近几年大数据异常火热,往远了看去,毫不夸张得说未来10年依旧是大数据的天下,未来就是探索挖掘数据的应用场景,涉及金融,医疗,教育,交通,零售等等。
大数据目前分三个方向:
-
-
①、大数据开发方向
-
②、数据挖掘、数据分析&机器学习方向
-
③、大数据运维&云计算方向
-
那么你了解数据挖掘吗?
现在我有个问题,老板让我结合公司数据库的销售以及产品数据,分析销售下降的原因以及出一份解决方案。

我该怎么分析呢。我要怎么从这些数据提取出有效的信息呢,要从哪些方面入手呢。从数据采集到我们这份解决方案的出炉的过程就是数据挖掘的过程了。如果掌握了数据挖掘的知识,它一定能成为你大数据工作中的一把好手,对于我们的数据职业生涯也是一个颠覆式的精进。也相信大家都对数据挖掘比较感兴趣。那么让我们来开始。
下面我将详细介绍数据挖掘
那么什么是数据挖掘
是从海量数据中挖掘有趣模式和知识的过程即 KDD(Knowledge Discovery in Database) 知识发现
通俗点说就是从大量的,不完全的,有噪声,模糊的,随机的数据里,提取分析出潜在的信息和知识的过程。
从数据中挖掘知识,或者是知识挖掘,挖掘这个词是一个很生动的术语,抓住了从大量的,未加工的材料中发现少量宝贵金块这一过程的特点
为什么需要数据挖掘
我们现在的时代有人称它为“信息时代”,就说每天互联网产生的数据,就以 PB 记,换个其它说法,据统计,每天互联网产生的数据可以刻满 1.68 亿张DVD,在时下的大数据时代,数据增速只会越来越快,这么海量得数据,里面蕴含得‘黄金’是超乎想象得,可是怎么挖掘出这些‘黄金’呢,数据挖掘应运而生。
数据挖掘有什么数据源呢
数据源包括数据库,数据仓库,Web,其他信息存储库或动态地流入系统的数据
数据挖掘的流程
数据挖掘一般由以下的步骤组成的:
数据清理->数据集成->数据选择->数据变换->数据挖掘->模式评估->知识表示

数据挖掘的任务是什么呢
-
描述性
-
预测性
那我们可以挖掘什么类型的数据呢?
也就是了解数据的基本形式,一般我们挖掘的类型有
-
数据库数据;
-
事务数据:即事务数据库里的数据记录,每条记录代表一个事务,比如顾客的一次购物;
-
数据仓库:一个或多个数据源收集的信息存储库;提供一些数据分析能力,称作联机分析处理
-
其它类型数据:除了上面说的三种类型外,还有许多其它类型的数据,它们具有各式各样的形式和结构,比如数据流(视频监控),空间数据(地图),多媒体数据等等我们可以从这些数据类型里挖掘各种知识,比如时间数据,可以挖掘银行数据的变化趋势;
可以挖掘什么类型的模式
我们已经了解了有什么类型的数据,那我们可以挖掘什么数据模式呢
特征化与区分
数据可以与类或概念相关联,比如某个商店,销售的商品类包括饮料和啤酒,像‘商品类’这种类与概念的描述称作类/概念描述,这种描述我们可以用以下方法

-
①数据特征化(目标类数据的一般特征或特征的汇总)
-
②数据区分(将目标类与一个或多个可比较类进行比较)
-
③数据特征化和区分
挖掘频繁模式,关联和相关性
-
频繁模式:就是数据中频繁出现的模式,有多种类型,包括频繁项集(比如小卖部中被许多顾客频繁得一起购买得牛奶和面包),频繁子序列(如顾客倾向先购买电磁炉,再购买炒锅),频繁子结构
-
关联分析:比如你想知道哪些商品经常被一起购买,比如啤酒与尿布得故事,以后会详说。
用于预测分析得分类与回归
- 分类(离散的,无序的):
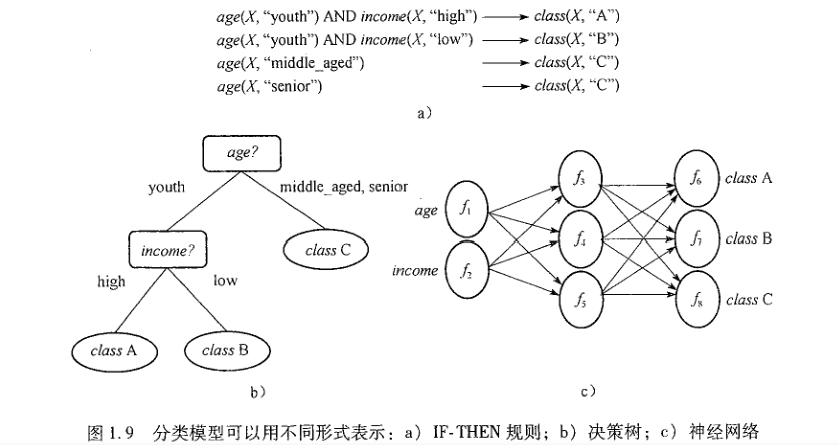
就是找出描述和区分数据类或概念得模型,以便能使用模型预测类标号未知得对象的类标号。模型如决策树,神经网络,朴素贝叶斯分类,支持向量机,K最近邻分类
-
回归(连续值):就是说回归是用来预测缺失的或难以获得的数值数据值,而不是离散的类标号
-
相关分析:用在分类和回归之前,试图识别回归过程显著相关的属性
比如你是个销售经理,想根据促销活动的三种反应,如商品的商品集合分类:好的反应,中等反应和没有反应,你想根据商品的描述特性,如价格,品牌,生产地和类别,对这三类的每一种导出模型,假如我们用的分类模型用决策树的形式表示,决策树可能吧价格看作最能区分三个类的因素。具体怎么用这些模型,怎么分析,以后我们再详讲。
-
聚类分析:分析数据对象,而不考虑类标号。不像分类和回归分析标记类的(训练)数据集
-
离群点分析:对离群点进行分析也叫异常挖掘。在一些应用中(欺诈检测),罕见的事件可能比正常出现的事件更令人感兴趣。
数据集里可能包含一些数据对象,它们与数据的一般行为或模型不一致,这些就是离群点,大部分数据挖掘方法都将离群点视为噪声或异常丢弃。
数据挖掘涉及的领域
作为一个应用驱动的领域,数据挖掘吸纳了诸如统计学、机器学习、模式识别、数据库和数据仓库,信息检索,可视化,算法,高性能计算和许多应用领域的大量技术。总之数据挖掘是一个比较考验综合能力的领域,所以它也是一个应用比较广泛的技术。值得我们好好探索学习。
相信「数据挖掘」一定能很好得贯彻“数据驱动业务”这个宗旨的。看后对数据挖掘体系有个基本的了解,这就够了。是我这篇小文的目的,后面会针对重点进行详细的描述。
今天的文章涉及的知识点我用思维导图整理出来的,可能比用文字描述更简单易懂。

本文首发微信公众号“哈尔的数据城堡”.
详细思维导图,可以关注公众号回复[数据挖掘一]获得~
PS:思维导图下载后需用xmind打开