Arules包详解
- 包基本信息
发布日期:2014-12-07
题目:挖掘关联规则和频繁项集
描述:提供了一个表达、处理、分析事务数据和模式(频繁项集合关联规则)的基本框架。
URL:http://R-Forge.R-project.org/projects/arules/,http://lyle.smu.edu/IDA/arules/
依赖包: Matrix包
建议学习包:pmml, XML, arulesViz, testthat
作者(牛牛们):Michael Hahsler [aut, cre, cph],Christian Buchta [aut, cph],Bettina Gruen [aut, cph],Kurt Hornik [aut, cph],Christian Borgelt [ctb, cph]
包维护人员:Michael Hahsler mhahsler@lyle.smu.edu
Arules包设计的方法一览表:
|
函数 |
函数 |
函数 |
类 |
数据集 |
|
|
addComplement Affinity aggregate Apriori Combine Coverage crossTable discretize dissimilarity duplicated eclat Groceries image Inspect |
interestMeasure is.closed is.maximal is.superset itemCoding itemFrequency itemFrequencyPlot itemSetOperations Length LIST match merge |
predict random.transactions read.PMML read.transactions ruleInduction Sample setOperations size sort subset support supportingTransactions unique write |
APappearance-class AScontrol-classes ASparameter-classes associations-class itemsets-class itemMatrix-class proximity-classes transactions-class rules-class tidLists-class |
Adult Epub AdultUCI Groceries Income IncomeESL |
|
-
函数介绍
-
addComplement:向事务数据中添加complement-items(其实就是额外添加补充项)
- 描述
-
该函数的功能就是向每一个条事务记录中添加人工构造的项(artificial item)(而这些项在原数据中并没有!)
- 用法
addComplement(x, labels, complementLabels=NULL)
### x:一个transaction类对象
### labels:字符串,项标签(针对创建的complements项标签)
### complementLabels:字符串,人工构造的补充项的标签. 如果被忽略, 会在原始标签之前加上"!"符号来形成补充项的标签!
- 返回值
返回一个添加了补充项的transaction类对象
- 例子
#####查看数据基本信息!
> data('Groceries')
> head(Groceries)
transactions in sparse format with
6 transactions (rows) and
169 items (columns)
> dim(Groceries)
[1] 9835 169
> class(Groceries)
[1] "transactions"
attr(,"package")
[1] "arules"
> typeof(Groceries) #可以看到Groceries事务数据是以S4类型存储的,格式如下
[1] "S4"
……………………此处省略无数……………………..
9833 {chicken,
citrus fruit,
other vegetables,
butter,
yogurt,
frozen dessert,
domestic eggs,
rolls/buns,
rum,
cling film/bags}
9834 {semi-finished bread,
bottled water,
soda,
bottled beer}
9835 {chicken, ###可以看到9833,9834等是一笔事务记录,即项集,里面存的是项
tropical fruit,
other vegetables,
vinegar,
shopping bags}
NULL
######(1)为"whole milk"和"other vegetables"添加补充项(complement-items)
@@@初始状态!
> inspect(head(Groceries,3))
items
1 {citrus fruit,
semi-finished bread,
margarine,
ready soups}
2 {tropical fruit,
yogurt,
coffee}
3 {whole milk}
> g2 <- addComplement(Groceries, c("whole milk", "other vegetables"))
@@@添加后的状态!
> inspect(head(g2,3))
items
1 {citrus fruit,
semi-finished bread,
margarine,
ready soups,
!whole milk, ## 可以看到补充项被添加到每一个事务记录中!
!other vegetables}
2 {tropical fruit,
yogurt,
coffee,
!whole milk,
!other vegetables}
3 {whole milk,
!other vegetables}
########(2)为补充项使用自定义标签!
> g2 <- addComplement(g2, "coffee", "NO coffee")
> inspect(head(g2,3))
items
1 {citrus fruit, ##第一个事务中没有"coffee"项,所有就添加了一个"No coffee"项
semi-finished bread,
margarine,
ready soups,
!whole milk,
!other vegetables,
NO coffee}
2 {tropical fruit, ##第二个事务中有"coffee"项,所以"NO coffee"项不被添加到这儿
yogurt,
coffee,
!whole milk,
!other vegetables}
3 {whole milk,
!other vegetables,
NO coffee}
- affinity:计算项与项之间的密切关系(affinity)
- 描述
提供了泛函affinity和S4方法来计算和返回事务集合中项与项之间的亲密关系相似矩阵!
