数,你可以将实现了IEnumerable<T>接口的集合直接作为参数进行传递,集合的元素会被拷贝到队列中。
下面这个示例演示了,如何使用Queue<T>类来创建一个文档管理程序。一个线程用来给队列添加文档,而另一个线程则从队列里读取文档并进行相应的处理。
存储在队列里的T类型是Document,它定义了title和content属性,如下所示:
public class Document
{
public string Title
{
get;
}
public string Content
{
get;
}
public Document(string title, string content)
{
Title = title;
Content = content;
}
}
DocumentManager类则是在Queue<T>上浅浅地封装了一层。它定义了如何处理文档:通过AddDocument方法来将文档添加到队列中,而从队列中获取文档则是通过GetDocument方法。
在AddDocument方法内部,文档通过Enqueue方法添加到队列的队尾。而GetDocument则是通过Dequeue方法来读取队列的第一份文档。因为有多个线程可能同时访问DocumentManager类,因此对队列的访问我们使用了lock语句。
注意:多线程和lock语句将于第21章,"任务和并行编程"进行介绍。
IsDocumentAvailable是一个只读的Boolean类型属性,如果队列里有文档,则返回true,否则返回false。整个示例代码如下所示:
public class DocumentManager
{
private readonly object _syncQueue = new object();
private readonly Queue<Document> _documentQueue = new Queue<Document>();
public void AddDocument(Document doc)
{
lock(_syncQueue)
{
_documentQueue.Enqueue(doc);
}
}
public Document GetDocument()
{
Document doc = null;
lock(_syncQueue)
{
doc = _documentQueue.Dequeue();
}
return doc;
}
public bool IsDocumentAvailable => _documentQueue.Count > 0;
}
ProcessDocuments类在不同的任务里对队列里的文档进行了处理,唯一可以给外部进行调用的方法是Start。在Start方法中,会实例化一个新任务。为了启动任务,我们创建了一个ProcessDocuments对象实例,并且调用了它的Run方法作为Task的启动点,代码如下所示:
public class ProcessDocuments
{
public static Task Start(DocumentManager dm) => Task.Run(new ProcessDocuments(dm).Run);
protected ProcessDocuments(DocumentManager dm) => _documentManager = dm ? ?
throw new ArgumentNullExcption(nameof(dm));
private DocumentManager _documentManager;
protected async Task Run()
{
while(true)
{
if(_documentManager.IsDocumentAvailable)
{
Document doc = _documentManager.GetDocument();
Console.WriteLine("Processing document {0}", doc.Title);
}
await Task.Delay(new Random().Next(20));
}
}
}
为了能更好地理解书里的意思,这里我们补充一下Task里的Run方法实现:
public static Task<TResult> Run<TResult>(Func<TResult> function)
=>
Task<TResult>.StartNew(null, function
, new CancellationToken()
, TaskCreationOptions.DenyChildAttach
, InternalTaskOptions.None
, TaskScheduler.Default);
书中提到了TaskFactory的StartNew方法,我们也一并看看:
public Task<TResult> StartNew<TResult>(Func<TResult> function)
{
Task internalCurrent = Task.InternalCurrent;
return Task<TResult>.StartNew(internalCurrent, function,
this.m_defaultCancellationToken,
this.m_defaultCreationOptions,
InternalTaskOptions.None,
this.GetDefaultScheduler(internalCurrent));
}
抛开我们补充的这俩段代码,书中是这么说的:TaskFactory(通过Task类的静态属性Factory进行访问)中的StartNew方法需要一个Action委托类型的参数,Run方法的地址传给它正好合适。TaskFactory中的StartNew方法会马上启动整个任务。事实上我在跟踪调试的时候,并没有进到TaskFactory中去,我觉着这段可能串了,作者可能想解释的是Task的Run方法。先不管这里,我们接着往下看。
通过ProcessDocuments类的Run方法,我们构造了一个无限循环(endless loop)。在这个循环中,IsDocumentAvailable属性用来确定队列里是否还有文档。假如有,它就可以被DocumentManager取走并进行处理。尽管在本例中的处理信息都显示在控制台上,在实际的应用环境中,记录可能会被存储在文件,数据库,抑或是通过网络进行发送。
在Main方法里,我们实例化了一个DocumentManager对象,并且启动了文档处理任务。然后我们向DocumentManager里添加了1,000份文档:
private static async Task Main() //注意Main方法这里的async和Task
{
var dm = new DocumentManager();
Task processDocuments = ProcessDocuments.Start(dm);
// Create documents and add them to the DocumentManager
for(int i = 0; i < 1000; i++)
{
var doc = new Document($ "Doc {i}", "content");
dm.AddDocument(doc);
Console.WriteLine($ "Added document {doc.Title}");
await Task.Delay(new Random().Next(20));
}
await processDocuments;
Console.ReadLine();
}
