实验环境


软件下载
下载地址 http://bits.gluster.org/pub/gluster/glusterfs/3.4.2/x86_64/ RPM安装包 glusterfs-3.4.2-1.el6.x86_64.rpm glusterfs-api-3.4.2-1.el6.x86_64.rpm glusterfs-cli-3.4.2-1.el6.x86_64.rpm glusterfs-fuse-3.4.2-1.el6.x86_64.rpm glusterfs-libs-3.4.2-1.el6.x86_64.rpm glusterfs-server-3.4.2-1.el6.x86_64.rpm依赖包安装 依赖包 Rpcbind Libaio Lvm2-devel YUM安装 Yum install rpcbind libaio lvm2-devel
软件安装
安装服务器端软件包 glusterfs-3.4.2-1.el6.x86_64.rpm glusterfs-cli-3.4.2-1.el6.x86_64.rpm glusterfs-libs-3.4.2-1.el6.x86_64.rpm glusterfs-api-3.4.2-1.el6.x86_64.rpm glusterfs-fuse-3.4.2-1.el6.x86_64.rpm glusterfs-server-3.4.2-1.el6.x86_64.rpm 安装客户端软件包 glusterfs-3.4.2-1.el6.x86_64.rpm glusterfs-libs-3.4.2-1.el6.x86_64.rpm glusterfs-fuse-3.4.2-1.el6.x86_64.rpm
工具软件 Atop, iperf, sysstat dd, Iozone, fio, postmark 工具安装 yum install sysstat rpm –ivh *.rpm gcc –o postmark postmark-1.52.c
系统配置
主机名设置 /etc/hosts server1, server2, server3 DNS设置 编辑/etc/resolv.conf nameserver 192.168.8.2 NTP设置 /etc/ntp.conf 关闭防火墙 Service iptables stop; chkconfig iptables off 设置Selinux /etc/selinux/config SELINUX=disabled
磁盘分区 EXT4格式化工具目前最大支持16TB 使用parted进行磁盘分区 分区格式化 Mkfs.ext4 –L /brick1/dev/sdb
服务配置
分区自动挂载 /etc/fstab LABLE=/brcik1 /brick1 ext4 defaults 1 1 Gluster服务自启动 Service glusterd start Chkconfig glusterd on
二。开始hash创建
[root@glusterfs1 ~]# gluster peer probe glusterfs2 peer probe: success: host glusterfs2 port 24007 already in peer list [root@glusterfs1 ~]# gluster peer probe glusterfs3 peer probe: success: host glusterfs3 port 24007 already in peer list [root@glusterfs1 ~]# gluster peer info unrecognized word: info (position 1) [root@glusterfs1 ~]# gluster peer status Number of Peers: 2 Hostname: glusterfs2 Port: 24007 Uuid: f95fe5a9-eb37-4d7c-b73b-46224a9e5288 State: Peer in Cluster (Connected) Hostname: glusterfs3 Port: 24007 Uuid: b825a8e5-de88-4ec6-a8b5-a2329d7f5d35 State: Peer in Cluster (Connected)
#注意::如果报错请检查24007端口是否开启。。
div>
#创建一个叫meizi的卷 使用的是glusterfs1下的挂载目录/brick1/创建一个b1的目录 [root@glusterfs1 /]# gluster volume create meizi glusterfs1:/brick1/b1 #启动卷 [root@glusterfs1 /]# gluster volume start meizi volume start: meizi: success #查看卷信息 [root@glusterfs1 /]# gluster volume info Volume Name: meizi Type: Distribute Volume ID: ea16ad50-60d1-476e-842c-b429a80d493d Status: Started Number of Bricks: 1 Transport-type: tcp Bricks: Brick1: glusterfs1:/brick1/b1 #挂载卷:发现卷已经挂载到本地,可以用别名或者IP [root@glusterfs1 /]# mount -t glusterfs 192.168.1.109:/meizi /mnt [root@glusterfs1 /]# df -h Filesystem Size Used Avail Use% Mounted on /dev/sda2 18G 2.6G 15G 16% / tmpfs 495M 228K 495M 1% /dev/shm /dev/sda1 291M 33M 243M 12% /boot /dev/sdb1 7.9G 147M 7.4G 2% /brick1 /dev/sdc1 7.9G 146M 7.4G 2% /brick2 192.168.1.109:/meizi 7.9G 146M 7.4G 2% /mnt
GlusterFS命令
GlusterFS命令
gluster peer probe HOSTNAME
gluster volume info
gluster volume create VOLNAME [stripe COUNT]
[replica COUNT] [transport tcp | rdma] BRICK …
gluster volume delete VOLNAME
gluster volume add-brick VOLNAME NEW-BRICK ...
