用文本编辑器打开一个文件就是把一个文件读入了内存中 ,所以打开文件的操作也是在内存中的,断电即消失,所以若要保存其内容就必须点击保存让其存入硬盘中
python解释器执行py文件的原理 :
第一阶段:python解释器启动,此时就相当于启动了一个文本编辑器
第二阶段:python解释器相当于文本编辑器,去打开test.py文件,从硬盘上将test.py的文件内容读入到内存中(小复习:pyhon的解释性,决定了解释器只关心文件内容,不关心文件后缀名)
第三阶段:python解释器解释执行刚刚加载到内存中test.py的代码( ps:在该阶段,即执行时,才会识别python的语法,执行文件内代码,执行到name="jack",会开辟内存空间存放字符串"jack")
总结:python解释器于文件本编辑的异同
相同点:python解释器是解释执行文件内容的,因而python解释器具备读py文件的功能,这一点与文本编辑器一样
不同点:文本编辑器将文件内容读入内存后,是为了显示/编辑,而python解释器将文件内容读入内存后,是为了执行(执行前会识别python语法)
what's the 字符编码?
字符编码:将人输入的字符转换成计算机能识别的二进制数字的过程的定义的标准就叫字符编码。
字符=====(字符编码)====>二进制数
由于计算机起源于美国,所以一开始设置的字符编码只针对英文。最早的字符编码叫ASCII码,后来为了满足更多国家的文字的需求,又定制了其他的字符编码。如中国的是GBK,日本的是shift_JIS,韩国是Euc_kr等等。
ASCII码:一个Bytes代表一个字符(英文字符/键盘上的所有其他字符),1Bytes=8bit,8bit可以表示0-2**8-1种变化,即可以表示256个字符。(ASCII最初只用了后七位,127个数字,已经完全能够代表键盘上所有的字符了(英文字符/键盘的所有其他字符)后来为了将拉丁文也编码进了ASCII表,将最高位也占用了)
GBK:2Bytes代表一个字符(一个中文)
因为每个国家有他们自己的标准,若同时使用多种语言时,标准不同会造成乱码,这就需要设置一个通用的万国标准,这就是Unicode和UTF-8
unicode:统一用2Bytes代表一个字符;优点是字符->数字的转换速度快,缺点是占用空间大,因为英文只需1Bytes,而他统一使用2Bytes,就会造成资源浪费及占用空间大
UTF-8:对英文字符只用1Bytes表示,对中文字符用3Bytes;优点是节省空间,缺点是:字符->数字的转换速度慢,因为每次都需要计算出字符需要多长的Bytes才能够准确表示
注:存储时,python2默认ASCII码,python3默认UTF-8,可在文件开头输入#-*-coding:utf-8-*-,来指定解释器用什么字符编码
规定:
- 内存中使用的编码是unicode,用空间换时间(程序都需要加载到内存才能运行,因而内存应该是尽可能的保证快)
- 硬盘中或者网络传输用utf-8,网络I/O延迟或磁盘I/O延迟要远大与utf-8的转换延迟,而且I/O应该是尽可能地节省带宽,保证数据传输的稳定性。

注解:所有程序,最终都要加载到内存,程序保存到硬盘中不同的国家使用的是不同的编码格式,但是到内存中我们必须兼容万国
(计算机可以运行任何国家的程序原因在于此),所以统一且固定使用unicode。
你可能会说兼容万国utf-8也可以,确实可以,完全可以正常工作,之所以不用是因为unicode比utf-8更高效
(uicode固定用2个字节编码,utf-8则需要计算),但是unicode更浪费空间,没错,这就是用空间换时间的一种
做法。而存放到硬盘,或者网络传输,都需要把unicode转成utf-8,因为数据的传输,追求的是稳定,高效,数据
量越小数据传输就越靠谱,于是都转成utf-8格式的,而不是unicode。
重点!:文件在内存中使用的是Unicode,若要保存到硬盘中就要经过encode存为UTF-8,硬盘中的文件是以UTF-8的形式存储的,若要调用就必须经过decode成Unicode加载到内存中

注:在文件编辑器的右下角可以选择字符编码,一般情况下默认为UTF-8
乱码的产生有两种情况:
一、一份文件包含有各国语言,若保存时用的是某个国家的标准而不是万国标准的话,其他非本国的语言的文字就会以乱码的形式被保存,以后再调用时一直为乱码,等于文件被损坏,乱码无法复原。
二、一份文件以自己国家的标准的形式保存,在调用时用了其他的标准时,因为无法加载就会产生乱码,此时的乱码通过变为原来的标准就可以恢复
结论:要避免乱码的产生,最好的方法就是以什么字符编码保存就以什么字符编码打开
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器
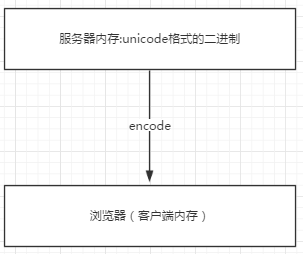
如果服务端encode的编码格式是utf-8, 客户端内存中收到的也是utf-8编码的二进制。
what's the 文件处理?