当你运行整个示例时,文档随机地添加进队列,又随机地被取出进行处理,你可能会看到如下所示的输出:
注意:在上面的示例中,Main方法被声明成了返回Task类型,这一特性要求至少C# 7.1支持。你可以在第15章,"异步编程"中了解更多关于异步Main方法的信息。
上面的示例程序使用了Task来模拟整个文档的管理过程,一个更加真实的应用场景可能是会从Web API服务中获取到要处理的文档,而非我们用for循环顺序创建的那些。
10.5 栈
栈是另外一种容器,它跟队列非常的类似。只不过和队列遵循的原则不同,它是后进先出(LIFO,Last In First Out)的。通过Push方法来为栈顶添加一个元素,Pop方法则是取出栈顶的元素。
跟Queue<T>类一样,Stack<T>也实现了IEnumerable<T>和ICollection接口。
Stack<T>类的部分成员如下表所示:
| 部分成员 | 描述 |
|---|---|
| Count | 返回栈元素的个数。 |
| Push | 向栈顶添加一个元素。 |
| Pop | 返回栈顶元素,并将其出栈。 假如栈为空,则抛出异常。 |
| Peek | 返回栈顶元素,但不出栈。 |
| Contain | 栈是否包含某个元素。 |
在接下来的例子中,我们通过使用Push方法为栈添加了三个元素,并通过foreach方法来遍历。栈的枚举器并不会移除包含的元素,它仅仅是挨个返回它们:
var alphabet = new Stack<char>();
alphabet.Push('A');
alphabet.Push('B');
alphabet.Push('C');
foreach (char item in alphabet)
{
Console.Write(item);
}
Console.WriteLine();
因为读取顺序是从栈顶到栈底,因此输出是这样子的:
CBA
而如果你用Pop方法来遍历的话,最后栈里就不存在元素了,因为Pop方法会将元素从栈里移除:
Console.Write("Second iteration: ");
while (alphabet.Count > 0)
{
Console.Write(alphabet.Pop());
}
Console.WriteLine();
Console.WriteLine(alphabet.Count.ToString()); //0
Console.WriteLine();
10.6 链表
LinkedList<T>是一种双向链表(doubly linked list),通过包含两个元素引用next和previous来实现。如下图所示:
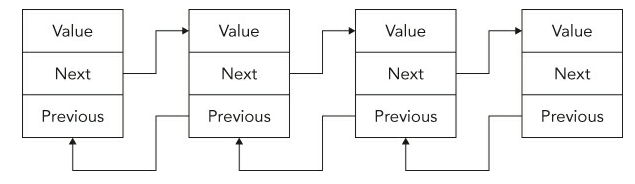
你可以轻松地向前或者向后遍历整个列表。链表的优势在于你需要将某个元素插入列表中时,这个操作会非常的快。当你试图插入元素时,仅仅需要将它前一个元素的Next指针和后一个元素的Previous指针指向新插入的元素即可。而普通的List<T>列表,当你需要插入元素时,你需要将其后的所有元素都挨个往后移动。
当然链表也有自身的缺点,它只能通过挨个进行访问。当你需要访问集合中或者集合尾的元素时,你需要花费相当长的时间去定位到它们。
链表不单止要存储实际的元素节点,它还需要额外的开销,用来存储next和previous指针。这也是为什么LinkedList<T>类型中,包含着LinkedListNode<T>类型的成员。通过LinkedListNode<T>,你可以获取任意元素节点前一个或者后一个元素,它定义的属性包括:List,Next,Previous以及Value。List属性返回的是元素节点所在的链表,Next和Previous属性则是为了在遍历链表过程中提供访问前后节点的便利性,Value则返回的是当前节点存储的实际元素值。
LinkedList<T>类本身定义了访问第一个和最后一个元素的成员,也提供了向指定位置插入元素(AddAfter,AddBefore,AddFirst,AddLast),或者移除元素(Remove,RemoveFirst,RemoveLast),以及从前往后(Find)或者从后往前(FindLast)查找特定元素的方法。
接下来的示例程序将演示链表和列表之间是如何配合使用的。链表保存了一些我们在前面队列时定义的文档对象示例,只不过比前面的文档多了一个优先级的属性。然后我们将根据这个优先级把文档存储在链表中。假如多个文档拥有相同的优先级,则按照它们插入的先后来决定它们的排序。下面这个图就是示例程序中的整个集合:
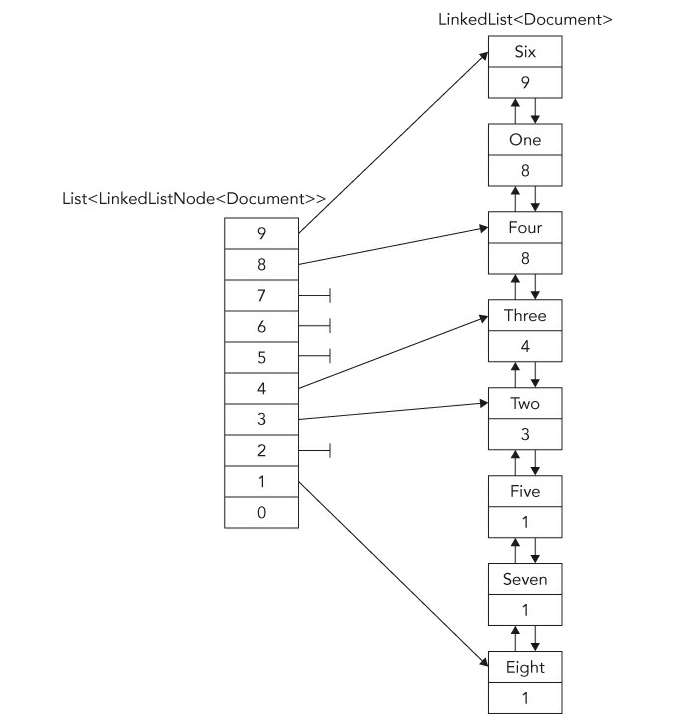
如图所示,LinkedList<Document>是用来存储所有Document对象的链表,我们可以在途中看见文档的标题和优先级。标题标识了文档是何时添加到列表中的:第一个加进来的文档标题为"One",第二个标题是"Two",并以此类推。你可以看见第一个和第四个文档都拥有同样的优先级8,但因为标题为One的文档是比Four先添加的,因此它位于列表较前一点的位置。
我们每次往链表中新增文档的时候,它们必须添加到相同优先级的最后一个文档之后。LinkedList<Document>集合包含着LinkedListNode<Document>类型的元素。LinkedListNode<Document>中含有Next和Previous属性以便你从一个节点访问到另一个。为了方便引用这些这些LinkedListNode<Document>,我们新建了一个List<LinkedListNode<Document>>类型的列表。为了快速访问到每个优先级的最后一个文档节点,List<LinkedListNode>列表中包含了10个元素,每个元素依次存储的是相应优先级的最后一个节点。为了方便后续的讨论,这些每个优先级的最后一个节点我们简称之为"优先级节点"。
沿用前面队列的示例,我们为Document类添加了一个Priority属性:
public class Document
{
public string Title
{
get;
}
public string Content
{
get;
}
public byte Priority
{
get;
}
public Document(string title, string content, byte priority)
{
Title = title;
Content = content;
Priority = priority;
}
}
示例程序的核心是PriorityDocumentManager类,代码如下所示:
public class PriorityDocumentManager
{
private readonly LinkedList < Document > _documentList;
// priorities 0.9
private readonly List < LinkedListNode < Document >> _priorityNodes;
public PriorityDocumentManager()
{
_documentList = new LinkedList < Document > ();
_priorityNodes = new List < LinkedListNode < Document >> (10);
for(int i = 0; i < 10; i++)
{
_priorityNodes.Add(new LinkedListNode < Document > (null));
}
}
public void DisplayAllNodes()
{
foreach(Document doc in _documentList)
