1.关于count(1),count(*),和count(列名)的区别
相信大家总是在工作中,或者是学习中对于count()的到底怎么用更快。一直有很大的疑问,有的人说count(*)更快,也有的人说count(列名)更快,那到底是谁更快,我将会在本文中详细介绍一下到底是count(1),count(*)和count(列明)的区别,和更适合的使用场景。
往常在工作中有人会说count(1)比count(*)会快,或者相反,首先这个结论肯定是错的,实际上count(1)和count(*)并没有区别。
接下来,我们来对比一下count(*)和count(列)到底谁更快一些
首先我们执行以下sql,来看一下执行效率(下面sql针对的是ORACLE数据库,大致逻辑为先删除t别,然后在根据dba_objects创建t表,在更新t表根据rownum)
1 drop table t purge; 2 create table t as select * from dba_objects; 3 --alter table T modify object_id null; 4 update t set object_id =rownum ; 5 set timing on 6 set linesize 1000 7 set autotrace on --开启跟踪 8 9 select count(*) from t; 10 / 11 select count(object_id) from t; 12 /
然后咱们分别看一下“select count(*) from t”和“select count(object_id) from t”语句的执行计划。(执行计划是指sql的一个执行顺序和耗费的资源,耗费的资源越少越快,如果在plsql中,使用F8可以查看sql的执行计划)
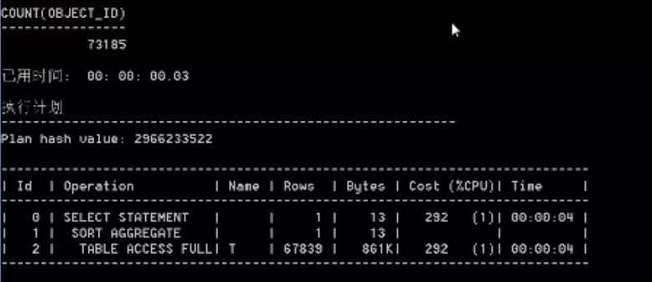
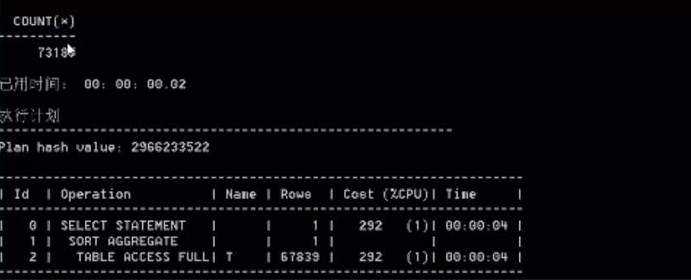
通过我们执行sql的实验来说,count(*)和count(列)消耗的资源是一样的,说面他们是一样快的,但是真的是这样么。那么咱们接着以下的实验。
这次咱们给object_id这一列加一个索引试一下。我们执行一下索引sql
1 create index idx_object_id on t(object_id); 2 select count(*) from t; 3 / 4 5 6 select count(object_id) from t; 7 /
然后我们在分别看一下两条sql的执行计划
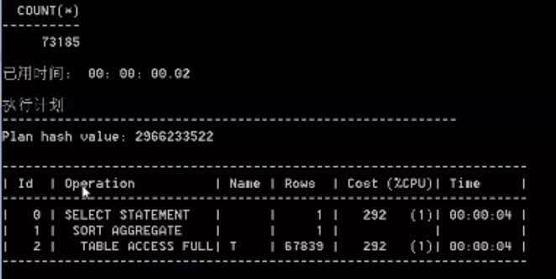
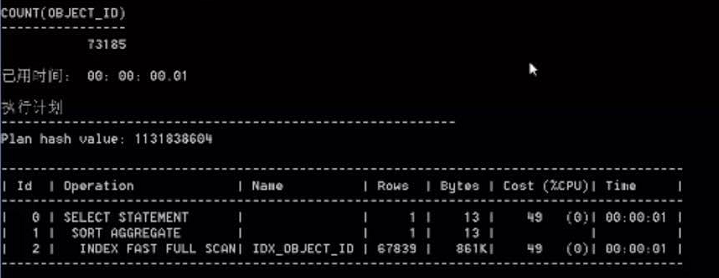
通过我们建完索引后。突然发现count(列)变快了好多,但是count(*)还是和以前一样的。这说明了count(列)可以用到索引,而count(*)不行,但是真的这样么,咱们在往下看。
接下来我们给object_id这个字段加上不可为空条件。我们执行以下sql
1 create index idx_object_id on t(object_id); 2 select count(*) from t; 3 / 4 5 6 select count(object_id) from t; 7 /
接下来我们在来看一下count(*)的执行计划

现在count(*)和count(列)一样快了,由此我们得出了这个结论:count(列)和count(*)其实一样快,如果索引列是非空的,count(*)可用到索引,此时一样快。
总结:但是真的结论是这样的么。其实不然。其实在数据库中count(*)和count(列)根本就是不等价的,count(*)是针对于全表的,而count(列)是针对于某一列的,如果此列值为空的话,count(列)是不会统计这一行的。所以两者根本没有可比性,性能比较首先要考虑写法等价,这两个语句根本就不等价。也就失去了去比较的意义!!!
2.关于表中字段顺序的问题
首先我们建一张有25个字段的表并加入数据在进行count(*)和count(列)比较。由于建表语句和插入语句和上面雷同。就不贴出代码了。
然后我们分别执行count(*)和count每一列的操作来看一下到底谁更快一些,由于执行计划太多,就不一一贴图了。我整理了一个excel来给大家看一下执行的结果
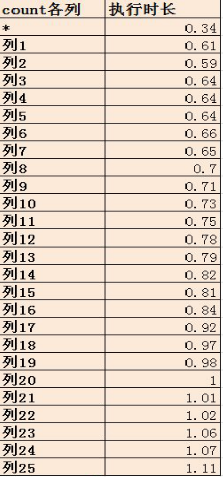
经过实验我们看出,count(列)越往后。我们的执行效率越慢。所以,我们得出以下结论:
1.列的偏移量决定性能,列越靠后,访问的开销越大。
2.由于count(*)的算法与列偏移量无关,所以count(*)最快。
总结:所以我们在开发设计中。越常用的列,要放在靠前的位置。而cout(*)和count(列)是两个不等价的用法,所以无法比较哪个性能更好,在实际的sql优化场景中要根据当时的业务场景再去考虑是使用count(*)还是count(列)(其中的区别上文有提到)。