- 用法
### x:一个矩阵、itemMatrix类对象、事务数据
- 细节说明
两个项i和j之间的亲密程度被(Aggarwal et al. (2002))定义为
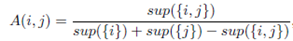
其中,sup(.)是支持度度量值,这意味着亲密度(affinity)是项与项之间的Jaccard similarity!
- 返回值
返回一个ar_similarity类对象,表示了x中项与项之间的亲密程度
- 例子
> data('Adult')
> s<-sample(x = Adult,size = 500)
> s
transactions in sparse format with
500 transactions (rows) and
115 items (columns)
> a <- affinity(s)
> summary(as.vector(a))
Min. 1st Qu. Median Mean 3rd Qu. Max.
0.00000 0.00000 0.00000 0.06478 0.01786 1.00000






…………………………………………………………..…此处省略无数………………………………………………………
从上面可以看出,affinity函数是计算了两两项之间的亲密度,并以矩阵的形式返回!
- aggregate:将项(items)聚合成项集(item groups)
- 描述
比如在一个超市数据中,"bread"和"beagle"项可能属于"baked goods"项组(类别). Aggregate方法使用用户指定的项组(item group)替换事务数据(transactions)中的项、项集、规则!
如果规则被聚合,会导致在lhs和rhs中的出现相同的项,此时, 这些相同的项从lhs中移除!聚合后不唯一的规则或项集也会被移除!
- 用法
## S4 method for signature 'itemMatrix'
aggregate(x, itemLabels)
## S4 method for signature 'itemsets'
aggregate(x, itemLabels)
## S4 method for signature 'rules'
aggregate(x, itemLabels)
#### x:一个事务表,项集或规则对象
####itemLables:和x中项长度相同的字符串向量。接收到相同项标签(item label)的项将会被聚合!
- 例子
> data(Groceries)
### Groceries包含了一个存储在itemInof中的层次结构(hierarchy)
>head(itemInfo(Groceries))

> level1 <- itemInfo(Groceries)[["level1"]]
> levels(level1) #查看level1中水平
[1] "canned food" "detergent" "drinks"
[4] "fresh products" "fruit and vegetables" "meet and sausage"
[7] "non-food" "perfumery" "processed food"
[10] "snacks and candies"
######(1)聚合事务数据
> aggregate(Groceries, level1)
transactions in sparse format with
9835 transactions (rows) and
10 items (columns)
> Groceries
transactions in sparse format with
9835 transactions (rows) and
169 items (columns)
> inspect(agg[1])
items
1 {fresh products,
fruit and vegetables,
processed food}
> inspect(Groceries[1])
items
1 {citrus fruit,
semi-finished bread,
margarine,
ready soups}
#######(2)聚合规则
> rules <- apriori(Groceries, parameter=list(supp=0.005, conf=0.5))
Parameter specification:
confidence minval smax arem aval originalSupport support minlen maxlen target ext
0.5 0.1 1 none FALSE TRUE 0.005 1 10 rules FALSE
Algorithmic control:
filter tree heap memopt load sort verbose
0.1 TRUE TRUE FALSE TRUE 2 TRUE
apriori - find association rules with the apriori algorithm
version 4.21 (2004.05.09) (c) 1996-2004 Christian Borgelt
set item appearances ...[0 item(s)] done [0.00s].
set transactions ...[169 item(s), 9835 transaction(s)] done [0.00s].
sorting and recoding items ... [120 item(s)] done [0.00s].
creating transaction tree ... done [0.00s].
checking subsets of size 1 2 3 4 done [0.00s].
writing ... [120 rule(s)] done [0.00s].
creating S4 object ... done [0.00s].
> rules
set of 120 rules
> aggregate(rules, level1)
set of 18 rules
> rules[1:3]
set of 3 rules
> inspect(rules[1:3])
lhs rhs support confidence lift
1 {baking powder} => {whole milk} 0.009252669 0.5229885 2.046793
2 {other vegetables,
oil} => {whole milk} 0.005083884 0.5102041 1.996760
3 {root vegetables,
onions} => {other vegetables} 0.005693950 0.6021505 3.112008
> inspect(aggregate(rules, level1)[1:3])
lhs rhs
1 {processed food} => {fresh products}
2 {fruit and vegetables,
processed food} => {fresh products}
3 {} => {fruit and vegetables}
@@@注:从这里可以看出,聚合时,使用大类把属于特定大类的小类给替换掉了,替换后有重复项的也一并删除,因此,得到的规则就会很多很多!