{
Console.WriteLine($ "priority: {doc.Priority}, title {doc.Title}");
}
}
}
这个类用起来非常的简单,我们可以轻易的创建一个Document实例并通过公共接口的方法将其添加到链表中。第一个document节点可以被检索(can be retrieved),并且出于测试的目的,它还拥有一个用来显示链表中所有元素的方法。
PriorityDocumentManager类中包含两个集合。其中LinkedList<Document>包含了所有的文档,而List<LinkedListNode<Document>>则包含了根据指定优先级添加新文档入口点的10个元素引用。集合变量都在构造函数里进行了初始化,其中列表部分使用null进行初始化。
公共接口部分一个很重要的方法是AddDocument,它做的事情很简单,仅仅是调用了私有方法AddDocumentToPriorityNode,特意将这部分提取成AddDocumentToPriorityNode方法是因为后续需要进行递归调用,如下所示:
public void AddDocument(Document d)
{
if(d == null) throw new ArgumentNullException(nameof(d));
AddDocumentToPriorityNode(d, d.Priority);
}
// returns the document with the highest priority
// (that's first in the linked list)
public Document GetDocument()
{
Document doc = _documentList.First.Value;
_documentList.RemoveFirst();
return doc;
}
private void AddDocumentToPriorityNode(Document doc, int priority)
{
if(priority > 9 || priority < 0) throw new ArgumentException("Priority must be between 0 and 9");
if(_priorityNodes[priority].Value == null)
{
--priority;
if(priority >= 0) //书中这里是priority<=0,一看就知道错了,去找了源代码才发现应该是>=0
{
// check for the next lower priority
AddDocumentToPriorityNode(doc, priority);
}
else // now no priority node exists with the same priority or lower
// add the new document to the end
{
_documentList.AddLast(doc);
_priorityNodes[doc.Priority] = _documentList.Last;
}
return;
}
else // a priority node exists
{
LinkedListNode < Document > prioNode = _priorityNodes[priority];
if(priority == doc.Priority)
// priority node with the same priority exists
{
_documentList.AddAfter(prioNode, doc);
// set the priority node to the last document with the same priority
_priorityNodes[doc.Priority] = prioNode.Next;
}
else // only priority node with a lower priority exists
{
// get the first node of the lower priority
LinkedListNode < Document > firstPrioNode = prioNode;
while(firstPrioNode.Previous != null && firstPrioNode.Previous.Value.Priority == prioNode.Value.Priority)
{
firstPrioNode = prioNode.Previous;
prioNode = firstPrioNode;
}
_documentList.AddBefore(firstPrioNode, doc);
// set the priority node to the new value
_priorityNodes[doc.Priority] = firstPrioNode.Previous;
}
}
}
AddDocumentToPriorityNode方法首先检查了传入的priority是否满足限定的取值范围。这里我们指定的有效范围是[0,9],假如超出限制的数据范围,则直接抛出一个异常。
接下来,你将根据传入的优先级参数进行查找,看看相同的优先级是否已经存在一个优先级节点。假如在列表集合中尚未存在这样的节点,则将priority自减1,并递归调用AddDocumentToPriorityNode方法,来循环检查前一优先级是否已经存在优先级节点了。
假如在当前优先级以及前面的任何优先级都找不到任何优先级节点,我们就可以很安逸地调用AddLast方法,将文档添加到链表的末尾(个人觉得此时链表应该是空的,否则必然能找到一个节点)。并且,我们认为该优先级的优先级节点就是我们刚添加的这个文档,并将优先级节点的引用存储到列表中。
假如能找到一个前置存在的优先级节点,那么你将得到它在链表中的位置引用,这样你就可以选择将你的文档插入到它附近。在示例程序里,你可以确认你找到的,究竟是相同优先级的节点,还是优先级略低一些的节点。如果是前者,你可以将你的文档插入到它之后,并将列表中存储的优先级节点指向我们这个新的节点,因为我们前面规定了,相同优先级的文档按先来后到的顺序插入到前一个文档之后。而当你找到的是优先级稍低一些的优先级节点的话(这意味着当前优先级,新增的这个文档是独一份),情况要略微复杂一些。在这里,我们选择的是,将新增的文档,插入到前一优先级节点首节点(因为你得到的优先级节点,是那个优先级最后一个节点)之前。为了得到首节点,我们通过while循环和节点的Previous属性来遍历链表,直到Previous的优先级发生改变之前。这样我们就得到了我们需要的首节点。
剩下的DisplayAllNodes和GetDocument方法浅显易懂,我们就一笔带过了。
在Main方法里,我们声明了PriorityDocumentManager对象实例,并通过它的方法添加了不同优先级的8个文档添加到链表中,并在控制台上输出链表的实际存储情况:
var pdm = new PriorityDocumentManager();
pdm.AddDocument(new Document("one", "Sample", 8));
pdm.AddDocument(new Document("two", "Sample", 3));
pdm.AddDocument(new Document("three", "Sample", 4));
pdm.AddDocument(new Document("four", "Sample", 8));