gluster volume rebalance VOLNAME start
#添加集群理的brick
[root@glusterfs1 b1]# gluster volume add-brick meizi glusterfs2:/brick1/b2 glusterfs3:/brick1/b3
volume add-brick: success
[root@glusterfs1 b1]# gluster volume info
Volume Name: meizi
Type: Distribute
Volume ID: ea16ad50-60d1-476e-842c-b429a80d493d
Status: Started
Number of Bricks: 3
Transport-type: tcp
Bricks:
Brick1: glusterfs1:/brick1/b1
Brick2: glusterfs2:/brick1/b2
Brick3: glusterfs3:/brick1/b3
# 发现磁盘扩展大了
[root@glusterfs1 b1]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda2 18G 2.6G 15G 16% /
tmpfs 495M 228K 495M 1% /dev/shm
/dev/sda1 291M 33M 243M 12% /boot
/dev/sdb1 7.9G 147M 7.4G 2% /brick1
/dev/sdc1 7.9G 146M 7.4G 2% /brick2
192.168.1.109:/meizi 24G 310M 22G 2% /mnt
#在/mnt/里创建目录/发现 3台服务器里面的/brick1/b{1..3}里面都有文件了。
#删除操作删除一个节点把3节点逻辑磁盘删除
[root@glusterfs1 b1]# gluster volume remove-brick meizi glusterfs3:/brick1/b3
Removing brick(s) can result in data loss. Do you want to Continue? (y/n) y
volume remove-brick commit force: success
[root@glusterfs1 b1]# gluster volume info
Volume Name: meizi
Type: Distribute
Volume ID: ea16ad50-60d1-476e-842c-b429a80d493d
Status: Started
Number of Bricks: 2
Transport-type: tcp
Bricks:
Brick1: glusterfs1:/brick1/b1
Brick2: glusterfs2:/brick1/b2
#发现磁盘变小 现在是2给磁盘
[root@glusterfs1 b1]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda2 18G 2.6G 15G 16% /
tmpfs 495M 228K 495M 1% /dev/shm
/dev/sda1 291M 33M 243M 12% /boot
/dev/sdb1 7.9G 148M 7.4G 2% /brick1
/dev/sdc1 7.9G 146M 7.4G 2% /brick2
192.168.1.109:/meizi 16G 296M 15G 2% /mnt
#但是发现数据没有恢复,只剩下其中在线节点的数据,如果想要数据从被删除的brick里面底层copy过去
[root@glusterfs2 ceshi]# ll
total 156
-rw-r--r-- 2 root root 0 Mar 18 04:59 b
-rw-r--r-- 2 root root 56728 Mar 18 05:00 glusterfs-api-3.4.2-1.el6.x86_64.rpm
-rw-r--r-- 2 root root 98904 Mar 18 05:00 glusterfs-cli-3.4.2-1.el6.x86_64.rpm
#不管增加还是删除一般都会对meizi这个卷做负载均衡,不然数据分布会集中在老的分布上
[root@glusterfs2 ceshi]# gluster volume rebalance meizi start
volume rebalance: meizi: success: Starting rebalance on volume meizi has been successful.
ID: a46ce2ba-9237-48ee-bfbc-e9551716d4eb
#当你在去加删除的3节点逻辑盘时候报错,是因为3节点力有这个集群的扩展卷,需要吧/brick1/b3删除以后就可以加了,加完在执行rebalance来平均负载(如果线上,建议业务不忙的时候在做)
[root@glusterfs2 mnt]# gluster volume add-brick meizi glusterfs3:/brick1/b3
volume add-brick: failed:
[root@glusterfs2 mnt]# gluster volume add-brick meizi glusterfs3:/brick1/b3
volume add-brick: success
[root@glusterfs2 mnt]# gluster volume rebalance meizi start
volume rebalance: meizi: success: Starting rebalance on volume meizi has been successful.
