生产者消费者的实际使用
我相信大家都有使用过分布式消息队列,比如 ActiveMQ、kafka、RabbitMQ 等等,消息队列的是有可以使得程序之间实现解耦,提升程序响应的效率。如果我们把多线程环境比作是分布式的话,那么线程与线程之间是不是也可以使用这种消息队列的方式进行数据通信和解耦呢?
阻塞队列的使用案例
注册成功后增加积分
假如我们模拟一个场景,就是用户注册的时候,在注册成功以后发放积分。这个场景在一般来说,我们会这么去实现:
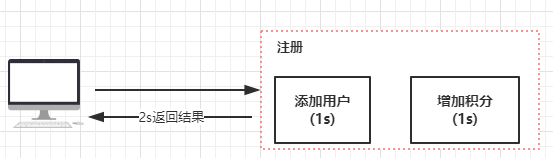
但是实际上,我们需要考虑两个问题
1. 性能,在注册这个环节里面,假如添加用户需要花费 1 秒钟,增加积分需要花费 1 秒钟,那么整个注册结果的返回就可能需要大于 2 秒,虽然影响不是很大,但是在量比较大的时候,我们也需要做一些优化。
2. 耦合,添加用户和增加积分,可以认为是两个领域,也就是说,增加积分并不是注册必须要具备的功能,但是一旦增加积分这个逻辑出现异常,就会导致注册失败。这种耦合在程序设计的时候是一定要规避的。
因此我们可以通过异步的方式来实现:
改造之前的代码逻辑:
public class UserService {
public boolean register() {
User user = new User();
user.setName("Mic");
addUser(user);
sendPoints(user);
return true;
}
public static void main(String[] args) {
new UserService().register();
}
private void addUser(User user) {
System.out.println("添加用户:" + user);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
private void sendPoints(User user) {
System.out.println(" 发 送 积 分 给 指 定 用 户:" + user);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
改造之后的逻辑:
public class UserService {
private final ExecutorService single = Executors.newSingleThreadExecutor();
private volatile boolean isRunning = true;
ArrayBlockingQueue arrayBlockingQueue = new ArrayBlockingQueue(10);
{
init();
}
public void init() {
single.execute(() -> {
while (isRunning) {
try {
User user = (User) arrayBlockingQueue.take();//阻塞的方式获取队列中的数据
sendPoints(user);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
});
}
public boolean register() {
User user = new User();
user.setName("Mic");
addUser(user);
arrayBlockingQueue.add(user);//添加到异步
队列
return true;
}
public static void main(String[] args) {
new UserService().register();
}
private void addUser(User user) {
System.out.println("添加用户:" + user);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
private void sendPoints(User user) {
System.out.println(" 发 送 积 分 给 指 定 用 户:" + user);
try {
Thread.sleep(1000);
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
优化以后,整个流程就变成了这样:

在这个案例中,我们使用了 ArrayBlockingQueue 基于数组的阻塞队列,来优化代码的执行逻辑。
阻塞队列的应用场景
阻塞队列这块的应用场景,比较多的仍然是对于生产者消费者场景的应用,但是由于分布式架构的普及,是的大家更多的关注在分布式消息队列上。所以其实如果把阻塞队列比作成分布式消息队列的话,那么所谓的生产者和消费者其实就是基于阻塞队列的解耦。另外,阻塞队列是一个 fifo 的队列,所以对于希望在线程级别需要实现对目标服务的顺序访问的场景中,也可以使用J.U.C 中的阻塞队列。
J.U.C 提供的阻塞队列
在 Java8 中,提供了 7 个阻塞队列:
|
ArrayBlockingQueue
|
数组实现的有界阻塞队列, 此队列按照先进先出(FIFO)的原则
对元素进行排序。
|
|
LinkedBlockingQueue
|
链表实现的有界阻塞队列, 此队列的默认和最大长度为
Integer.MAX_VALUE。此队列按照先进先出的原则对元素进行
排序
|
|
PriorityBlockingQueue
|
支持优先级排序的无界阻塞队列, 默认情况下元素采取自然顺序
升序排列。也可以自定义类实现 compareTo()方法来指定元素
排序规则,或者初始化 PriorityBlockingQueue 时,指定构造
参数 Comparator 来对元素进行排序。
|
|
DelayQueue
|
优先级队列实现的无界阻塞队列
|
|
SynchronousQueue
|
不存储元素的阻塞队列, 每一个 put 操作必须等待一个 take 操
作,否则不能继续添加元素。
|
|
LinkedTransferQueue
|
链表实现的无界阻塞队列
|
|
