一、NumPy
1、简介:
官网链接:http://www.numpy.org/
NumPy是Python语言的一个扩充程序库。支持高级大量的维度数组与矩阵运算,此外也针对数组运算提供大量的数学函数库
2、基本功能:
- 快速高效的多维数组对象ndarray
- 用于对数组执行元素级计算以及直接对数组执行数学运算的函数
- 用于读写硬盘上基于数组的数据集的工具
- 线性代数运算、傅里叶变换,以及随机数生成
- 用于将C、C++、Fortran代码集成到Python的工具
- 除了为Python提供快速的数组处理能力,NumPy在数据分析方面还有另外一
- 个主要作用,即作为在算法之间传递数据的容器。
3、NumPy的ndarray 创建ndarray
* 数组创建函数

demo:
import numpy print('使用普通一维数组生成NumPy一维数组') data = [6, 7.5, 8, 0, 1] arr = numpy.array(data) print(arr) print(arr.dtype) print('使用普通二维数组生成NumPy二维数组') data = [[1, 2, 3, 4], [5, 6, 7, 8]] arr = numpy.array(data) print(arr) print('打印数组维度') print(arr.shape) print('使用zeros/empty') print(numpy.zeros(10)) # 生成包含10个0的一维数组 print(numpy.zeros((3, 6))) # 生成3*6的二维数组 print(numpy.empty((2, 3, 2))) # 生成2*3*2的三维数组,所有元素未初始化。 print print('使用arrange生成连续元素') print(numpy.arange(15)) # [0, 1, 2, ..., 14]
输出:


使用普通一维数组生成NumPy一维数组 [6. 7.5 8. 0. 1. ] float64 使用普通二维数组生成NumPy二维数组 [[1 2 3 4] [5 6 7 8]] 打印数组维度 (2, 4) 使用zeros/empty [0. 0. 0. 0. 0. 0. 0. 0. 0. 0.] [[0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0.] [0. 0. 0. 0. 0. 0.]] [[[8.82769181e+025 7.36662981e+228] [7.54894003e+252 2.95479883e+137] [1.42800637e+248 2.64686750e+180]] [[1.09936856e+248 6.99481925e+228] [7.54894003e+252 7.67109635e+170] [2.64686750e+180 5.63234836e-322]]] 使用arrange生成连续元素 [ 0 1 2 3 4 5 6 7 8 9 10 11 12 13 14]
4、NumPy的ndarray NumPy数据类型