ID: b18108b5-fdde-4b98-9b4e-552c6bd53f74
#删除卷
#删除的时候建议先卸载 umount #在停止卷 [root@glusterfs2 ceshi]# gluster volume stop meizi Stopping volume will make its data inaccessible. Do you want to continue? (y/n) y volume stop: meizi: success #删除卷 [root@glusterfs2 ceshi]# gluster volume delete meizi Deleting volume will erase all information about the volume. Do you want to continue? (y/n) y volume delete: meizi: success #查看卷的时候已经没有了 [root@glusterfs2 ceshi]# gluster volume info No volumes present #删除底层数据 [root@glusterfs1 ceshi]# rm -rf /brick1/b1/ [root@glusterfs2 brick1]# rm -rf /brick1/b2 [root@glusterfs3 ceshi]# rm -rf /brick1/b3
三。复制卷
#创建复制卷 创建1个复制卷由2给逻辑磁盘组成 [root@glusterfs1 ceshi]# gluster volume create meizi replica 2 glusterfs1:/brick1/b1 glusterfs2:/brick1/b2 volume create: meizi: success: please start the volume to access data #启动卷 [root@glusterfs1 ceshi]# gluster volume start meizi volume start: meizi: success #查看卷信息 [root@glusterfs1 ceshi]# gluster volume info Volume Name: meizi Type: Replicate Volume ID: d6cc9695-9c7d-4747-9e30-755e89b1047b Status: Created Number of Bricks: 1 x 2 = 2 Transport-type: tcp Bricks: Brick1: glusterfs1:/brick1/b1 Brick2: glusterfs2:/brick1/b2 #挂载卷,复制卷相当于raid1空间利用率只有一半 [root@glusterfs1 mnt]# mount -t glusterfs 192.168.1.109:/meizi /mnt/ [root@glusterfs1 mnt]# df -h Filesystem Size Used Avail Use% Mounted on /dev/sda2 18G 2.6G 15G 16% / tmpfs 495M 228K 495M 1% /dev/shm /dev/sda1 291M 33M 243M 12% /boot /dev/sdb1 7.9G 147M 7.4G 2% /brick1 /dev/sdc1 7.9G 146M 7.4G 2% /brick2 192.168.1.109:/meizi 7.9G 146M 7.4G 2% /mnt #卷同步操作,删除某一个节点力的信息 [root@glusterfs1 vols]# rm -rf /var/lib/glusterd/vols/meizi/ #从节点2还原节点配置文件 [root@glusterfs1 vols]# gluster volume sync glusterfs2 all Sync volume may make data inaccessible while the sync is in progress. Do you want to continue? (y/n) y volume sync: success [root@glusterfs1 vols]# ls meizi
卷参数配置
Gluster volume set <卷> <参数> 参数项目 说明 缺省值 合法值 Auth.allow IP访问授权 *(allow all) Ip地址 Cluster.min-free-disk 剩余磁盘空间阈值 10% 百分比 Cluster.stripe-block-size 条带大小 128KB 字节 Network.frame-timeout 请求等待时间 1800s 0-1800 Network.ping-timeout 客户端等待时间 42s 0-42 Nfs.disabled 关闭NFS服务 Off Off|on Performance.io-thread-count IO线程数 16 0-65 Performance.cache-refresh-timeout 缓存校验周期 1s 0-61 Performance.cache-size 读缓存大小 32MB 字节
#授权远程访问。 #允许192.168.1.109访问 [root@glusterfs1 vols]# gluster volume set meizi auth.allow 192.168.1.109 #拒绝192.168.1.104 访问 也可以用网络段 [root@glusterfs1 vols]# gluster volume set meizi auth.reject 192.168.1.104 [root@glusterfs1 vols]# gluster volume set meizi auth.reject 192.168.1.* #关闭NFS进程 [root@glusterfs1 vols]# ps -ef |grep nfs root 34280 1 0 05:31 ? 00:00:00 /usr/sbin/glusterfs -s localhost --volfile-id gluster/nfs -p /var/lib/glusterd/nfs/run/nfs.pid -l /var/log/glusterfs/nfs.log -S /var/run/2c9f3b7533e5ab1ee0c5c1fb6a6831bd.socket root 34876 28232 0 05:52 pts/1 00:00:00 grep nfs [root@glusterfs1 vols]# gluster volume set meizi nfs.disable on volume set: success [root@glusterfs1 vols]# ps -ef |grep nfs root 34896 28232 0 05:53 pts/1 00:00:00 grep nfs