LinkedBlockingDeque
|
链表实现的双向阻塞队列
|
阻塞队列的操作方法
在阻塞队列中,提供了四种处理方式:
1. 插入操作
add(e) :添加元素到队列中,如果队列满了,继续插入元素会报错,IllegalStateException。
offer(e) : 添加元素到队列,同时会返回元素是否插入成功的状态,如果成功则返回 trueput(e) :当阻塞队列满了以后,生产者继续通过 put添加元素,队列会一直阻塞生产者线程,知道队列可用。
offer(e,time,unit) :当阻塞队列满了以后继续添加元素,生产者线程会被阻塞指定时间,如果超时,则线程直接退出。
2. 移除操作
remove():当队列为空时,调用 remove 会返回 false,如果元素移除成功,则返回 true。
poll(): 当队列中存在元素,则从队列中取出一个元素,如果队列为空,则直接返回 null。
take():基于阻塞的方式获取队列中的元素,如果队列为空,则 take 方法会一直阻塞,直到队列中有新的数据可以消费。
poll(time,unit):带超时机制的获取数据,如果队列为空,则会等待指定的时间再去获取元素返回 。
ArrayBlockingQueue 队列原理分析详见博客
原子操作类
原子性这个概念,在多线程编程里是一个老生常谈的问题。所谓的原子性表示一个或者多个操作,要么全部执行完,要么一个也不执行。不能出现成功一部分失败一部分的情况。在多线程中,如果多个线程同时更新一个共享变量,可能会得到一个意料之外的值。比如 i=1 。A 线程更新 i+1 、B 线程也更新 i+1。通过两个线程并行操作之后可能 i 的值不等于 3。而可能等于 2。因为 A 和 B 在更新变量 i 的时候拿到的 i 可能都是 1这就是一个典型的原子性问题。前面我们讲过,多线程里面,要实现原子性,有几
种方法,其中一种就是加 Synchronized 同步锁。而从 JDK1.5 开始,在 J.U.C 包中提供了 Atomic 包,提供了对于常用数据结构的原子操作。它提供了简单、高效、以及线程安全的更新一个变量的方式。
J.U.C 中的原子操作类
由于变量类型的关系,在 J.U.C 中提供了 12 个原子操作的
类。这 12 个类可以分为四大类
1. 原子更新基本类型:AtomicBoolean、AtomicInteger、AtomicLong
2. 原子更新数组:AtomicIntegerArray、AtomicLongArray、AtomicReferenceArray
3. 原子更新引用:AtomicReference 、 AtomicReferenceFieldUpdater 、AtomicMarkableReference(更新带有标记位的引用类型)
4. 原子更新字段:AtomicIntegerFieldUpdater、AtomicLongFieldUpdater、AtomicStampedReference
AtomicInteger 原理分析
接下来,我们来剖析一下 AtomicInteger 的实现原理,仍然是基于我们刚刚在前面的案例中使用到的方法作为突破口。
getAndIncrement
getAndIncrement 实际上是调用 unsafe 这个类里面提供的方法,Unsafe 类我们前面在分析 AQS 的时候讲过,这个类相当于是一个后门,使得 Java 可以像 C 语言的指针一样直接操作内存空间。当然也会带来一些弊端,就是指针的问题。实际上这个类在很多方面都有使用,除了 J.U.C 这个包以外,还有 Netty、kafka 等等这个类提供了很多功能,包括多线程同步(monitorEnter)、CAS 操 作 (compareAndSwap) 、线程的挂起和恢复(park/unpark)、内存屏障(loadFence/storeFence)内存管理(内存分配、释放内存、获取内存地址等.)。
public final int getAndIncrement() {
return unsafe.getAndAddInt(this,
valueOffset, 1);
}
valueOffset,也比较熟了。通过 unsafe.objectFieldOffset()获取当前 Value 这个变量在内存中的偏移量,后续会基于这个偏移量从内存中得到value的值来和当前的值做比较,实现乐观锁。
private static final long valueOffset;
static {
try {
valueOffset = unsafe.objectFieldOffset(AtomicInteger.class.getDeclaredField("value"));
} catch (Exception ex) { throw new Error(ex); }
}
getAndAddInt
通过 do/while 循环,基于 CAS 乐观锁来做原子递增。实际上前面的 valueOffset 的作用就是从主内存中获得当前value 的值和预期值做一个比较,如果相等,对 value 做递增并结束循环:
public final int getAndAddInt(Object var1, long var2, int var4) {
int var5;
do {
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2,
var5, var5 + var4));
return var5;
}
get 方法
get 方法只需要直接返回 value 的值就行,这里的 value 是通过 Volatile 修饰的,用来保证可见性:
public final int get() {
return value;
}
其他方法
AtomicInteger 的实现非常简单,所以我们可以很快就分析完它的实现原理,当然除了刚刚分析的这两个方法之外,还有其他的一些比如它提供了 compareAndSet , 允许客户端基于AtomicInteger 来实现乐观锁的操作:
public final boolean compareAndSet(int expect, int update) {
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}