See, Hear and Read: Deep Aligned Representations
本paper提出了可以在三种自然模态(视觉,声音,语言)下进行学习的深度判断特征表达,使用Deep Conv Network来进行对齐式的表达学习。
本paper使用的dataset:

Cross-Modal Network
目标是对image X 和sound Y学习其对齐之后的representation。
Learning Aligned Representation的结构:
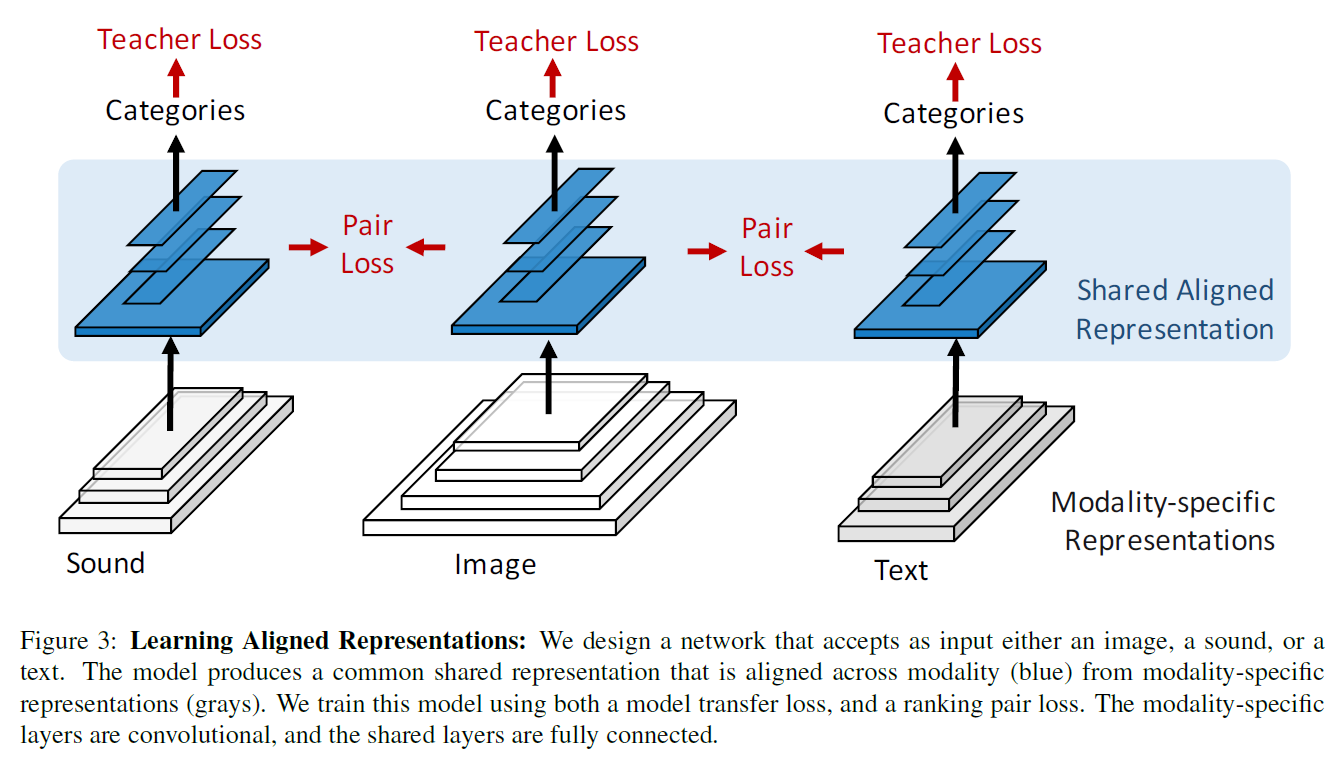
为了让不同模态之间的representation进行对齐,在网络较上层的layer进行共享参数。这样的好处是让类内部的representation进行跨模态的融合。
Student-teacher模型在transfer learning上使用。在本paper中,不使用aligned representation,而是让learned parameters进行共享。
Alignment by Model Transfer
给定一个 teacher 模态 g(x), 比如让AlexNet成为image classification model,在给定另一个模态的data时,对f(x) 进行训练。
使用KL-divergence作为loss:
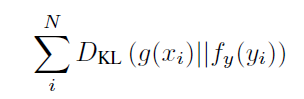
Alignment by Ranking
对于ranking loss function,采用有着对齐和判别属性的表达式:
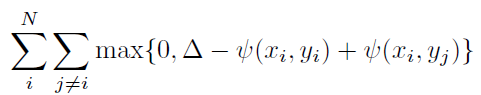