#日志存放在/var/log/gluster/下
#测试工具 测试网络 [root@43-247-208-225 ~]# iperf -s [ 8] local 43.247.208.225 port 5001 connected with 43.247.208.229 port 29782 [ 4] local 43.247.208.225 port 5001 connected with 43.247.208.229 port 29783 [ 5] local 43.247.208.225 port 5001 connected with 43.247.208.229 port 29785 [ 6] local 43.247.208.225 port 5001 connected with 43.247.208.229 port 29784 [ 8] 0.0-10.0 sec 3.90 GBytes 3.35 Gbits/sec [ 5] 0.0-10.0 sec 1.40 GBytes 1.20 Gbits/sec [ 4] 0.0-10.0 sec 1.62 GBytes 1.39 Gbits/sec [ 6] 0.0-11.0 sec 2.36 GBytes 1.84 Gbits/sec [SUM] 0.0-11.0 sec 9.28 GBytes 7.24 Gbits/sec [root@43-247-208-229 ~]# iperf -c 43.247.208.225 -P4 Client connecting to 43.247.208.225, TCP port 5001 TCP window size: 127 KByte (default) ------------------------------------------------------------ [ 5] local 43.247.208.229 port 29784 connected with 43.247.208.225 port 5001 [ 4] local 43.247.208.229 port 29783 connected with 43.247.208.225 port 5001 [ 6] local 43.247.208.229 port 29785 connected with 43.247.208.225 port 5001 [ 3] local 43.247.208.229 port 29782 connected with 43.247.208.225 port 5001 [ ID] Interval Transfer Bandwidth [ 3] 0.0- 9.0 sec 3.90 GBytes 3.72 Gbits/sec [ 4] 0.0- 9.0 sec 1.62 GBytes 1.55 Gbits/sec [ 6] 0.0- 9.0 sec 1.40 GBytes 1.33 Gbits/sec [ 5] 0.0-10.0 sec 2.36 GBytes 2.03 Gbits/sec [SUM] 0.0-10.0 sec 9.28 GBytes 7.97 Gbits/sec
#复制卷故障数据不一样
故障现象:双副本卷数据出现不一致 故障模拟:删除其中一个brick数据 [root@glusterfs1 mnt]# rm -rf /brick1/b1/dd.dat 修复方法 触发自修复:遍历并访问文件 find /mnt -type f -print0 | xargs -0 head -c1 cat 一下文件 然后发现删除的回来了 [root@glusterfs1 mnt]# ls /brick1/b1/ abc
恢复节点配置信息 故障现象:其中一个节点配置信息不正确 故障模拟 配置信息位置:/var/lib/glusterd/ 修复方法 触发自修复:通过Gluster工具同步配置信息 Gluster volume sync server1 all #操作过程 删除server2部分配置信息 [root@glusterfs2 brick1]# rm -rf /brick1/b2/ #查看1的扩展属性 [root@glusterfs1 brick1]# getfattr -d -m . -e hex b1/ # file: b1/ trusted.afr.meizi-client-0=0x000000000000000000000000 trusted.afr.meizi-client-1=0x000000000000000000000000 trusted.gfid=0x00000000000000000000000000000001 trusted.glusterfs.dht=0x000000010000000000000000ffffffff trusted.glusterfs.volume-id=0xd6cc96959c7d47479e30755e89b1047b #去2节点创建这个b2目录 [root@glusterfs2 brick1]# mkdir b2 #查看扩展属性是空的 [root@glusterfs2 brick1]# getfattr -d -m . -e hex b2 恢复复制卷brick 故障现象:双副本卷中一个brick损坏 恢复流程 1、重新建立故障brick目录 setfattr -n trusted.gfid -v 0x00000000000000000000000000000001 b2 setfattr -n trusted.glusterfs.dht -v 0x000000010000000000000000ffffffff b2 setfattr -n trusted.glusterfs.volume-id -v 0xd6cc96959c7d47479e30755e89b1047b b2 -v 的参数设置成你的值 2、设置扩展属性(参考另一个复制brick)
3、重启glusterd服务 4、触发数据自修复 find /mnt -type f -print0 | xargs -0 head -c1 >/dev/nul
常见故障处理(1)
Q1:Gluster需要占用哪些端口?