pdm.AddDocument(new Document("five", "Sample", 1));
pdm.AddDocument(new Document("six", "Sample", 9));
pdm.AddDocument(new Document("seven", "Sample", 1));
pdm.AddDocument(new Document("eight", "Sample", 1));
pdm.DisplayAllNodes();
控制台的输出如下所示:
priority: 9, title six
priority: 8, title one
priority: 8, title four
priority: 4, title three
priority: 3, title two
priority: 1, title five
priority: 1, title seven
priority: 1, title eight
10.7 有序列表
假如你需要根据Key值进行自动排序的集合,你可以使用SortedList<TKey, TValue>,这里的Key和Value可以是任意类型。下面的例子中,我们创建了Key和Value均为string类型的有序列表。首先通过默认的构造函数创建了一个空列表,然后用Add方法在其中添加了两本书。你也可以用重载的构造函数,直接指定列表的容量,又或者将实现了IComparer<TKey>的类作为参数进行构建:
var books = new SortedList < string, string > ();
books.Add("Professional WPF Programming", "978–0–470–04180–2");
books.Add("Professional ASP.NET MVC 5", "978–1–118-79475–3");
books["Beginning C# 6 Programming"] = "978-1-119-09668-9";
books["Professional C# 6 and .NET Core 1.0"] = "978-1-119-09660-3";
Add方法的第一个参数是列表的键(书名),而第二个参数则是值(书的ISBN编号)。除了使用Add方法之外,你也可以通过索引器为有序列表添加元素,它以键作为索引,如果某本书名已经存在,使用Add方法的时候将会抛出一个异常,而使用索引的时候,新的值将会替代原有的值。
注意:
SortedList<TKey, TValue>对于每个Key仅允许保存一个值,假如你需要为某个Key保存复数的值,你可以使用Lookup<TKey, TValue>。
你可以通过foreach语句来遍历有序列表,在枚举器中,元素返回的是键值对的类型KeyValuePair<TKey, TValue>,你可以通过Key和Value两个属性来分别对它们进行访问:
foreach (KeyValuePair<string, string> book in books)
{
Console.WriteLine($"{book.Key}, {book.Value}");
}
运行结果如下所示:
Beginning C# 6 Programming, 978-1-119-09668-9
Professional ASP.NET MVC 5, 978-1-118-79475-3
Professional C# 6 and .NET Core 1.0, 978-1-119-09660-3
Professional WPF Programming, 978-0-470-04180-2
你也可以通过列表的Values和Keys属性进行遍历,这俩属性返回的是IList<T>类型的集合,所以你可以像这样子:
foreach (string isbn in books.Values)
{
Console.WriteLine(isbn);
}
foreach (string title in books.Keys)
{
Console.WriteLine(title);
}
结果如下所示:
978-1-119-09668-9
978-1-118-79475-3
978-1-119-09660-3
978-0-470-04180-2
Beginning C# 6 Programming
Professional ASP.NET MVC 5
Professional C# 6 and .NET Core 1.0
Professional WPF Programming
假如你试图通过索引访问一个不存在的Key,则会抛出一个异常。为了避免这个问题,你可以使用ContainsKey方法来判断列表中是否存在Key值,或者你可以使用TryGetValue方法,它可以尝试访问而不会抛出异常:
string title = "Professional C# 8";
if (!books.TryGetValue(title, out string isbn))
{
Console.WriteLine($"{title} not found");
}
10.8 字典
字典是一个复杂的数据结构,你可以通过Key来访问其中的数据。字典通常也被当成哈希表(Hash table)或者散列表(Hashmap)。字典的主要特性是快速地通过Key查找到相应的Value。你可以往字典里添加和移除元素,有点像List<T>,但是字典有额外的性能开销,因为它需要随时调整在内存中键值的存储位置。请看下图:
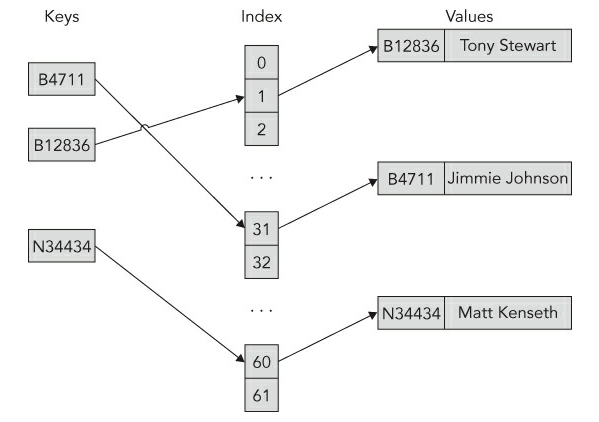
这里简单地演示了字典添加键值时的处理过程。假定此时我们准备往字典里添加员工ID为B4711的数据,首先B4711将会进行哈希转换,然后通过得到的哈希值关联上员工名称Jimmie Johnson。如图所示,索引31包含了指向实际值的链接。图中的过程是被简化了的,因为可能存在一个索引需要关联多个值的情况,并且索引可能是以树结构进行存储的。
.NET提供了一些字典类,最常用的可能是Dictionary<TKey, TValue>。
10.8.1 字典初始化器
C#提供了字典声明时候就进行赋值初始化的语法。如下所示,我们创建了Key为int类型,Value为string类型的字典:
var dict = new Dictionary<int, string>()
{
[3] = "three",
[7] = "seven"
};
并且,我们为这个字典添加了两个元素,第一个元素的Key值为3,Value值为three,而第二个元素的Key是7,Value是seven。这个初始化器的语法很好理解,并且我们也是用类似的语法来访问字典元素的。
10.8.2 键的类型
字典中的Key类型需要实现GetHashCode,你可以根据需求重写Object类的GetHashCode方法。因为字典类时刻需要决定某个键值应该存储的位置,而它是通过调用GetHashCode来确定的。上面例子中的int类型同样由GetHashCode返回相应的哈希值,因此字典可以计算索引,确定元素实际存储的位置。这里我们不会深入讲解这块的算法,你只需要知道它涉及到质数,并且字典的容量也是一个质数(prime number)即可。
GetHashCode方法的实现必须满足以下要求:
- 同样的对象必须返回相同的值。
- 不同的对象可以返回相同的值。
- 不能抛出异常。
- 至少要用到一个对象实例的变量(at least one instance field)。
- 在对象的生命周期内,哈希值不能发生改变。
除了上面必要的限制外,如果GetHashCode的实现满足了以下条件,会让人更加满意:
- 计算起来越快越好,消耗的资源越低越好。
- 计算出来的哈希值在整个int类型取值范围内,最好是均匀分布的。
注意:字典的性能基本上取决于GetHashCode的实现。
为什么说哈希值最好是均匀分布的呢?假如两个Key返回的哈希值,通过字典计算后,拥有相同的索引,那么字典类就需要去查找能存储第二个元素的,最近的空闲内存空间,这个查找的过程需要花费一定的时间。这明显对性能有所损耗。进一步讲,不过不止两个Key而是有大量的Key值返回的都是同一个索引的话,那么冲突的可能性就更大了。只不过,微软内置的算法尽量地避免了这一风险,它使得计算出来的哈希值尽量均匀分布在int取值范围的整个区间中。(从文中看不出来为啥要均匀分布,个人感觉大概是因为哈希码均匀分布的话,计算出来的索引冲突的可能性会小一些。)
除了实现GetHashCode方法之外,想成为Key的类型还需要实现IEquatable<T>接口的Equals方法,或者重写Object类的Equals方法。这是因为不同的对象实例可能会返回相同的哈希码,这个时候字典就需要调用Equals方法来对Key值进行比较,比如两个实例A和B,字典通过调用A.Equals(B)来判断他俩是否为相同的Key。这意味着,当A.Equals(B)为true的时候,他俩计算出来的哈希值必须是一致的。
这一点看起来很微妙,但它至关重要。假如你在人为实现这些方法的过程中无法保证这一点,那么字典在将A和B这俩实例作为Key的时候,就会判断出错。你将会发现一些很滑稽的事情,譬如当你存入为某个Key存入相应的值之后你再也无法获取它,又或者同样的Key你会得到不一样的值。
注意:出于这一点考虑,当你尝试重写Equals方法却没有重写GetHashCode的时候,C#编译器会提示一个编译警告。
对于System.Object类来说,上面的条件也是成立的。因为它的Equals方法仅仅比较的是引用,而GetHashCode方法返回的哈希值则基于对象的内存地址。这意味着就算不重写这些方法,以对象为Key的哈希表们理论上也能正常运行。然而,这种方式的问题在于,只有当这些对象的引用是完全相同的时候,Equals方法才会把它们当成是同样的对象,也就说是相同的Key。这意味着,当你为某个Key存入对象数据的时候,你必须保留这个Key的引用,就算你后面new了一个内部值完全一致的新实例,但因为引用不同,它们就不是相同的key,所以取不出来需要的值。因此,如果你不重写Equals和GetHashCode方法的话,你会发现字典用起来也不是那么方便。
顺带一提,System.String类实现了IEquatable接口并且适当地重写了GetHashCode方法。它的Equals方法中提供了值的比较,而GetHashCode返回的哈希值也是基于字符串值的。因此String类型可以很方便的作为字典的Key。
数值类型,比如Int32,也实现了IEquatable接口和GetHashCode方法的重写。然而,数值类型返回的哈希码,仅仅只是数值的简单映射(simply maps to the value)。假如你将数值类型作为字典的Key的话,它自身并不是均匀分布的,因此不符合上面提及的提高性能建议。Int32并不太适合用来作为字典的Key类型。
假如你需要使用某种类型作为Key,但是它既没有实现IEquatable接口又没有重写GetHashCode方法,此时你可以创建一个实现了IEqualityComparer<T>接口的比较器。这个接口如下所示:
public interface IEqualityComparer < in T >
{
bool Equals(T x, T y);
int GetHashCode(T obj);
}
它定义了GetHashCode和Equals方法,用来为传入类型的实例进行比较。在创建字典的时候,你可以给字典的构造函数传递这个比较器作为参数。这样当该类型作为字典的Key时,字典也知道如何正确地计算该类型的哈希码以及对它进行比较。
10.8.3 字典示例
本小节中的字典示例将创建一个雇员详细信息的字典,它将EmployeeId对象来作为索引,而相应的值存储的则是Employee对象。如下所示:
public class EmployeeIdException: Exception
{
public EmployeeIdException(string message): base(message)
{}
}
public struct EmployeeId: IEquatable < EmployeeId >
{
private readonly char _prefix;
private readonly int _number;
//这俩属性是自己添加的,书中并没有
public int Number { get => _number; }
public char Prefix { get => _prefix; }
public EmployeeId(string id)
{
if(id == null) throw new ArgumentNullException(nameof(id));
_prefix = (id.ToUpper())[0];
int numLength = id.Length - 1;
try
{
_number = int.Parse(id.Substring(1, numLength > 6 ? 6 : numLength));
}
catch(FormatException)
{
throw new EmployeeIdException("Invalid EmployeeId format");
}
}
public override string ToString() => _prefix.ToString() + $"{_number,6:000000}";
public override int GetHashCode() => (_number ^ _number << 16) * 0x15051505;
public bool Equals(EmployeeId other) => (_prefix == other.Prefix && _number == other.Number); //书中这一块大概是伪代码
public override bool Equals(object obj) => Equals((EmployeeId) obj);
public static bool operator == (EmployeeId left, EmployeeId right) => left.Equals(right);
public static bool operator != (EmployeeId left, EmployeeId right) => !(left == right);
}
EmployeeId结构体是用来定义字典中的Key值的,成员包括一个前缀字符和一串员工编号。这些变量都是只读的,并且只能在构造函数里进行初始化来确保它作为字典Key值是绝对不会改变的。这里重写了ToString方法来获取完整的员工ID。根据Key类型的基本要求,EmployeeId同样实现了IEquatable接口和GetHashCode的重写。
Equals方法是接口IEquatable中定义的方法,用来比较两个EmployeeId对象,当它们的成员值都相同的时候则返回true。如果你不想实现IEquatable接口,你也可以直接重写Object类的Equals方法:
public bool Equals(EmployeeId other) => _prefix == other.Prefix && _number == other.Number;
