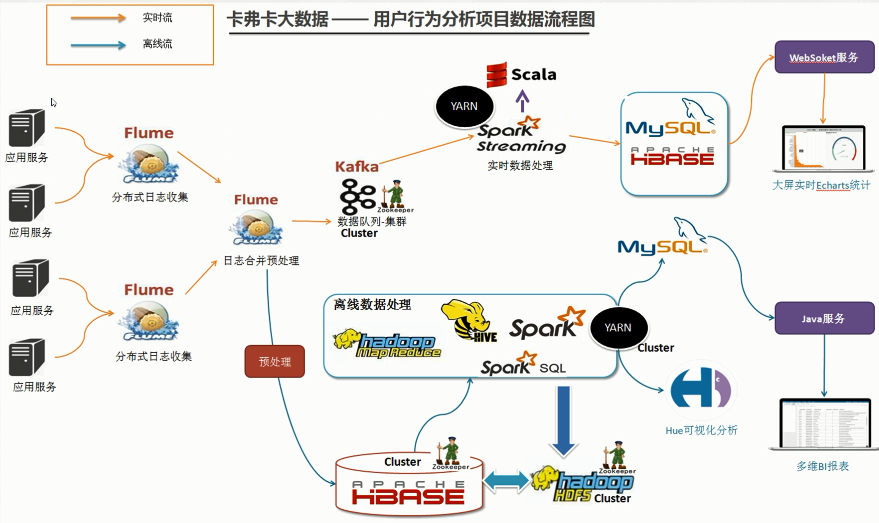
Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集、聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(可定制)的能力。
1.flume节点服务设计
2.下载Flume并安装
1)下载Apache版本的Flume。
2)下载Cloudera版本的Flume。
3)这里选择下载Apache版本的apache-flume-1.7.0-bin.tar.gz ,然后上传至bigdata-pro01.kfk.com节点/opt/softwares/目录下
4)解压Flume
[kfk@bigdata-pro01 softwares]$ tar -zxf apache-flume-1.7.0-bin.tar.gz -C ../modules/ [kfk@bigdata-pro01 softwares]$ cd ../modules/ [kfk@bigdata-pro01 modules]$ ls apache-flume-1.7.0-bin hadoop-2.6.0 hbase-0.98.6-cdh5.3.0 jdk1.8.0_60 kafka_2.11-0.8.2.1 zookeeper-3.4.5-cdh5.10.0 [kfk@bigdata-pro01 modules]$ mv apache-flume-1.7.0-bin/ flume-1.7.0-bin/
5)将flume分发到其他两个节点
scp -r flume-1.7.0-bin bigdata-pro02.kfk.com:/opt/modules/ scp -r flume-1.7.0-bin bigdata-pro03.kfk.com:/opt/modules/
3.flume agent-1采集节点服务配置
1)bigdata-pro02.kfk.com节点配置flume,将数据采集到bigdata-pro01.kfk.com节点
从notepad++新建一个连接到第二个节点,然后将conf下的所有文件进行重命名,去掉 .template后缀。
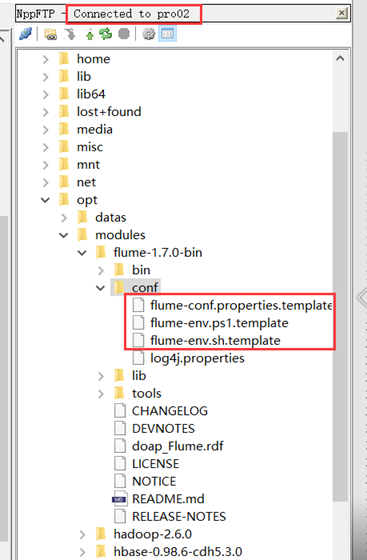
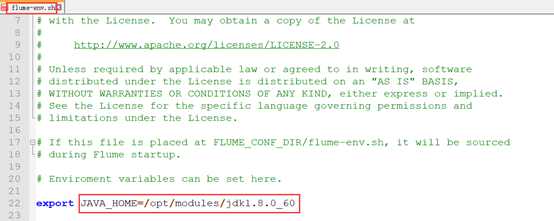
先配置Java环境变量:
然后配置flume-conf.properties文件,重点是对上面流程图中source、channel和sink三个线程进行配置。
由于所给的模板配置不全,并且格式也有点乱,所有我们全部干掉,然后填入下面的内容。
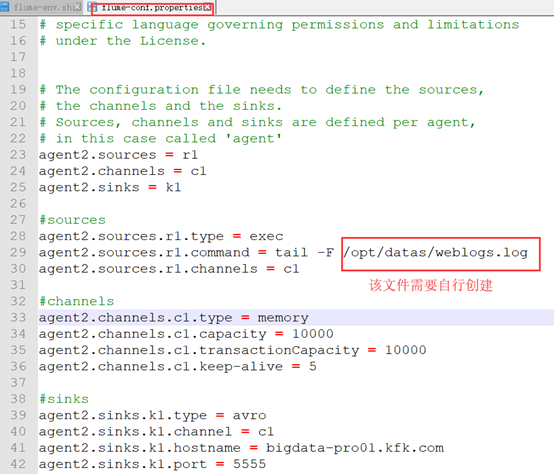
agent2.sources = r1 agent2.channels = c1 agent2.sinks = k1 agent2.sources.r1.type = exec agent2.sources.r1.command = tail -F /opt/datas/weblogs.log agent2.sources.r1.channels = c1 agent2.channels.c1.type = memory agent2.channels.c1.capacity = 10000 agent2.channels.c1.transactionCapacity = 10000 agent2.channels.c1.keep-alive = 5 agent2.sinks.k1.type = avro agent2.sinks.k1.channel = c1 agent2.sinks.k1.hostname = bigdata-pro01.kfk.com agent2.sinks.k1.port = 5555
2号和3号节点负责对应用服务器的日志进行收集,使用它们的source是exec(命令行的标准输出),然后通过sink端(avro类型)推送给1号机器进行日志合并处理。如下图红框中所示:

Flume官网给出的配置讲解也是非常的全面,大家可以去阅读以下,并且学会根据官网指南进行自定义的配置。
2)将以上配置发送到3号节点。
scp -r flume-1.7.0-bin/ bigdata-pro03.kfk.com:/opt/modules/
然后将配置文件中的agent2全部改为agent3,以实现将数据采集到bigdata-pro01.kfk.com节点的功能。
记得创建weblogs文件!
[kfk@bigdata-pro03 ~]$ cd /opt/datas/ [kfk@bigdata-pro03 datas]$ touch weblogs.log [kfk@bigdata-pro03 datas]$ ls weblogs.log
以上就是博主为大家介绍的这一板块的主要内容,这都是博主自己的学习过程,希望能给大家带来一定的指导作用,有用的还望大家点个支持,如果对你没用也望包涵,有错误烦请指出。如有期待可关注博主以第一时间获取更新哦,谢谢!同时也欢迎转载,但必须在博文明显位置标注原文地址,解释权归博主所有!