Gluster管理服务使用24007端口,Infiniband管理使用24008端口,每个
brick进程占用一个端口。比如4个brick,使用24009-24012端口。
Gluster内置NFS服务使用34865-34867端口。此外,portmapper使用111
端口,同时打开TCP和UDP端口。
Q2:创建Gluster资源池出问题?
首先,检查nslookup是否可以正确解析DNS和IP。其次,确认没有使用
/etc/hosts直接定义主机名。虽然理论上没有问题,但集群规模一大很多
管理员就会犯低级错误,浪费大量时间。再者,验证Gluster服务所需的
24007端口是否可以连接(比如telnet)?Gluster其他命令是否可以成功执
行?如果不能,Gluster服务很有可能没有启动。
Q3:如何检查Gluster服务是否运行?
可以使用如下命令检查Gluster服务状态:
(1) service glusterd status
(2) systemctl status glusterd.service
(3) /etc/init.d/glusterd status
常见故障处理(2)
Q4:无法在server端挂载(mount)Gluster卷?
检查gluster卷信息,使用gluster volume info确认volume处于启动状态。
运行命令“showmount -e <gluster node>“,确认可以输出volume相关
信息。
Q5:无法在client端挂载(mount)Gluster卷?
检查网络连接是否正常,确认glusterd服务在所有节点上正常运行,确认
所挂载volume处于启动状态。
Q6:升级Gluster后,客户端无法连接?
如果使用原生客户端访问,确认Gluster客户端和服务端软件版本一致。
通常情况下,客户端需要重新挂载卷。
Q7: 运行“gluster peer probe“,不同节点输出结果可能不一致?
这个通常不是问题。每个节点输出显示其他节点信息,并不包括当前节
点;不管在何处运行命令,节点的UUID在所有节点上都是相同和唯一的;
输出状态通常显示“Peer in Cluster (Connected)“,这个值应该和
/var/lib/glusterd/glusterd.info匹配。
常见故障处理(3)
Q8:数据传输过程中意外杀掉gluster服务进程?
所有数据都不会丢失。Glusterd进程仅用于集群管理,比如集群节点扩
展、创建新卷和修改旧卷,以及卷的启停和客户端mount时信息获取。杀
掉gluster服务进程,仅仅是一些集群管理操作无法进行,并不会造成数
据丢失或不可访问。
Q9:意外卸载gluster?
如果Gluster配置信息没有删除,重新安装相同版本gluster软件,然后重
启服务即可。Gluster配置信息被删除,但数据仍保留的话,可以通过创
建新卷,正确迁移数据,可以恢复gluster卷和数据。友情提示:配置信
息要同步备份,执行删除、卸载等操作一定要谨慎。
Q10:无法通过NFS挂载卷?
这里使用Gluster内置NFS服务,确认系统内核NFS服务没有运行。再者,
确认rpcbind或portmap服务处于正常运行中。内置NFS服务目前不支持
NFS v4,对于新Linux发行版默认使用v4进行连接,mount时指定选项
vers=3。
mount -t nfs -o vers=3 server2:/myglustervolume /gluster/mount/point
常见故障处理(4)
Q11:双节点复制卷,一个节点发生故障并完成修复,数据如何同步?
复制卷会自动进行数据同步和修复,这个在同步访问数据时触发,也可
以手动触发。3.3以后版本,系统会启动一个服务自动进行自修复,无需
人工干预,及时保持数据副本同步。
Q12:Gluster日志在系统什么位置?
新旧版本日志都位于/var/log/glusterfs
Q13:如何轮转(rotate)Gluster日志?
使用gluster命令操作:gluster volume log rotate myglustervolume
Q14:Gluster配置文件在系统什么位置?
3.3以上版本位于/var/lib/glusterd,老版本位于/etc/glusterd/。 Q15:数据库运行在gluster卷上出现很多奇怪的错误和不一致性?
Gluster目前不支持类似数据库的结构化数据存储,尤其是大量事务处理
和并发连接。建议不要使用Gluster运行数据库系统,但Gluster作为数据
库备份是一个很不错的选择
常见故障处理(5)
Q16:Gluster系统异常,重启服务后问题依旧。
很有可能是某些服务进程处于僵死状态,使用ps -ax | grep glu命令查
看。如果发出shutdown命令后,一些进程仍然处于运行状态,使用
killall -9 gluster{,d,fs,fsd}杀掉进程,或者硬重启系统。
Q17:需要在每个节点都运行Gluster命令吗?
