项目背景
在实际项目中,输入数据往往是由许多小文件组成,这里的小文件是指小于HDFS系统Block大小的文件(默认128M),早期的版本所定义的小文件是64M,这里的hadoop-2.2.0所定义的小文件是128M。然而每一个存储在HDFS中的文件、目录和块都映射为一个对象,存储在NameNode服务器内存中,通常占用150个字节。 如果有1千万个文件,就需要消耗大约3G的内存空间。如果是10亿个文件呢,简直不可想象。所以在项目开始前, 我们要先了解一下 hadoop 处理小文件的各种方案,然后本课程选择一种适合的方案来解决本项目的小文件问题。Hadoop 自身提供了几种机制来解决相关的问题,包括HAR, SequeueFile和CombineFileInputFormat。
项目介绍
在本地 D://Code/EclipseCode/mergeSmallFilesTestData目录下有 2018-03-23 至 2018-03-29 一共7天的数据集,我们需要将这7天的数据集按日期合并为7个大文件上传至 HDFS。

思路分析
基于项目的需求,我们通过下面几个步骤完成:
1)首先通过 globStatus()方法过滤掉 svn 格式的文件,获取 D://Code/EclipseCode/mergeSmallFilesTestData目录下的其它所有文件路径。
2)然后循环第一步的所有文件路径,通过globStatus()方法获取所有 txt 格式文件路径。
3)最后通过IOUtils.copyBytes(in, out, 4096, false)方法将数据集合并为7个大文件,并上传至 HDFS。
程序
在Hadoop项目路径下新建MergeSmallFilesToHDFS.java:
/**
*
*/
package com.hadoop.train;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FSDataInputStream;
import org.apache.hadoop.fs.FSDataOutputStream;
import org.apache.hadoop.fs.FileStatus;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.FileUtil;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.fs.PathFilter;
import org.apache.hadoop.io.IOUtils;
/**
* @author Zimo
* 合并小文件到HDFS
*
*/
public class MergeSmallFilesToHDFS {
private static FileSystem hdfs = null; //定义HDFS上的文件系统对象
private static FileSystem local = null; //定义本地文件系统对象
/**
*
* @function 过滤 regex 格式的文件
*
*/
public static class RegexExcludePathFilter implements PathFilter
{
private final String regex;
public RegexExcludePathFilter(String regex) {
// TODO Auto-generated constructor stub
this.regex = regex;
}
@Override
public boolean accept(Path path) {
// TODO Auto-generated method stub
boolean flag = path.toString().matches(regex);
return !flag;
}
}
/**
*
* @function 接受 regex 格式的文件
*
*/
public static class RegexAcceptPathFilter implements PathFilter
{
private final String regex;
public RegexAcceptPathFilter(String regex) {
// TODO Auto-generated constructor stub
this.regex = regex;
}
@Override
