在上一篇的发文中,提到批量下载邮件正文内容,但仅能以纯文本文件形式存放内容,对部分场景可能是够用的,只需关键字匹配,但毕竟文本文件除去格式后结构化水平太弱,灵机一动,其实还是可以追加另存为html网页格式的,然后使用网页采集功能,重新将有用的网页元素内容采集到位。
功能补充及改进
在下载正文时,增加了html文本可供选择,下文同样介绍下如何从html文件中提取指定内容。

现在提取到的正文是html格式了。
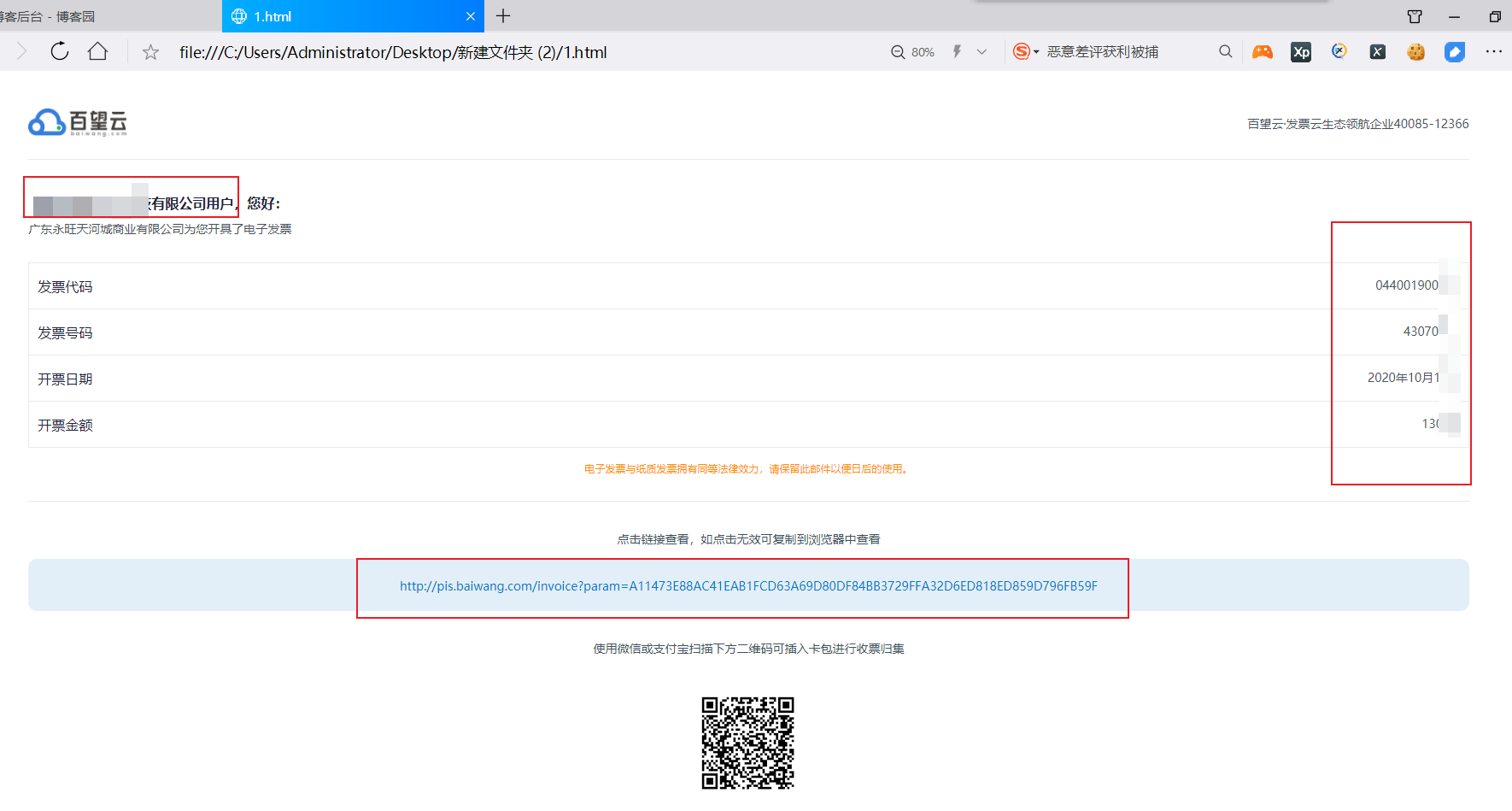
当使用html文件时,如果同一类型的正文,就可以比较方便用网页采集的技术将其采集到位,较比纯文本内容有较大优势。甚至还可以采集跳转链接、图片链接等。