这个根据命令而定。一些命令只需要在Gluster集群中任意一个节点执
行一次即可,比如“gluster volume create”,而例如“gluster peer
status ”命令可以在每个节点独立多次执行。
Q18:如何快速检查所有节点状态?
Gluster工具可以指定选项 --remote-host在远程节点上执行命令,比如
gluster --remote-host=server2 peer status。如果配置了CTDB,可以
使用“onnode”在指定节点上执行命令。另外,还可以通过sshkeygen和ssh-copy-id配置SSH无密码远程登录和执行命令
常见故障处理(6)
Q19:Gluster导致网络、内核、文件系统等出现问题?
可能。但是,绝大多数情况下,Gluster或者软件都不会导致网络或存
储等基础资源出现问题。如果发现由Gluster引起的问题,可以提交
Bug和patch,并可以社区和邮件列表中讨论,以帮助改善Gluster系统。
Q20:为什么会发生传输端点(transport endpoint)没有连接?
在Gluster日志中看到这种错误消息很正常,表明Gluster由于一些原因
无法通信。通常情况下,这是由于集群中某些存储或网络资源饱和引
起的,如果这类错误消息大量重复报告,就需要解决问题。使用相关
技术手段可以解决大部分的问题,另外有些情况可能由以下原因引起。
(1)需要升级RAID/NIC驱动或fireware;
(2)第三方备份系统在相同时间运行;
(3)周期更新locate数据库包含了brick和网络文件系统;
(4)过多rsync作业工作在gluster brick或mount点。
#生产调优
系统关键考虑 性能需求 Read/Write 吞吐量/IOPS/可用性 Workload 什么应用? 大文件? 小文件? 除了吞吐量之外的需求? 系统规模和架构 性能理论上由硬件配置决定 CPU/Mem/Disk/Network 系统规模由性能和容量需求决定 2U/4U存储服务器和JBOD适合构建Brick 三种典型应用部署 容量需求应用 2U/4U存储服务器+多个JBOD CPU/RAM/Network要求低 性能和容量混合需求应用 2U/4U存储服务器+少数JBOD 高CPU/RAM,低Network 性能需求应用 1U/2U存储服务器(无JBOD) 高CPU/RAM,快DISK/Network
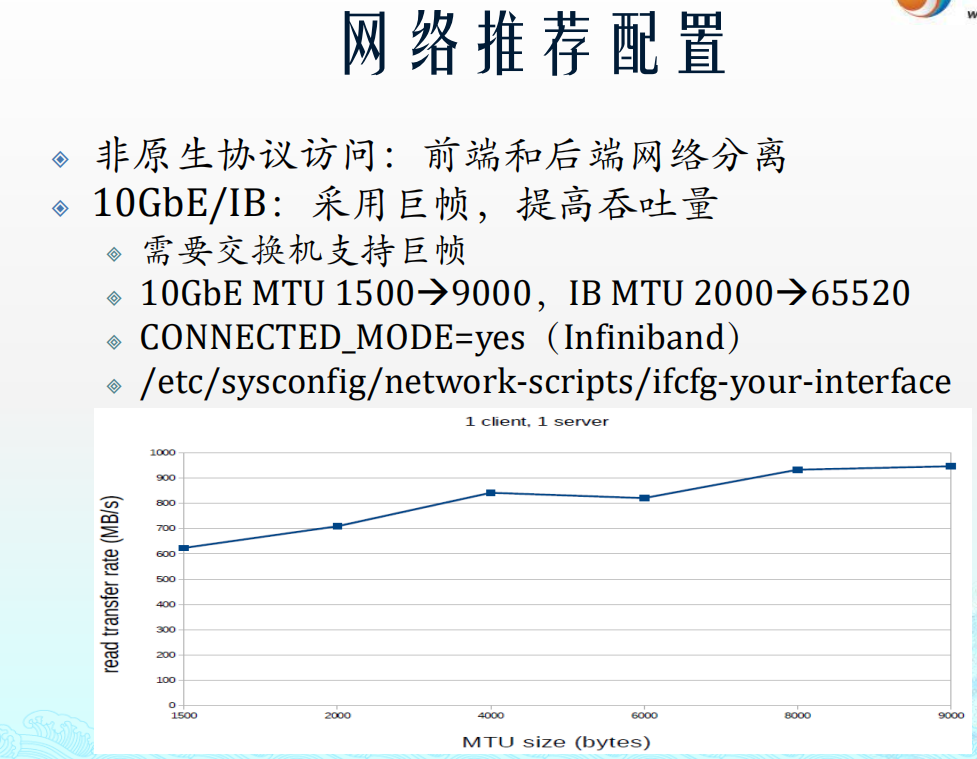
系统配置 根据Workload选择适当的Volume类型 Volume类型 DHT – 高性能,无冗余 AFR – 高可用,读性能高 STP – 高并发读,写性能低,无冗余 协议/性能 Native – 性能最优 NFS – 特定应用下可获得最优性能 CIFS – 仅Windows平台使用 数据流 不同访问协议的数据流差异 系统硬件配置 节点和集群配置 多CPU-支持更多的并发线程 多MEM-支持更大的Cache 多网络端口-支持更高的吞吐量 专用后端网络用于集群内部通信 NFS/CIFS协议访问需要专用后端网络 推荐至少10GbE Native协议用于内部节点通信 性能相关经验 GlusterFS性能很大程度上依赖硬件 充分理解应用基础上进行硬件配置 缺省参数主要用于通用目的 GlusterFS存在若干性能调优参数 性能问题应当优先排除磁盘和网络故障
Brick推荐配置
12块磁盘/RAID6 LUN,1 LUN/brcik RAID条带大小:256KB Readahead:64MB /sys/block/sdb/queue/read_ahead_kb /sys/block/sda/queue/max_sectors_kb LVM/XFS需要RAID对齐 pvcreate –dataalignment 2560K mkfs.xfs –i size=512 –n size=8192 –d su=256k,sw=10 I/O scheduler:deadline /sys/block/sda/queue/scheduler Mount options:inode64