demo:
import numpy as np print('生成数组时指定数据类型') arr = np.array([1, 2, 3], dtype = np.float64) # 生成ndarray数组,数据类型:float64 print(arr.dtype) arr = np.array([1, 2, 3], dtype = np.int32) print(arr.dtype) print ('使用astype复制数组并转换数据类型') int_arr = np.array([1, 2, 3, 4, 5]) float_arr = int_arr.astype(np.float) print (int_arr.dtype) print (float_arr.dtype) print ('使用astype将float转换为int时小数部分被舍弃') float_arr = np.array([3.7, -1.2, -2.6, 0.5, 12.9, 10.1]) int_arr = float_arr.astype(dtype = np.int) print (int_arr) print ('使用astype把字符串转换为数组,如果失败抛出异常。') str_arr = np.array(['1.25', '-9.6', '42'], dtype = np.string_) float_arr = str_arr.astype(dtype = np.float) print (float_arr) print ('astype使用其它数组的数据类型作为参数') int_arr = np.arange(10) float_arr = np.array([.23, 0.270, .357, 0.44, 0.5], dtype = np.float64) print (int_arr.astype(float_arr.dtype)) print (int_arr[0], int_arr[1] ) # astype做了复制,数组本身不变。
输出:
生成数组时指定数据类型 float64 int32 使用astype复制数组并转换数据类型 int32 float64 使用astype将float转换为int时小数部分被舍弃 [ 3 -1 -2 0 12 10] 使用astype把字符串转换为数组,如果失败抛出异常。 [ 1.25 -9.6 42. ] astype使用其它数组的数据类型作为参数 [0. 1. 2. 3. 4. 5. 6. 7. 8. 9.] 0 1
* numpy dtype类型字符码
# 类型字符码 ,用简写表示 np.bool_: ? np.int8: b np.uint8: B np.int8/16/32/64: i1/2/4/8 np.uint8/16/32/64: u1/2/4/8 np.float/16/32/64: f2/4/8 np.complex64/128: c8/16 np.str_: U<字符数> np.datetime64: M8 字节序前缀,用于多字节整数和字符串: </>/[=]分别表示小端/大端/硬件字节序。 demo: <字节序前缀><维度><类型><字节数或字符数> >3i4:大端字节序,3个元素的一维数组,每个元素都是整型,每个整型元素占4个字节,即int32。 <(2,3)u8:小端字节序,6个元素2行3列的二维数组,每个元素都是无符号整型,每个无符号整型元素占8个字节,uint64。 >U7: 包含7个字符的Unicode字符串,每个字符占4个字节,采用大端字节序。
* numpy 组合与拆分
组合与拆分 垂直: np.vstack((上, 下))->组合数组 np.concatenate((上, 下), axis=0) / 二维:0-行,垂直,1-列,水平 axis表示轴向 < 三维:0-页,深度,1-行,垂直,2-列,水平 np.vsplit(数组, 份数)->上, ..., 下 np.split(数组, 份数, axis=0) 水平 np.hstack((左, 右))->组合数组 np.concatenate((左, 右), axis=1) np.hsplit(数组, 份数)->左, ..., 右 np.split(数组, 份数, axis=1) 深度 np.dstack((前, 后))->组合数组 np.dsplit(数组, 份数)->前, ..., 后 行列(可以用一维数组做参数) np.row_stack((上, 下))->组合数组 np.column_stack((左, 右))->组合数组
# -*- coding: utf-8 -*- from __future__ import unicode_literals import numpy as np a = np.arange(11, 20).reshape(3, 3) print(a) /* [[11 12 13] [14 15 16] [17 18 19]] */ b = a + 10 print(b) /* [[21 22 23] [24 25 26] [27 28 29]] */ c = np.vstack((a, b)) print(c) /* [[11 12 13] [14 15 16] [17 18 19] [21 22 23] [24 25 26] [27 28 29]] */ d = np.concatenate((a, b), axis=0) print(d) /* [[11 12 13] [14 15 16] [17 18 19] [21 22 23] [24 25 26] [27 28 29]] */ e, f = np.vsplit(c, 2) print(e, f, sep=' ') /* e: [[11 12 13] [14 15 16] [17 18 19]] f: [[21 22 23] [24 25 26] [27 28 29]] */ g, h = np.split(d, 2, axis=0) print(g, h, sep=' ') /* g: [[11 12 13] [14 15 16] [17 18 19]] h: [[21 22 23] [24 25 26] [27 28 29]] */ i = np.hstack((a, b)) print(i) /* [[11 12 13 21 22 23] [14 15 16 24 25 26] [17 18 19 27 28 29]] */ j = np.concatenate((a, b), axis=1) print(j) /* [[11 12 13 21 22 23] [14 15 16 24 25 26] [17 18 19 27 28 29]] */ k, l = np.hsplit(i, 2) print(k, l, sep=' ') /* k: [[11 12 13] [14 15 16] [17 18 19]] l: [[21 22 23] [24 25 26] [27 28 29]] */ m, n = np.split(i, 2, axis=1) print(m, n, sep=' ') /* m: [[11 12 13] [14 15 16] [17 18 19]] n: [[21 22 23] [24 25 26] [27 28 29]] */ o = np.dstack((a, b)) print(o) /* [[[11 21] [12 22] [13 23]] [[14 24] [15 25] [16 26]] [[17 27] [18 28] [19 29]]] */ p, q = np.dsplit(o, 2) print(p.T[0].T, q.T[0].T, sep=' ') /* p.T[0].T: [[11 12 13] [14 15 16] [17 18 19]] q.T[0].T: [[21 22 23] [24 25 26] [27 28 29]] */ a, b = a.ravel(), b.ravel() print(a, b) /* a: [11 12 13 14 15 16 17 18 19] b: [21 22 23 24 25 26 27 28 29] */ // r = np.vstack((a, b)) r = np.row_stack((a, b)) print(r) /* [[11 12 13 14 15 16 17 18 19] [21 22 23 24 25 26 27 28 29]] */ // s = np.hstack((a, b)) s = np.column_stack((a, b)) print(s) /* [[11 21] [12 22] [13 23] [14 24] [15 25] [16 26] [17 27] [18 28] [19 29]] */
* ndarray类的属性
shape: 维度 dtype: 元素类型 size: 元素总数量 ndim: 维数,len(shape) itemsize: 元素的字节数 = 元素类型 / 8 nbytes: 总字节数 = size * itemsize real: 复数数组的实部数组 imag: 复数数组的虚部数组 T: 数组对象的转置视图 flat: 扁平迭代器 # 可用于python 数据遍历 数组对象.tolist()->列表 # 将数组转为列表 , a.tolist() ,a 为array类型
demo:
import numpy as np a = np.array([[1 + 1j, 2 + 4j, 3 + 7j], [4 + 2j, 5 + 5j, 6 + 8j], [7 + 3j, 8 + 6j, 9 + 9j]]) print(a.shape) # (3, 3) print(a.dtype) # complex128 复数128类型 print(a.size) # 9 个元素 print(a.ndim) # 2 个维度、二维 print(a.itemsize) # 16, 一个元素16个字节(complex128 / 8位 = 16字节) print(a.nbytes) # 144, 总字节数144(总元素个数size * 单个元素字节itemsize) print(a.real, a.imag, sep=' ') # 自行测试 print(a.T) print([elem for elem in a.flat]) # 扁平迭代器 遍历 b = a.tolist() # 转换成 list 类型 print(b)
5、NumPy的ndarray 数组和标量之间的运算
- 不用编写循环即可对数据执行批量运算
- 大小相等的数组之间的任何算术运算都会将运算应用到元素级
- 数组与标量的算术运算也会将那个标量值传播到各个元素
demo:
import numpy as np # 数组乘法/减法,对应元素相乘/相减。 arr = np.array([[1.0, 2.0, 3.0], [4., 5., 6.]]) print (arr * arr) # 不需要做循环,相当于对应元素进行平方处理 print (arr - arr) # 标量操作作用在数组的每个元素上 arr = np.array([[1.0, 2.0, 3.0], [4., 5., 6.]]) print (1 / arr) print (arr ** 0.5) # 开根号
输出:
[[ 1. 4. 9.] [16. 25. 36.]] [[0. 0. 0.] [0. 0. 0.]] [[1. 0.5 0.33333333] [0.25 0.2 0.16666667]] [[1. 1.41421356 1.73205081] [2. 2.23606798 2.44948974]]
python数据分析与展示
一、Ipython使用
1、符号:?
在变量前面或后面加上‘?’可以获取相关的描述信息
2、%魔法命令
%run 系统文件 # 执行某一个文件 # ipython的模式命令 : %magic # 显示所有的魔术命令 %hist # 命令历史输入信息 %pdb # 异常发生后自动进入调试器 %reset # 删除当前命名空间中的全部变量或名称 %who # 显示Ipython 当前命名空间中的已经定义的变量 %time statemnent # 给出代码执行时间 %timeit statement # 多次实行代码,计算平均执行时间
二、numpy
1、numpy入门
import numpy as np