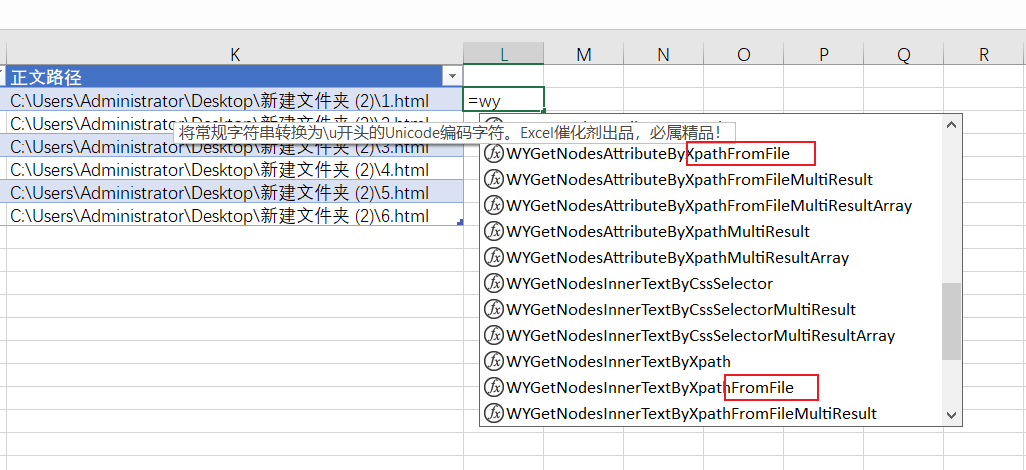
为了让大家懒到底,正文路径也帮大家构建好了。

如何提取网页指定内容
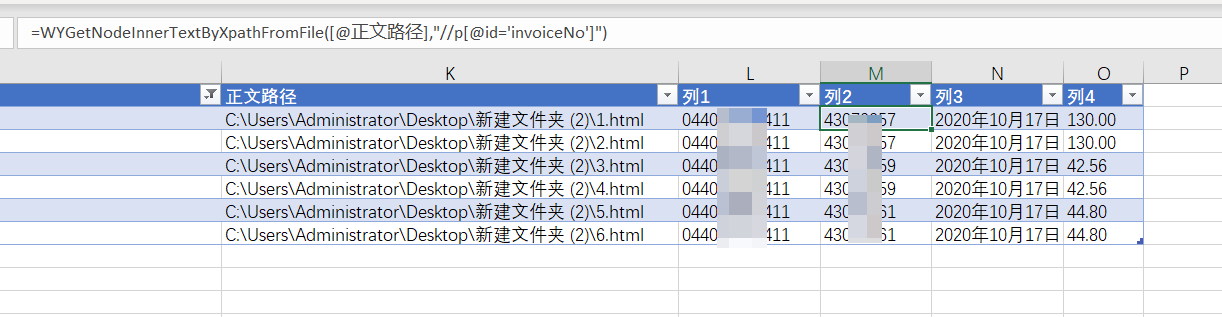
有了内容,就差如何将其送达到Excel单元格中结构化存储。
如果有追踪过Excel催化剂过往的功能,就可知道,除了上篇提及的从文本文件中使用正则自定义函数来提取指定内容外,对于网页格式的如html、xml、json格式的文件,也已经有一套专门针对它的自定义函数,相对正则提取业说,更容易及更准确操作。
网页采集自定义函数,以WY开头,有对json和xml的结构化文件的解释操作(html是广义上的xml文件)。