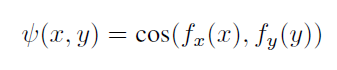
其中△是边缘大小的超参数。
Learning
其中 model transfer loss 来源于最后一层的output layer,ranking loss 来源于所有的共享layers。最后的objective loss 是两者的总和。
Network Architecture
网络有三层不同的输入层,取决于数据的不同模态。其中网络的disjoint pathway对不同的模态的data进行feature extraction,然后在shared layers中拟合成modal-robust features。
Sound Network
因为sound是一维的信号,本paper使用四层的卷积网络将spectrogram转换成high-level的representation,
Text Network
使用word2vec将sentences转换为word representation,使用一个四层的deep one-dimensional Convolutional Network 来提取特征
Vision Network
使用标准的Krizhevsky architecture,提取pool5的特征经过flatten作为特征
Shared Network
来自sound,text,和vision的feature都有着固定长度相同维度的vector,
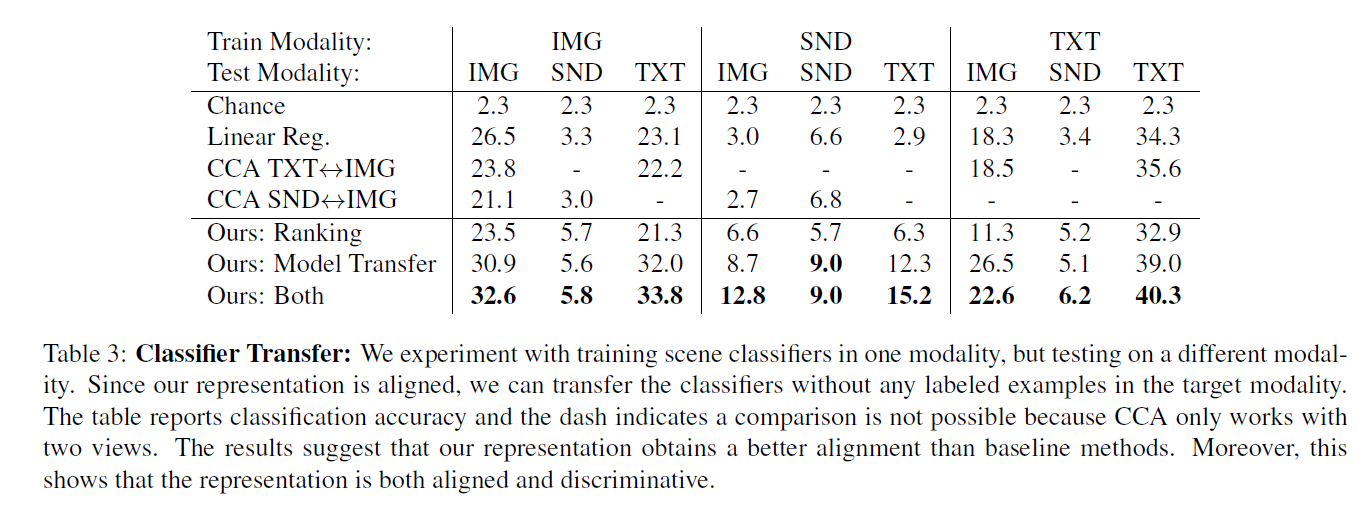
对比结果:
总结:
将data经过不同的特征转化网络,在shared layer里面将相同label的特征统一扭曲到可分的空间中。