从现实的角度考虑,员工编码不会是负数,因此number变量不可能囊括整个int的范围。因此为了让数据分布得更均匀一些,GetHashCode里,将number往左按位移动了16位,并与原始值做异或操作,并且最终与一个16进制数0x15051505相乘。
注意:在互联网上,你还可以找到更多更好的算法来实现哈希码均匀分布。你也可以直接使用字符串的GetHashCode方法来返回哈希码。
Employee类则是一个简单的实体类,包含了雇员的姓名,薪资和员工编号,如下所示:
public class Employee
{
private string _name;
private decimal _salary;
private readonly EmployeeId _id;
public Employee(EmployeeId id, string name, decimal salary)
{
_id = id;
_name = name;
_salary = salary;
}
public override string ToString() => $"{_id.ToString()}: {_name,-20} {_salary:C}";
}
构造函数里初始化了所有字段的值,而ToString方法则返回整个实例的详细信息,并且为了显示得更工整一些,对不同字段指定了格式。
在Main方法中,我们创建了一个Dictionary<TKey,TValue>的实例,其中TKey是EmployeeId类型,而Value则是Employee类型。如下所示:
var idJimmie = new EmployeeId("C48");
var jimmie = new Employee(idJimmie, "Jimmie Johnson", 150926.00 m);
var idJoey = new EmployeeId("F22");
var joey = new Employee(idJoey, "Joey Logano", 45125.00 m);
var idKyle = new EmployeeId("T18");
var kyle = new Employee(idKyle, "Kyle Bush", 78728.00 m);
var idCarl = new EmployeeId("T19");
var carl = new Employee(idCarl, "Carl Edwards", 80473.00 m);
var idMatt = new EmployeeId("T20");
var matt = new Employee(idMatt, "Matt Kenseth", 113970.00 m);
var employees = new Dictionary < EmployeeId, Employee > (31)
{
[idJimmie] = jimmie, [idJoey] = joey,
[idKyle] = kyle, [idCarl] = carl, [idMatt] = matt
};
foreach(var employee in employees.Values)
{
Console.WriteLine(employee);
}
字典的构造函数中我们指定了字典容量为31。请记住容量最好是质数,不过,就算你忘了这一点也没有太大的关系,字典类会自动找一个比你设置的容量略大一点的质数来作为字典容量。当我们创建好所有的雇员对象之后,通过字典初始化器的语法将它们都添加到字典中。当然,你也可以用Add方法来向字典中添加元素。
当所有的键值对(Entry)都加到字典之后,我们在一个while循环中来读取字典中的值。控制台将会等待你的输入,并将你输入的值赋给userInput变量,并且通过字典的TryGetValue方法,来根据你输入的内容查找员工信息,假如能找到相应的员工信息,将找到的值赋给employee变量,并输出到控制台上。当你输入大写的X的时候,则结束这个应用程序。代码如下所示:
while(true)
{
Console.Write("Enter employee id (X to exit)> ");
var userInput = Console.ReadLine();
userInput = userInput.ToUpper();
if(userInput == "X") break;
EmployeeId id;
try
{
id = new EmployeeId(userInput);
if(!employees.TryGetValue(id, out Employee employee))
{
Console.WriteLine($ "Employee with id {id} does not exist");
}
else
{
Console.WriteLine(employee);
}
}
catch(EmployeeIdException ex)
{
Console.WriteLine(ex.Message);
}
}
注意:你也可以选择不使用TryGetValue方法而是通过索引的方式来。只不过当你输入的Key不存在字典当中时,将会抛出一个KeyNotFoundException。
运行程序,输出可能如下所示:
C000048: Jimmie Johnson $150,926.00
F000022: Joey Logano $45,125.00
T000018: Kyle Bush $78,728.00
T000019: Carl Edwards $80,473.00
T000020: Matt Kenseth $113,970.00
Enter employee id (X to exit)> T18
T000018: Kyle Bush $78,728.00
Enter employee id (X to exit)> C48
C000048: Jimmie Johnson $150,926.00
Enter employee id (X to exit)> X
10.8.4 Lookup 类
在Dictionary<TKey, TValue>中,一个Key仅能对应一个Value。Lookup<TKey, TElement>和Dictionary类很像,只不过它一个Key可以对应一个集合的值。Lookup类的命名空间是System.Linq,在程序集System.Core中实现。
Lookup类无法像普通字典那样进行创建,你必须调用ToLookup方法才能得到Lookup对象。ToLookup是一个扩展方法,只要实现了IEnumerable<T>的类都可以调用这个方法。在下面的例子当中,我们创建了一个Racer类的列表,并为其添加了一些数据。因为List<T>实现了IEnumerable<T>接口,因此我们可以在Racer列表上调用ToLookup方法。这个方法需要一个Func类型的委托作为参数以便确定Key的选择器,这里我们选择的是按参赛者的国籍进行分类。然后我们使用索引的方式获取国籍为Australia的参赛者集合,并通过foreach循环来打印到控制台上:
var racers = new List < Racer > ();
//书中代码少写了ID值
racers.Add(new Racer(1, "Jacques", "Villeneuve", "Canada", 11));
racers.Add(new Racer(2, "Alan", "Jones", "Australia", 12));
racers.Add(new Racer(3, "Jackie", "Stewart", "United Kingdom", 27));
racers.Add(new Racer(4, "James", "Hunt", "United Kingdom", 10));
racers.Add(new Racer(5, "Jack", "Brabham", "Australia", 14));
var lookupRacers = racers.ToLookup(r => r.Country);
foreach(Racer r in lookupRacers["Australia"])
{
Console.WriteLine(r);
}
注意:你可以在第十二章,"LINQ"中了解更多的扩展方法。而lambda表达式则是在第8章,"委托,Lambda和事件"中已经详细介绍过了。
运行程序,输出如下所示:
Alan Jones
Jack Brabham
10.8.5 有序字典
SortedDictionary<TKey, TValue>是一颗二叉树(binary search tree),基于Key值进行排序。作为Key的类型必须实现IComparable<TKey>接口。假如Key类无法进行扩展,你也可以创建一个实现了IComparer<TKey>类型的比较器,并在使用构造函数创建有序字典时,将其作为参数传递。
在前面的章节中,你已经了解了有序列表的相关知识。有序字典和有序列表有一些类似的功能,但因为有序列表是基于Array实现,而有序字典则是基于字典实现的,它们也有不一样的地方:
- 有序列表占用的内存比有序字典要少。
- 有序字典插入和移除元素的时候更快。
- 当用已经排好序的数据填充新集合时,如果不需要扩容的话,有序列表的速度会非常快。
10.9 集
一个只拥有不同元素的集合我们称之为集(Set)。.NET Core中包含两种集,HashSet<T>和SortedSet<T>,它们都实现了ISet<T>接口,前者中的元素是乱序的,而后者则是有序的。ISet接口的定义如下所示:
public interface ISet<T> : ICollection<T> , IEnumerable<T> , IEnumerable
{
bool Add(T item);
void ExceptWith(IEnumerable<T> other);
void IntersectWith(IEnumerable<T> other);
bool IsProperSubsetOf(IEnumerable<T> other);
bool IsProperSupersetOf(IEnumerable<T> other);
bool IsSubsetOf(IEnumerable<T> other);
bool IsSupersetOf(IEnumerable<T> other);
bool Overlaps(IEnumerable<T> other);
bool SetEquals(IEnumerable<T> other);
void SymmetricExceptWith(IEnumerable<T> other);
void UnionWith(IEnumerable<T> other);
}
在多个集之间,它提供了创建并集和交集的方法,还可以判断一个集合是否为另外一个集合的超集或者子集。
在下面的示例代码中,我们创建了三个string类型的集,并且用F1方程式赛车的信息填充它们。
var companyTeams = new HashSet < string > ()
{
"Ferrari", "McLaren", "Mercedes"
};
var traditionalTeams = new HashSet < string > ()
{
"Ferrari", "McLaren"
};
var privateTeams = new HashSet < string > ()
{
"Red Bull", "Toro Rosso", "Force India", "Sauber"
};
if(privateTeams.Add("Williams"))
{
Console.WriteLine("Williams added");
}
if(!companyTeams.Add("McLaren"))
{
Console.WriteLine("McLaren was already in this set");
}
运行程序,输出如下所示:
Williams added
McLaren was already in this set
除了ISet<T>接口之外,HashSet<T>还实现了ICollection<T>接口。这俩接口中都定义了Add方法,类为此提供了不同的Add方法实现并根据Add方法的返回值进行了区分。这里我们调用的是返回bool值的Add方法,它可以用来判断元素是否被添加到集之中。假如集之中已经存在该元素了,就会返回一个false,表示不用添加。我们补充一下HashSet<T>的声明:
[NullableContext(1), Nullable((byte) 0)]
public class HashSet<T> : ICollection<T> , IEnumerable<T> , IEnumerable, IReadOnlyCollection<T> , ISet<T> , IDeserializationCallback, ISerializable
{
//...其它成员和方法
//外部能调用的其实只有返回值为bool的Add方法
public bool Add(T item);
void ICollection<T>.Add(T item);
}
IsSubsetOf和IsSupersetOf方法用来比较两个实现了IEnumerable<T>接口的集,返回结果为Boolean值。下面是示例代码:
if (traditionalTeams.IsSubsetOf(companyTeams))
{
Console.WriteLine("traditionalTeams is subset of companyTeams");
}
if (companyTeams.IsSupersetOf(traditionalTeams))
{
Console.WriteLine("companyTeams is a superset of traditionalTeams");
}
在这里,IsSubsetOf方法验证了traditionalTeams里的每个元素是否都包含在companyTeams中,而IsSupersetOf则检查traditionalTeams是否有任何别的元素没有包含在companyTeams中。输出结果如下所示:
traditionalTeams is a subset of companyTeams
companyTeams is a superset of traditionalTeams
Williams也属于traditionalTeams,我们调用Add方法将它加到traditionalTeams中:
traditionalTeams.Add("Williams");
if(privateTeams.Overlaps(traditionalTeams))
{
Console.WriteLine("At least one team is the same with traditional "
+ "and private teams");
}
因为privateTeams也包含了Williams,因此两者确实有交集(Overlap),所以控制台会输出:
At least one team is the same with traditional and private teams.