2、ndarray的创建

常用方法一:

demo:

常用方法二:

demo:




demo:


3、ndarray数组的维度变化

demo:
a是3维数组,元素个数24个,使用reshape()、resize(),不改变数组元素,但可以改变shape形状

使用.flatten(),将多维数组降为一维数组,原数组是不变的

** .astype:可以变换数组的类型,比如将int类型转为float类型:

** tolist:将ndarray数组转换成列表:

4、ndarray数组的操作

1)一维数组:

2)多维数组
索引:
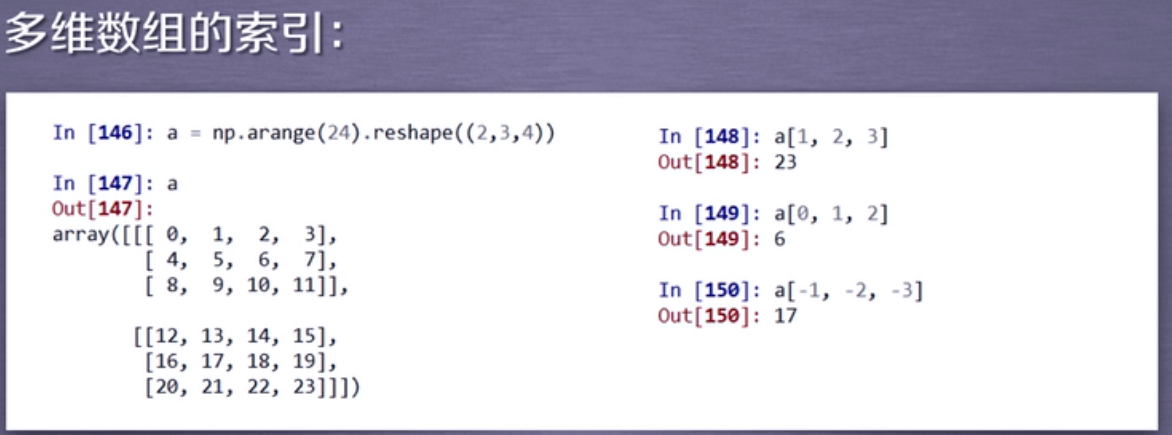
切片:
a[1,2,3] :1→第一维度 ,2→第二维度 ,3→第三维度
如下图a数组,第一维度为2,第二维度为3,第三维度为4 。
a[:,1:3,:] :表示第一维度、第三维度选择全部,不管 ; 第二维度只选择1:3,第二维度为2,在1中的1:3 → [4,5,6,7],[8,9,10,11] ;在2中的1:3 → [16,17,18,19],[20,21,22,23] ,因此结果为:
[[[4,5,6,7],[8,9,10,11]],[[16,17,18,19],[20,21,22,23]],]
, 
5、ndarray数组的运算
1)一元函数:对一个数组进行的运算
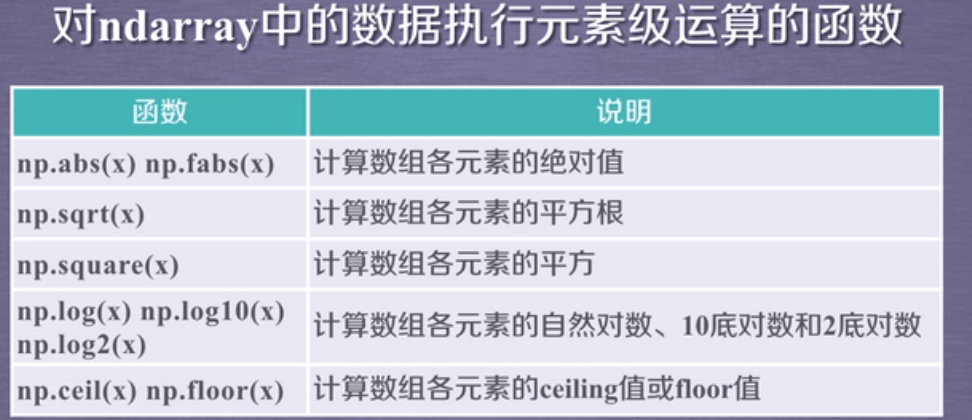

demo:

2)二元函数:两个数组之间的运算

demo:

6、numpy数据的存取与函数
1)CSV文件存取
①、np.savetxt 函数:保存ndarray数组到CSV文件中

demo:

输出:

②、np.loadtxt 函数:将CSV文件中的数据读取出来

demo:

注意:CSV文件的局限性

③、多维数组的存取
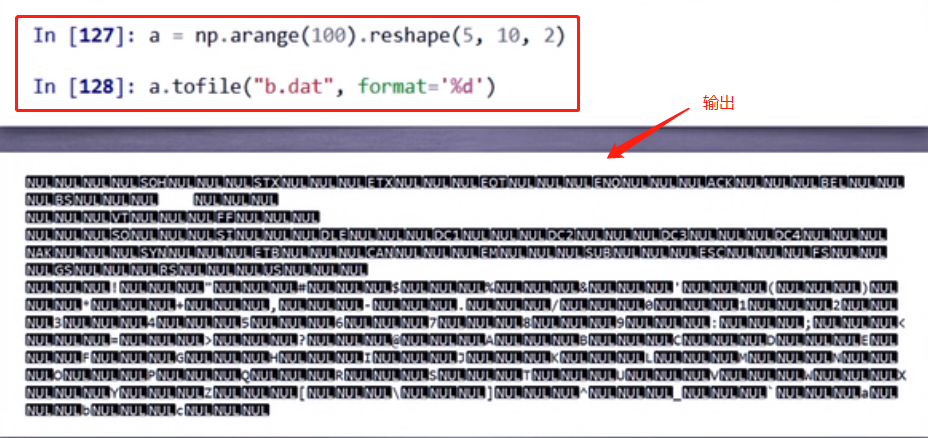
a.tofile 函数:a是ndarray数组,将a数组存入文件中

demo:

输出:

如果不指定sep参数,那么写入文件是以二进制的方式写入的,如下:
np.fromfile 函数:从指定文件中读取数据

demo:


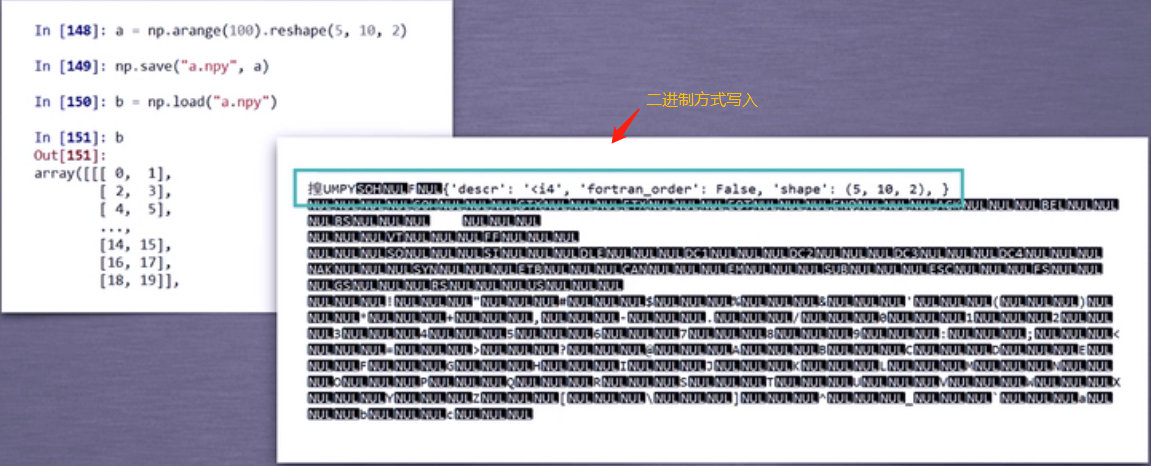
2)、numpy的便捷文件存取函数:.npy文件
在①-③中的文件存取方式,生成的文件内容都是以文本的方式进行存储,获取时只是读出文本形式,需要我们通过reshape等方法将数据还原成数组类型。而现在讲的这种文件存取函数,是可以将存储进去的数据,获取时直接按原数组类型取出
这两个函数存取的文件扩展名默认为.npy,如果不习惯这种文件存取,建议使用上面的文件存取方式

demo:
3)numpy的随机函数:random子库


demo:



demo:
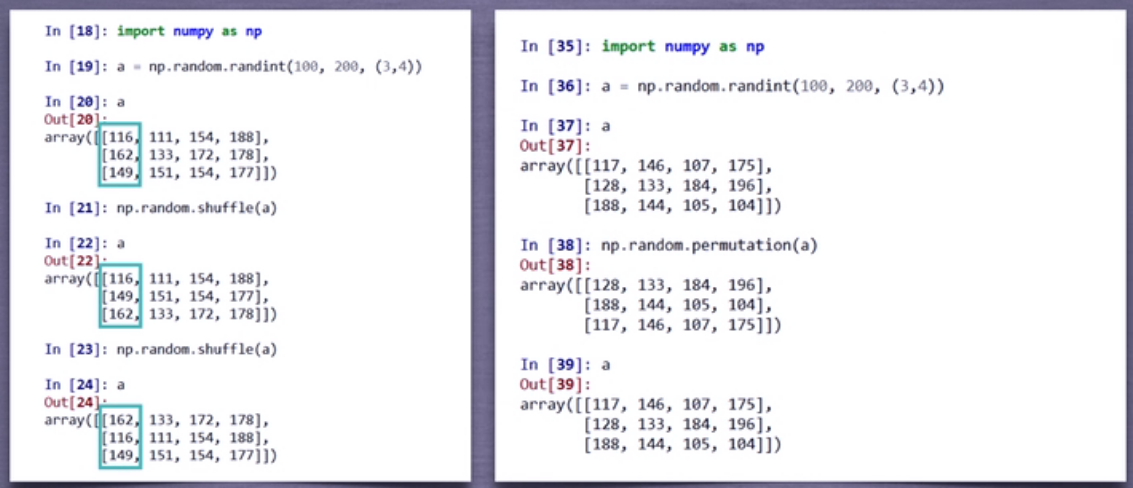
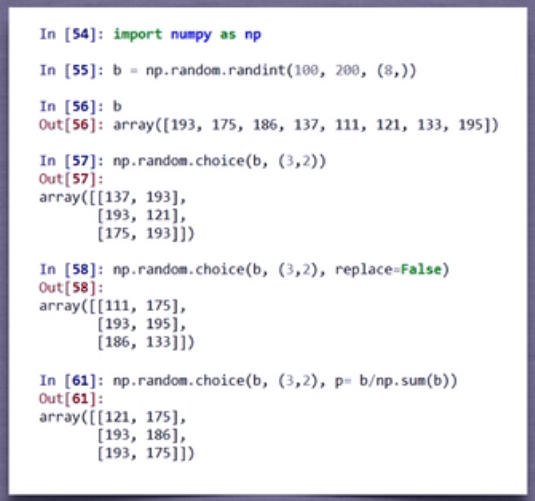

demo:

7、numpy的统计函数

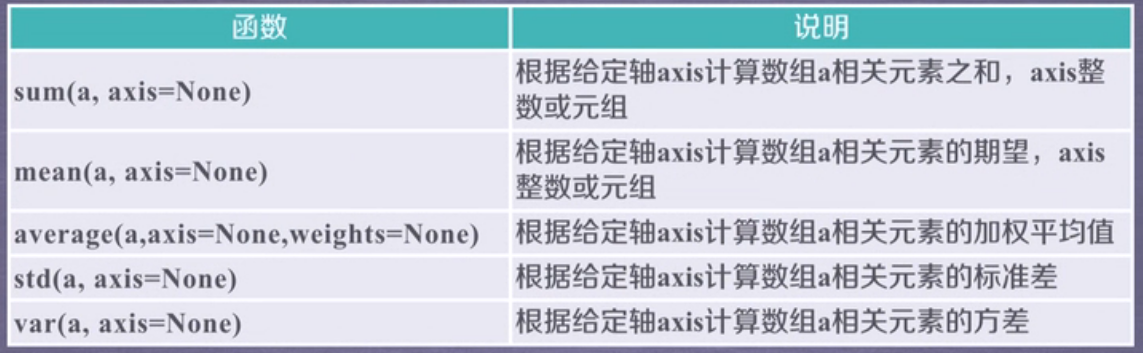
demo:

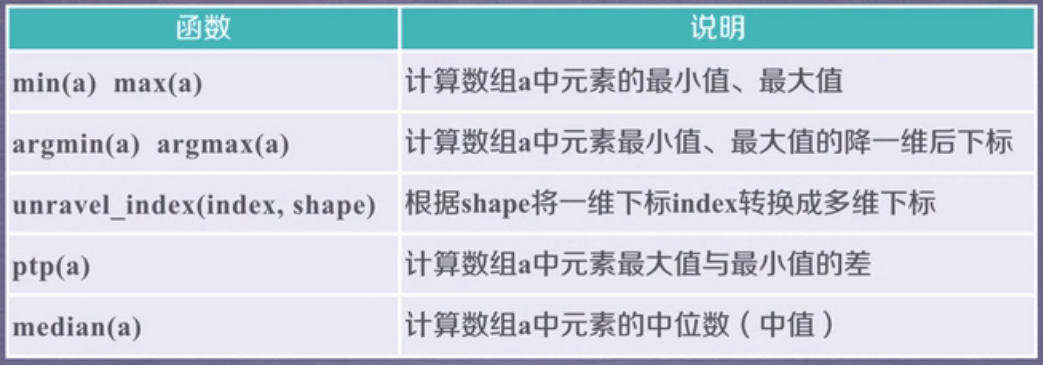
demo:

8、numpy的梯度函数

demo:


小结:


实例
图片:
通过numpy的ndarray数组打开,发现图片其实也是一个三维数组组成:宽、高、像素:
from PIL import Image import numpy as np im = np.array(Image.open(r'C:UsersAdministratorDesktop666.jpg')) print(im.shape,im.dtype) # 打印结果: # runfile('C:/Users/Administrator/.spyder-py3/temp.py', wdir='C:/Users/Administrator/.spyder-py3') (200, 200, 3) uint8 # 宽、高、像素值(RGB)
图像的变换:


# 图像的变换 # -*- coding: utf-8 -*- from PIL import Image import numpy as np a = np.array(Image.open(r'C:UsersAdministratorDesktop666.jpg')) # 打开图片,并存为ndarray数组类型 # print(im) #print(im.shape,im.dtype) b = [255,255,255]-a # 将该数组每个像素取补数 im = Image.fromarray(b.astype('uint8')) # 复制b数组的形状,并将元素数据类型转换成uint8类型 im.save(r'C:UsersAdministratorDesktop777.jpg')
结果:
