简介
自然界不存在两片完全一样的雪花,每一片都是独一无二的,雪花算法的命名由此而来,所有雪花算法表示生成的ID唯一,且生成的ID是按照一定的结构组成。
组成结构
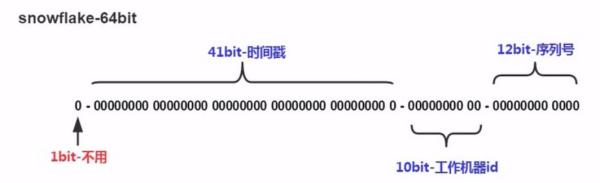
上图可以看到雪花算法的结构由四部分组成,首位无效符,所以我们主要看后面三部分
- 第一部分:由41位的时间戳组成,可以提高查询速度。
- 第二部分:由10位机器码组成,适用于分布式环境下各节点进行标记,10位的长度最多支持部署1024个节点。
- 第三部分:由12位序列号组成,可以同一节点同一毫秒生成多个2^12 - 1(4095)个ID序号。
由于生成的id按时间戳生成,所以ID是按时间递增
分布式系统内不会产生重复ID
使用
环境: .Net Core 3.0
先NuGet一下SnowFlake,这里使用的是Snowflake.Core
下面是实例Demo


private static List<string> list = new List<string>(); static void Main(string[] args) { Snowflake.Core.IdWorker work = new Snowflake.Core.IdWorker(1, 1); for (int i = 0; i < 1000; i++) { var id = work.NextId(); if (list.Contains(id.ToString())) { Console.WriteLine("存在"); } else { list.Add(id.ToString()); Console.WriteLine(id.ToString()); } } }
使用时创建IdWorder对象需要单例,如果重复创建会造成重复生成重复ID
最后附上源码
/** * Twitter的分布式自增ID雪花算法snowflake * @author MENG * @create 2018-08-23 10:21 **/ public class SnowFlake { /** * 起始的时间戳 */ private final static long START_STMP = 1480166465631L; /** * 每一部分占用的位数 */ private final static long SEQUENCE_BIT = 12; //序列号占用的位数 private final static long MACHINE_BIT = 5; //机器标识占用的位数 private final static long DATACENTER_BIT = 5;//数据中心占用的位数 /** * 每一部分的最大值 */ private final static long MAX_DATACENTER_NUM = -1L ^ (-1L << DATACENTER_BIT); private final static long MAX_MACHINE_NUM = -1L ^ (-1L << MACHINE_BIT); private final static long MAX_SEQUENCE = -1L ^ (-1L << SEQUENCE_BIT); /** * 每一部分向左的位移 */ private final static long MACHINE_LEFT = SEQUENCE_BIT; private final static long DATACENTER_LEFT = SEQUENCE_BIT + MACHINE_BIT; private final static long TIMESTMP_LEFT = DATACENTER_LEFT + DATACENTER_BIT; private long datacenterId; //数据中心 private long machineId; //机器标识 private long sequence = 0L; //序列号 private long lastStmp = -1L;//上一次时间戳 public SnowFlake(long datacenterId, long machineId) { if (datacenterId > MAX_DATACENTER_NUM || datacenterId < 0) { throw new IllegalArgumentException("datacenterId can't be greater than MAX_DATACENTER_NUM or less than 0"); } if (machineId > MAX_MACHINE_NUM || machineId < 0) { throw new IllegalArgumentException("machineId can't be greater than MAX_MACHINE_NUM or less than 0"); } this.datacenterId = datacenterId; this.machineId = machineId; } /** * 产生下一个ID * * @return */ public synchronized long nextId() { long currStmp = getNewstmp(); if (currStmp < lastStmp) { throw new RuntimeException("Clock moved backwards. Refusing to generate id"); } if (currStmp == lastStmp) { //相同毫秒内,序列号自增 sequence = (sequence + 1) & MAX_SEQUENCE; //同一毫秒的序列数已经达到最大 if (sequence == 0L) { currStmp = getNextMill(); } } else { //不同毫秒内,序列号置为0 sequence = 0L; } lastStmp = currStmp; return (currStmp - START_STMP) << TIMESTMP_LEFT //时间戳部分 | datacenterId << DATACENTER_LEFT //数据中心部分 | machineId << MACHINE_LEFT //机器标识部分 | sequence; //序列号部分 } private long getNextMill() { long mill = getNewstmp(); while (mill <= lastStmp) { mill = getNewstmp(); } return mill; } private long getNewstmp() { return System.currentTimeMillis(); } public static void main(String[] args) { SnowFlake snowFlake = new SnowFlake(1, 1); long start = System.currentTimeMillis(); for (int i = 0; i < 1000000; i++) { System.out.println(snowFlake.nextId()); } System.out.println(System.currentTimeMillis() - start); } }
总结
组成结构大致分为了无效位、时间位、机器位和序列号位。其特点是自增、有序、纯数字组成查询效率高且不依赖于数据库。适合在分布式的场景中应用,可根据需求调整具体实现细节。