笔者已经在网页采集的视频教程里给大家送上了全套的网页采集教程,使用Excel催化剂轻松采集90%合理性需求。例如以下的网页xpath元素定位技术。
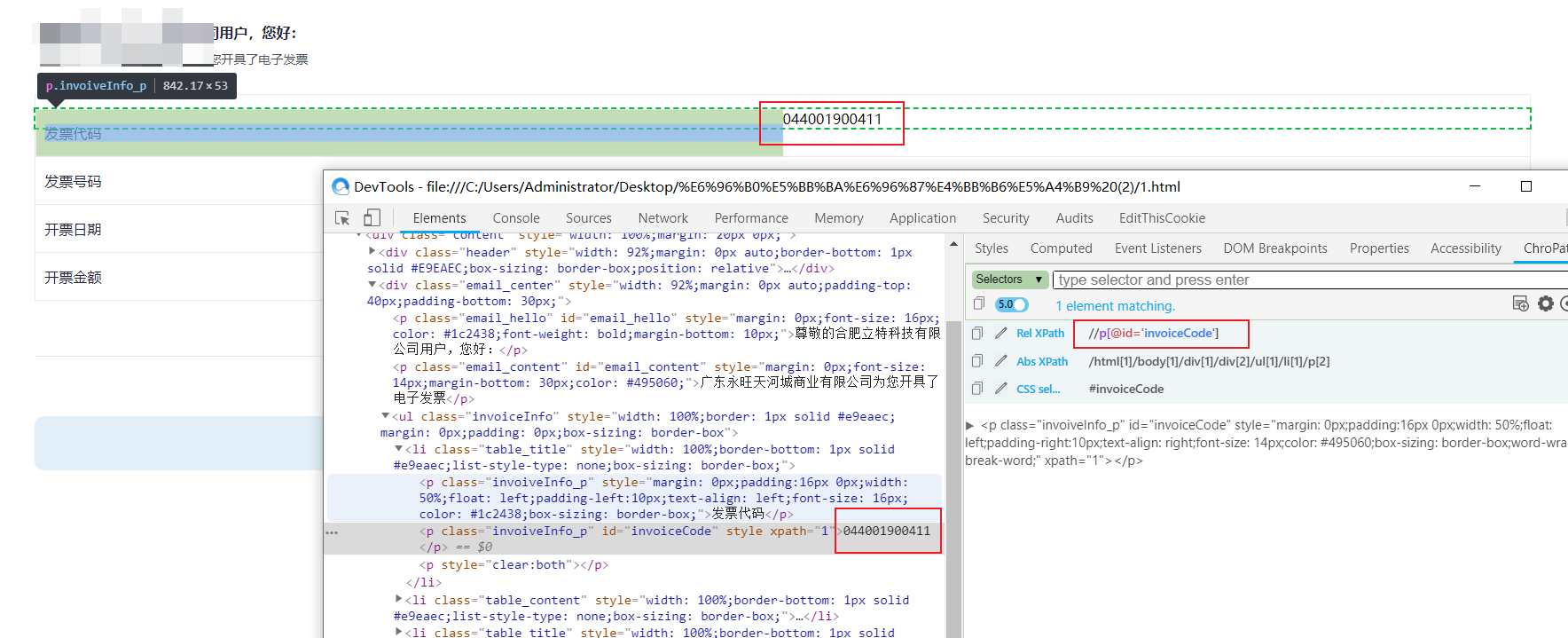
以下轻松从网页正文中将重要信息提取到位。更多网页采集知识学习,不容错过的Excel催化剂视频+工具,让你快速学以致用。
结语
Excel催化剂,给大家一个五星级的用户体验,欢迎大家多多使用,多多反馈,本篇功能近期给大家录制视频教程,一口气给大家完美解决所有邮件相关的批量性场景使用。
如果觉得受用,多多支持,不妨购买个视频教程,学习更快,快速应用到工作场合中产出效益。