一、在线库不支持在线复杂查询
做在线业务的开发者经常会碰到这样的难题:在线数据库上面运行稍微复杂点的查询,在线业务就挂了!不管是单机数据库如MySQL、PG,还是分布式数据库,HBase、MongoDB、Cassandra都有这个问题。下面,本文就以HBase为例对该问题进行说明,其他库原理类似。
HBase作为海量在线存储引擎,被广泛应用于推荐、风控、物联网、画像、表单等大数据场景。Phoenix作为HBase的SQL层,极大降低了用户使用门槛,并且实现了二级索引、加盐表、动态列等大量实用功能。HBase底层存储基于LSM,LSM能将业务的随机写转为顺序写,能有效提升写吞吐,但是其查询只适合于Rowkey的前缀匹配,查询模式单一;Phoenix二级索引,底层是跟原表关联的索引表,同样也是前缀匹配,一个表可以有多个索引,这样可以增加查询模式,但是索引数目不能太多,否则写放大的问题会比较严重。
对于更加复杂的查询场景,比如表单、日志查询里面的模糊查找,用户画像里面的随机条件组合等等,HBase + Phoenix的组合就不能支持。该问题是基于LSM的NoSQL在线数据库的通用问题,除了HBase,Cassandra、LevelDB、RocksDB、MongoDB引擎等都有相同的问题。
有开发者选择在备库上做复杂查询,不过前面提到在线库本身的查询能力往往有限,要么很慢,要么就查不出来,满足不了在线复杂查询的实时性要求。
二、双写遇到的问题

为了解决问题1,用户自然会想到借助检索引擎,比如ES、Solr、Lucene等来解决该问题。不少用户选择的是双写的方式,也就是每一条记录同时写在线库和检索引擎,该方式看起来简单,但实际使用过程中问题很多。我们了解到的case,把这套方案解决较好的客户往往都是要投入月级别的时间和大量人力。下面以双写HBase和Solr为例,举几个用户遇到比较多的问题。
- 一致性难以保证
双写很难保证在线库跟检索引擎的一致性。比如,两个链接并发双写,并且有修改的操作,那么很难保证HBase中同一字段的写入顺序跟Solr中同一个doc的修改顺序一致,那HBase和Solr中数据就出现了不一致,而且出现问题很难排查;另外,在线库往往只需要保存最近一段时间的数据,超过TTL的数据会被自动清理掉,而Solr中同样会有这个需求。但是HBase是按照KV做TTL的,Solr是按照doc,那两者在做数据清理的时候同样会出现不一致。不一致的场景有很多,这里就不一一介绍了。
- 写入性能下降
相同配置下,HBase的吞吐要比Solr高很多,这源于软件设计的出发点不同,优化的方向不同等诸多因素。如果双写,那势必会导致Solr的写吞吐限制了HBase的写吞吐。
- 历史数据的同步
双写只是解决了新数据的问题,对于历史数据则不适用,用户需要自己解决历史数据批量同步问题。特别是,对于不能停机的场景,在历史数据rebuild过程中,如何解决跟新数据跟历史数据相互覆盖的问题,也是十分棘手的问题。
- 冗余存储空间
检索引擎专门解决索引问题,其数据存储格式要比在线库要更复杂,一份在线库的数据在检索引擎中可能需要存储多份,比如原始数据存储,倒排索引存储,为提升聚合和排序的列存DocValue的存储。那么,势必有存储冗余的问题,如何降成本也是一大挑战。
- 稳定性
双写要求HBase和Solr同时保证稳定性,如果Solr出现故障,写流程会被block住,对在线业务造成影响。
三、HBase + Solr易用性不足