- APappearance-class:指定apriori算法参数的"appearance"
- 描述
对apriori算法挖掘的关联进行控制,注意:对于eclat算法,appearance参数是不支持的!
- 类对象
如果使用appearance控制(restrictions),一个appearance对象将会在apriori函数中被自动创建,使用的是appearance参数的命名列表(list)中的信息。这个列表可以包含如下元素:
lhs, rhs, both, items, none:字符串向量,用于指定可以出现在指定地点的项标签(lhs、rhs、both用于rules规则;itens用于itemsets项集)。特殊的地点 none指定不能出现在rule规则或itemset项集中的items项!
default:可以是both、lhs、rhs和none中的一个,默认项是both;为所有的项指定默认的appearance!
- 例子
data("Adult")
######(1)仅仅查找不包括small or large income的频繁项集
is <- apriori(Adult, parameter = list(support= 0.1, target="frequent"),
appearance = list(none = c("income=small", "income=large"),
default="both"))
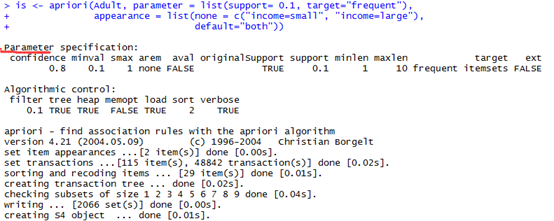
> items(is)
itemMatrix in sparse format with
2066 rows (elements/transactions) and
115 columns (items)
> itemFrequency(items(is))["income=small"]
income=small
0
> itemFrequency(items(is))["income=large"]
income=large
0
#####(2)查找只包含small or large income 和young age的项集
> is <- apriori(Adult, parameter = list(support= 0.1, target="frequent"),
+ appearance = list(items = c("income=small", "income=large", "age=Young"),
+ default="none"))
> inspect(head(is))
items support
1 {income=large} 0.1605381
2 {age=Young} 0.1971050
3 {income=small} 0.5061218
4 {age=Young,
income=small} 0.1289259
#####(3)在right-hand-side中查找只包含有small or large income的规则
rules <- apriori(Adult, parameter = list(support=0.2, confidence = 0.5),
appearance = list(rhs = c("income=small", "income=large"),
default="lhs"))
inspect(head(rules))

- apriori:使用apriori算法挖掘关联规则
-
用法
apriori(data, parameter = NULL, appearance = NULL, control = NULL)
#### data:事务数据类对象
-
AScontrol-classes:"AScontrol类,APcontrol类"指定apriori算法的"control"参数
-
描述
AScontrol类保存使用的挖掘算法的算法参数。APcontrol直接扩展了AScontrol类,添加了只适用于apriori算法的其他参数的插槽(slots),即可以接受更多的参数,并且这些参数只适用于apriori算法!(相当于个性改装!)
AScontrol中常用的插槽(slots):
sort:一个整数标量,默认值为2,表示针对项的频率,如何对项排序。
-
升序;-1—降序;0:—不排序;2—升序;-2:—关于事务量和来降序
verbose:逻辑值,表示是否报告输出进度(progress)
其他插槽:
Filter:数值型标量,表示如何过滤事务中未使用的项(unused items), 默认为0.1

Tree:逻辑值,表示是否将事务组织成一个前缀树(prefix tree),默认为TRUE
Heap:逻辑值,表示是否使用heapsort而不是quicksort来对事务排序,默认为TRUE
Memopt:逻辑值,表示是否最小化内存使用,而不是最大化速度,默认为FALSE
Load:逻辑值,表示是否加载事务到内存中,默认为TRUE
-
ASparameter-classes:指定apriori算法的"parameter"参数
-
插槽(slots)
ASparameter定义的常用插槽:
|
support:默认为0.1 |
数值型:一个项集的最小支持度 |
|
minLen:默认为1 |
整型:每一个项集的最小项数 |
|
maxlen:默认为10 |
整型:每一个项集的最大项数 |
|
target |
字符串:指定挖掘关联的类型 |
|
ext:默认为FALSE |
逻辑值:表示是否生成关于quality measures(比如:lhs.support)的额外信息 |
注:target可以是:"frequent itemsets";"maximally frequent itemsets"; "closed frequent itemsets"; "rules" (only available for Apriori); "hyperedgesets"
其他slots:
|
confidence:默认为0.8 |
数值型:规则或关联超边的最小置信度 |
|
smax:默认为1 |
数值型:项集/规则/超边的最大支持度 |
|
arem:默认为none |
字符串:表示使用额外的规则评估度量 |
|
aval |
逻辑值:表示是否arem选择返回其他规则评估度量 |
|
minval:默认为0.1 |
数值型:arem选择的其他评估度量的最小值 |
|
originalSupport:默认为TRUE |
逻辑值:表示是否对最小支持度使用一个规则(lhs和rhs)的原始支持度定义而不是支持度. |
注:对于arem插槽,可以有的其他度量:"none": no additional evaluation measure;"diff": absolute confidence difference;"quot": difference of confidence quotient to 1;"aimp": absolute difference of improvement to 1;"info": information difference to prior;"chi2": normalized  measure!
measure!
- Association-class:关联的一个集合
- 描述
Association类是一个虚拟类,用于表达挖掘结果(比如项集/规则的集合)。该类提供了对quality插槽的访问权,记忆对关联排序的一个方法!
- slots
quality:一个quality度量(相关度量如支持度或置信度)的数据框。每一个quality度量都是一个命令向量,其长度和关联集中的元素数量相同。
info:一个列表,用于存储特定算法的挖掘信息。一般来说,它至少包含了"data"元素(data是事务数据集的名称);"ntransactions"(数据集的长度);"support"(用于挖掘的最小支持度)!
拥有的方法有:info、items、labels、length、quality和show
- combine:合并对象,简写为c
- 描述
基于itemMatrix将几个对象合并成一个对象;注意:使用union而不是c将几个挖掘的itemsets或规则合并成一个集合。
- 用法
## S4 method for signature 'itemMatrix'
c(x, ..., recursive = FALSE)
## S4 method for signature 'transactions'
c(x, ..., recursive = FALSE)
## S4 method for signature 'rules'
c(x, ..., recursive = FALSE)
## S4 method for signature 'itemsets'
c(x, ..., recursive = FALSE)
###### x:第一个对象
###### ……和x同属一个类的其他对象
###### recursive:逻辑值,如果为TRUE,the function recursively descends through lists combining all their elements into a vector!
- 例子
data("Adult")
#####(1)合并事务数据
> a1 <- Adult[1:10]
> a2 <- Adult[101:110]
> Adult[1:10]
transactions in sparse format with
10 transactions (rows) and
115 items (columns)
> Adult[101:110]
transactions in sparse format with
10 transactions (rows) and
115 items (columns)
> aComb <- c(a1, a2)
> aComb
transactions in sparse format with
20 transactions (rows) and
115 items (columns)
> summary(aComb)
transactions as itemMatrix in sparse format with
20 rows (elements/itemsets/transactions) and
115 columns (items) and a density of 0.1121739

#######(2)合并规则(可以包含重复的规则多次)—combine
r1 <- apriori(Adult[1:1000])
r2 <- apriori(Adult[1001:2000])
> r1
set of 8500 rules
> r2
set of 8575 rules
> rComb <- c(r1, r2)
> rComb
set of 17075 rules
######(3)连接规则(只有唯一规则的一个集合:和unique(rComb)等价)---union
> rUnion <- union(r1,r2)
> rUnion
set of 9928 rules
-
Coverage:计算规则的覆盖率(calculate coverage for rules)
-
描述
计算规则的覆盖率(lhs的支持度)
-
用法
coverage(x, transactions = NULL, reuse = TRUE)
#### x:规则集合
### transactions:用于生成"x"的数据集,当"x"的quality插槽不包含支持度和置信度时才需要指定该参数
### reuse:重新使用存储在"x"中的支持度和置信度,或者重新从transactions中计算
-
细节
Coverage is calculated from the rules quality measures (support and confidence) stored in the quality slot
-
返回值
A numeric vector of the same length as x containing the coverage values for the sets in x.
-
例子
## find and some rules (we only use 5 rules here) and calculate coverage
> data('Income')
> rules <- apriori(Income)[1:5]
> quality(rules) <- cbind(quality(rules), coverage = coverage(rules))
> inspect(rules)