变量allTeams是一个新创建的SortedSet<string>实例,我们通过UnionWith方法,将companyTeams, privateTeams, 以及traditionalTeams合并到allTeams中:
var allTeams = new SortedSet<string>(companyTeams);
allTeams.UnionWith(privateTeams);
allTeams.UnionWith(traditionalTeams);
Console.WriteLine();
Console.WriteLine("all teams");
foreach (var team in allTeams)
{
Console.WriteLine(team);
}
因为集里面元素都具有唯一性,因此不同组之间重复的元素在合并后的allTeams里也只会出现一次,结果如下所示:
Ferrari
Force India
Lotus
McLaren
Mercedes
Red Bull
Sauber
Toro Rosso
Williams
下面的例子中,ExceptWith方法将privateTeams中所有的元素都从allTeams中移除:
allTeams.ExceptWith(privateTeams);
Console.WriteLine();
Console.WriteLine("no private team left");
foreach (var team in allTeams)
{
Console.WriteLine(team);
}
结果如下:
Ferrari
McLaren
Mercedes
10.10 性能
大部分集合提供的功能大同小异。举个例子,有序列表提供的特性几乎就跟有序字典一模一样。尽管如此,它们在性能上还是有很大差异的。有些类占用的内存很少,而有些类在检索方面更快一些。MSDN文档中提供了不同集合方法的性能提示,通过大O函数来告诉你不同操作所需的时间复杂度,常见的复杂度有O(1),O(log n)和O(n)等。
O(1)意味着某项操作花费的时间是常数级别,不会随着集合中元素个数而发生变化。举个例子,ArrayList类添加元素的操作就是O(1)复杂度的,不管列表中有多少个元素,往列表末尾新增一个元素所需的时间都不会有太大的变化。Count属性记录了列表元素的个数,因此很轻松就能找到列表的末尾。
O(n)意味着某项操作最坏情况下将花费的时间为N。前一段例子中,ArrayList的Add方法在列表容量不足,需要重新请求内存时,花费的时间将可能会达到N。修改列表的容量将申请一块新的更大的内存,并将列表原有的元素复制到新内存当中,耗费的时间将会根据元素的个数而呈线性增长。
O(log n)意味着某项操作花费的时间仍然受集合中元素个数的影响,只不过它耗时的增长不是线性的而是对数级的。在有序字典中执行插入操作的时间复杂度就是O(log n),有序列表也不例外。而有序字典比有序列表插入要快一些,因为往树里插入新节点比往列表中插入新元素要高效一些。
下面的表格列举了集合类部分操作(如新增,插入和删除元素)的时间复杂度。通过这个表格,你可以根据你的实际需求选择最佳的集合类。最左侧的列是集合类的名称,接下来的ADD列显示的是不同集合类增加元素所需的时间复杂度。有些集合使用的是Add方法,而有些集合,如栈,用的则是Push,队列用的是Enqueue。所以表头仅代表操作而非具体方法名。
如果你在一个单元格中看到多个时间复杂度函数,通常是因为它们在容量充裕和需要申请新的内存时情况不同。举个例子,对于List类来说,正常情况下新增一个元素需要O(1)复杂度,但是当它容量不足需要申请新内存时,这个操作就要花费O(n)的时间,原来的集合越大,花费的时间就越多。你可以通过为集合设置一个足够大的初始容量来避免操作过程中引起的容量调整。
假如某个单元格的值为N/A,意味着这项操作对该类型的集合来说不可用。
| 集合 | ADD | INSERT | REMOVE | ITEM | SORT | FIND |
|---|---|---|---|---|---|---|
| List | O(1)/O(n) | O(n) | O(n) | O(1) | O(nlogn)/O(n^2) | O(n) |
| Stack | O(1)/O(n) | N/A | O(1) | N/A | N/A | N/A |
| Queue | O(1)/O(n) | N/A | O(1) | N/A | N/A | N/A |
| HashSet | O(1)/O(n) | O(1)/O(n) | O(1) | N/A | N/A | N/A |
| SortedSet | O(1)/O(n) | O(1)/O(n) | O(1) | N/A | N/A | N/A |
| LinkedList | O(logn) | O(1) | O(1) | N/A | N/A | O(n) |
| Dictionary | O(1)/O(n) | N/A | O(1) | O(1) | N/A | N/A |
| SortedDictionary | O(logn) | N/A | O(logn) | O(logn) | N/A | N/A |
| SortedList | O(1)/O(logn)/O(n) | N/A | O(n) | O(logn)/O(n) | N/A | N/A |
10.11 小结
本章致力于讲解如何使用不同类型的泛型集合。数组是定长的,但你可以使用列表来处理需要动态增长的应用场景。队列可以用来处理先进先出元素的访问,而栈则可以用来处理后进先出。链表在插入和移除元素方面很快,不过在查询方面较慢。通过键Key和值Value,你可以使用字典,它对于插入和查找的效率都很高。集对于保证集合中元素的唯一性很有用,并且还提供了能自动排序的集。
在下一章,"特殊集合"中,我们将为你介绍一些特殊集合类的细节。