阿里云HBase Solr全文检索引擎,采用在系统层做数据转换和同步的方式一站式解决了用户使用双引擎遇到的大部分问题。但是,试用过的用户会有一个体会,就是使用太灵活了,步骤也比较繁琐,容易出问题,如果不是资深玩家难以驾驭。下面举几个用户痛点:
- 使用门槛高
用户需要同时理解HBase、Solr、Indexer(数据同步服务),同时操作HBase Shell,Indexer命令行,Solr界面三个途径才能把流程走通。
- Schemaless的HBase跟强Schema的Solr数据类型
难以保证对齐
首先,用户要自己定义从HBase column到Solr field的映射;其次,用户要自己保证实际写入到HBase中的类型正确。比如HBase中一个列对应Solr中一个long类型,因为HBase API并不检查用户实际写入的数值是否合法,导致写入HBase成功,但是同步到Solr是通不过的。这就要求用户要自己基于HBase API写一套类型检查系统,费时费力。
- HBase + Solr对于数据冗余存储的问题解决不友好
用户需要自己决定Solr中是否开启stored,docValued选项,对于只开启indexed选项的Field,用户可以通过回读HBase的方式来拿到最终结果数据,而对于开启了stored或者docValued的Field,直接从Solr中返回结果性能会更好。这套优化的逻辑需要用户自己管理和实现。
四、SearchIndex灵活易用一体化在线库引擎
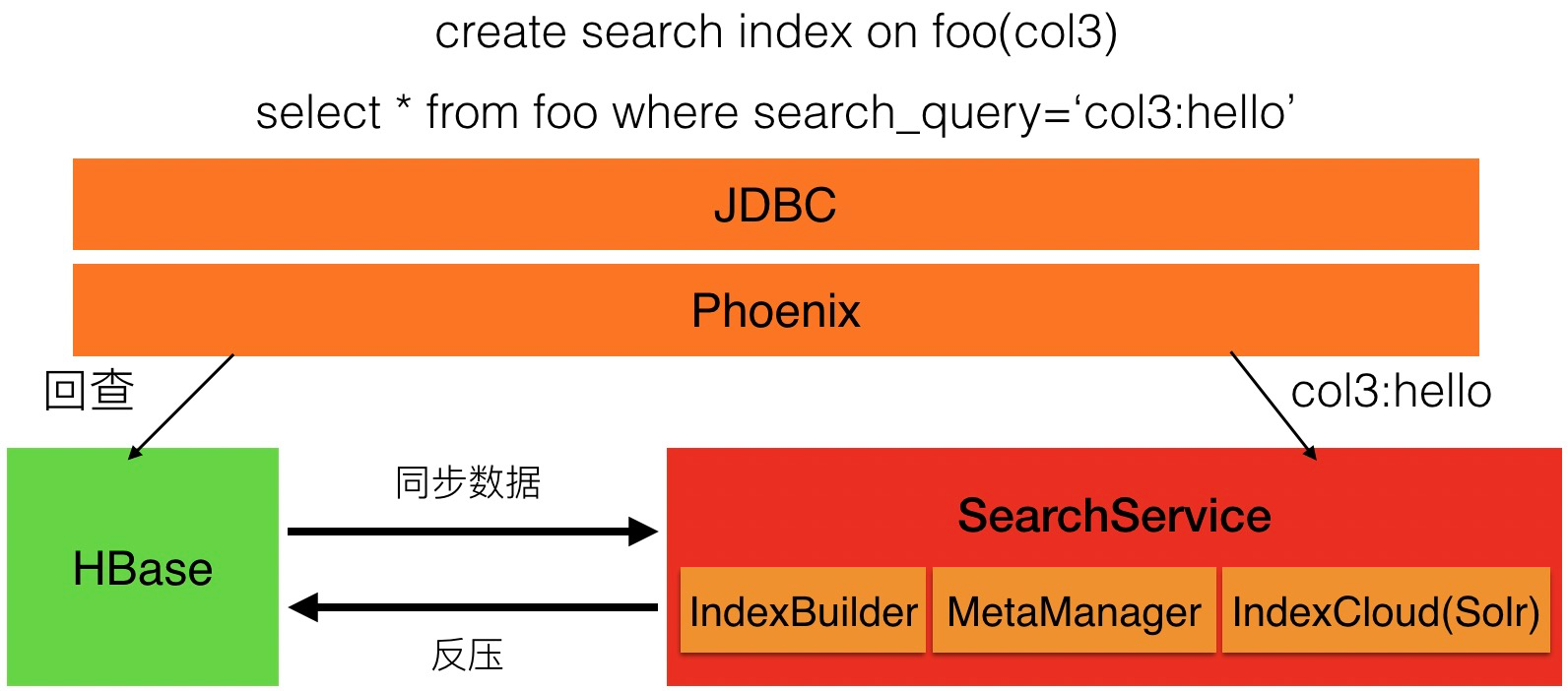
SearchIndex是阿里云HBase SQL(Phoenix)基于HBase + Solr双引擎的新的索引实现,其架构如上图所示。Phoenix层将SQL(DDL、DML)语句转化为对HBase和Solr的具体操作,SearchService负责索引同步,一致性,元数据管理等。
SearchService内部会统一管理HBase中TimeStamp和Solr中DocVersion的对应关系,来实现最终一致性。简单来说,Solr一行数据的DocVersion等于当前已被同步的HBase对应行各个column的TimeStamp最大值,在解决乱序时,如果前面新的cell已经被同步了,老的cell则被直接丢掉即可。而对于TTL问题,我们实现了基于行的HBase Compaction机制,来保证一致性。
SearchIndex解决了前面提到的所有问题,用户只需要几分钟,几条SQL语句就可以跑通整个流程,可参考快速开始文档;Phoenix强类型直接映射Solr类型,并支持分词、Array等复杂类型;自适应回查的优化策略更好解决了数据冗余存储问题。相比于HBase Solr全文检索引擎,大大提高了易用性,并且覆盖绝大部分的场景和需求。但目前SearchIndex还不能完全取代HBase + Solr,对于资深玩家,比较喜欢直接写HBase API和Solr API带来的灵活性,仍然可以选择使用HBase Solr全文检索引擎的方式。
SearchIndex是针对阿里云公共云客户定制开发的一体化云原生在线NoSQL数据库引擎,具有低成本、灵活、易用、稳定等特点,已经被用于物流巴枪、线下支付表单、电商表单、医药实验日志等行业和场景,用户数据量已达数百亿规模,经历过双十一的考验。用户第一步可以只购买HBase实例,全文服务和SQL服务可以后续单独开通,单独升级管理。欢迎感兴趣的开发者共同交流。
本文作者: Roin123
本文为云栖社区原创内容,未经允许不得转载。