系统调优
关键调优参数 Performance.write-behind-window-size 65535 (字节) Performance.cache-refresh-timeout 1 (秒) Performance.cache-size 1073741824 (字节) Performance.read-ahead off (仅1GbE) Performance.io-thread-count 24 (CPU核数) Performance.client-io-threads on (客户端) performance.write-behind on performance.flush-behind on cluster.stripe-block-size 4MB (缺省128KB) Nfs.disable off (缺省打开) 缺省参数设置适用于混合workloads 不同应用调优 理解硬件/固件配置及对性能的影响 如CPU频率 KVM优化 使用QEMU-GlusterFS(libgfapi)整合方案 gluster volume set <volume> group virt tuned-adm profile rhs-virtualization KVM host: tuned-adm profile virtual-host Images和应用数据使用不同的volume 每个gluster节点不超过2个KVM Host (16 guest/host) 提高响应时间 减少/sys/block/vda/queue/nr_request Server/Guest:128/8 (缺省企值256/128) 提高读带宽 提高/sys/block/vda/queue/read_ahead_kb VM readahead:4096 (缺省值128)
1 为Glusterfs扩容
gluster volume remove-brick gv0 replica 2 10.240.37.112:/data/brick/gfs1/ force 在复制卷中有3个节点 删除1个节点命令
gluster volume info
查看已创建挂载卷
gluster volume start gv0 启动挂载卷
gluster volume stop gv0
#删除前,先停止挂载卷
gluster volume delete gv0 删除
扩展卷
可以在线扩展卷的容量,可以加一个brick到分布卷,来增加分布卷的容量。同样可以增加一组brick到分布式复制卷,来增加卷的容量
要扩大副本数为2分布式复制卷,您需要增加2的倍数加brick(如4,6,8,等)。
1、添加服务器到集群
# gluster peer probe 10.240.37.112
Probe successful
2、添加新的brick到test-volume卷
# gluster volume add-brick gv0 10.240.37.112:/data/brick/gfs1
Add Brick successful
3、检查卷信息
# gluster volume info
[root@glusterfs1 vols]# gluster volume set meizi auth.allow 192.168.^C109
[root@glusterfs1 vols]# gluster volume set meizi auth.reject 192.168.1.104