public boolean accept(Path path) {
// TODO Auto-generated method stub
boolean flag = path.toString().matches(regex);
return flag;
}
}
/**
* @param args
* @throws IOException
* @throws URISyntaxException
*/
public static void main(String[] args) throws URISyntaxException, IOException {
// TODO Auto-generated method stub
list();
}
private static void list() throws URISyntaxException, IOException {
// TODO Auto-generated method stub
Configuration conf = new Configuration();//读取Hadoop配置文件
//设置文件系统访问接口,并创建FileSystem在本地的运行模式
URI uri = new URI("hdfs://Centpy:9000");
hdfs = FileSystem.get(uri, conf);
local = FileSystem.getLocal(conf);//获取本地文件系统
//过滤目录下的svn文件
FileStatus[] dirstatus = local.globStatus(new Path("D://Code/EclipseCode/mergeSmallFilesTestData/*"),
new RegexExcludePathFilter("^.*svn$"));
//获取D:CodeEclipseCodemergeSmallFilesTestData目录下的所有文件路径
Path[] dirs = FileUtil.stat2Paths(dirstatus);
FSDataOutputStream out = null;
FSDataInputStream in = null;
for(Path dir:dirs)
{//比如拿2018-03-23为例
//将文件夹名称2018-03-23的-去掉,直接,得到20180323文件夹名称
String fileName = dir.getName().replace("-", "");//文件名称
//只接受2018-03-23日期目录下的.txt文件
FileStatus[] localStatus = local.globStatus(new Path(dir + "/*"),
new RegexAcceptPathFilter("^.*txt$"));
// 获得2018-03-23日期目录下的所有文件
Path[] listPath = FileUtil.stat2Paths(localStatus);
// 输出路径
Path outBlock = new Path("hdfs://Centpy:9000/mergeSmallFiles/result/"+ fileName + ".txt");
System.out.println("合并后的文件名称:"+fileName+".txt");
// 打开输出流
out = hdfs.create(outBlock);
//循环操作2018-03-23日期目录下的所有文件
for(Path p:listPath)
{
in = local.open(p);// 打开输入流
IOUtils.copyBytes(in, out, 4096, false);// 复制数据
in.close();// 关闭输入流
}
if (out != null) {
out.close();// 关闭输出流
}
}
}
}
测试结果
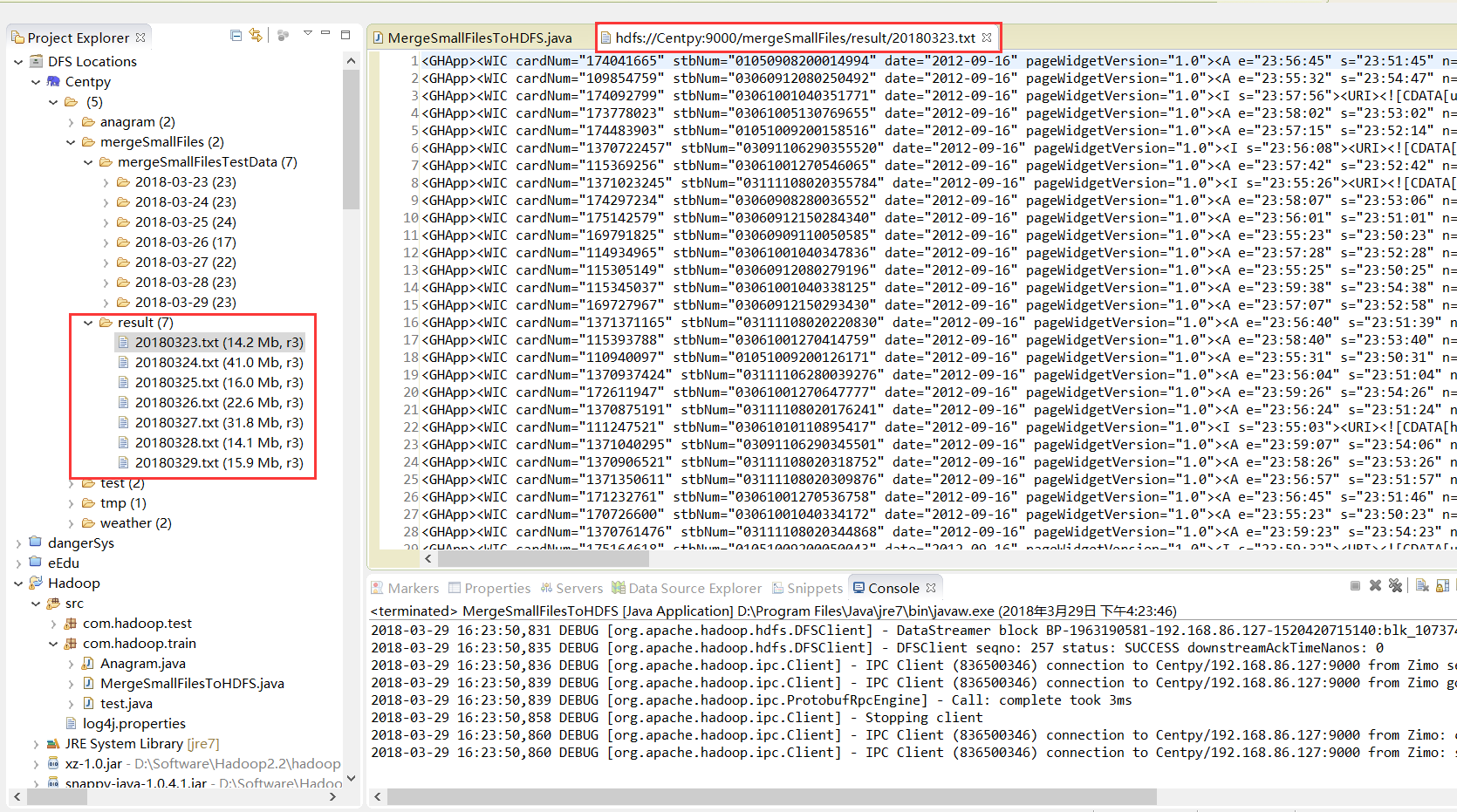
运行程序之后会将本地D://Code/EclipseCode/mergeSmallFilesTestData路径下的每个文件夹下的n个.txt文件内容合并到一个.txt文件中,并存放到指定的HDFS路径("hdfs://Centpy:9000/mergeSmallFiles/result/")下。
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!
版权声明:本文为博主原创文章,未经博主允许不得转载。