文件处理的流程为:
- 打开文件,得到文件句柄并赋值给一个变量
- 通过句柄对文件进行操作
- 关闭文件
文件打开模式:文件句柄 = open('文件路径', '模式')
注:打开文件时,需要指定文件路径和以何等方式打开文件,打开后,即可获取该文件句柄,日后通过此文件句柄对该文件操作。
open:
1 会向操作系统发起系统调用,操作会打开一个文件
2 在python程序中会产生一个值指向操作系统打开的那个文件,我们可以把该值赋值一个变量
回收资源:f.close() 一定要做,关闭操作系统打开的文件,即回收操作系统的资源
打开文件的模式有:
- r ,只读模式【默认模式,文件必须存在,不存在则抛出异常】
- w,只写模式【不可读;不存在则创建;存在则清空内容】
- x, 只写模式【不可读;不存在则创建,存在则报错】(基本不用)
- a, 追加模式【可读; 不存在则创建;存在则只追加内容】
#r,文本文件:只读模式,文件不存在报错 f=open(r'aaaa.py','r',encoding='utf-8') print(f.read()) print(f.readlines()) print(f.readable()) print(f.writable()) #False f.close() #w,文本文件:只写模式,文件不存在则创建空文件,文件存在则清空 f=open('new.txt','w',encoding='utf-8') f.write('1111111 ') f.writelines(['22222 ','3333 ','444444 ']) # print(f.writable()) f.close() #a,文本文件:只追加写模式,文件不存在则创建,文件存在 f=open('new_2','a',encoding='utf-8') print(f.readable()) print(f.writable()) f.write('33333 ') f.write('44444 ') f.writelines(['5555 ','6666 ']) f.close()
"+" 表示可以同时读写某个文件
- r+, 读写【可读,可写】
- w+,写读【可读,可写】
- x+ ,写读【可读,可写】
- a+, 写读【可读,可写】
"b"表示以字节的方式操作
- rb 或 r+b
- wb 或 w+b
- xb 或 w+b
- ab 或 a+b
注:以b方式打开时,读取到的内容是字节类型,写入时也需要提供字节类型,不能指定编码
flush原理:
1、文件操作是通过软件将文件从硬盘读到内存
2、写入文件的操作也都是存入内存缓冲区buffer(内存速度快于硬盘,如果写入文件的数据都从内存刷到硬盘,内存与硬盘的速度延迟会被无限放大,效率变低,所以要刷到硬盘的数据我们统一往内存的一小块空间即buffer中放,一段时间后操作系统会将buffer中数据一次性刷到硬盘)
3、flush即强制将写入的数据刷到硬盘
读取的进度条,或者叫滚动条的代码:
import time for i in range(10): print('#',end='',flush=True) time.sleep(0.2) else: print()
文件内光标的移动:
一: read(3):
1. 文件打开方式为文本模式时,代表读取3个字符
2. 文件打开方式为b模式时,代表读取3个字节
二: 其余的文件内光标移动都是以字节为单位如seek,tell,truncate
注意:
1. seek有三种移动方式0,1,2,其中1和2必须在b模式下进行,但无论哪种模式,都是以bytes为单位移动的
2. truncate是截断文件,所以文件的打开方式必须可写,但是不能用w或w+等方式打开,因为那样直接清空文件了,所以truncate要在r+或a或a+等模式下测试效果
上下文管理(即创建一个新文件,在源文件中读一行就在新文件中写一行)
with open('a.txt','r') as read_f,open('b.txt','w') as write_f: data=read_f.read() write_f.write(data)
循环读取每一行的内容:
with open('a.txt','r',encoding='utf-8') as f: while True: line=f.readline()#只适用于小文件 if not line:break print(line,end='')
文件的修改:
import os with open('a.txt','r',encoding='utf-8') as read_f, open('a.txt.swap','w',encoding='utf-8') as write_f: for line in read_f: write_f.write(line.replace('alex_BSB','BB_alex_SB')) os.remove('a.txt') os.rename('a.txt.swap','a.txt')