今天有同事告诉我,有个SQL执行了好久好久执行不出来,我说好就是多久?她说一天左右了。真是令人咋舌的SQL。于是我要来了SQL看了看执行计划,确实让人咋舌。
下图中就是执行计划的截图:
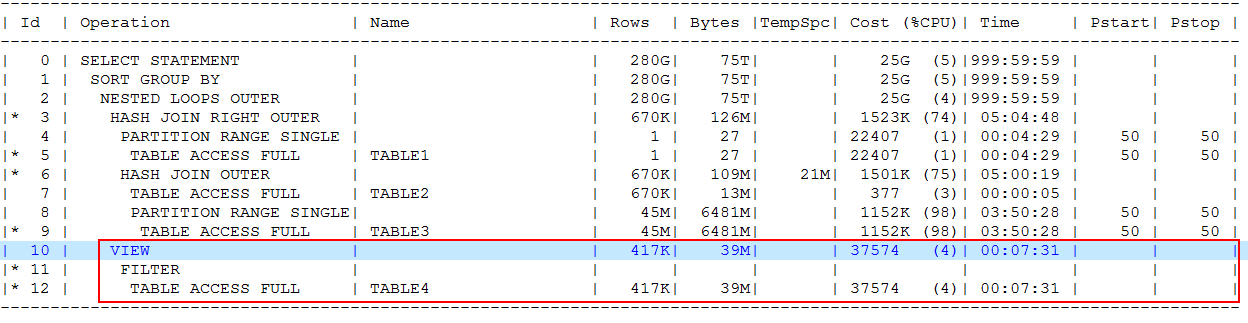
25G的COST和75T的Bytes确实是无法承受之重。这个SQL是这样子的:
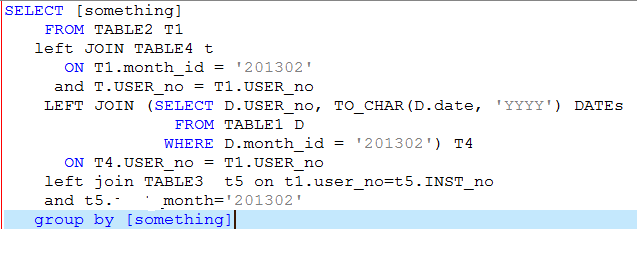
select部分做了很多sum运算,还有distinct等运算,总之很麻烦,group by部分就是上面的维度。其中最大的表是TABLE3和TABLE4,这两个表所需要查询的数据量都在3G以上,各自差不多3000万数据。
最开始我以为是因为数据量大的原因导致的这个执行计划不可实现,但是在我将TABLE3和TABLE4的相应数据进行压缩后,数据量尽管各自降低到了1G左右,但是执行计划基本上没有改变,这不是我要的效果,于是我注意到了执行计划中红色框中的部分。是不是这里导致了问题的发生?于是我开始检视SQL,就发现了一个问题:TABLE4实际上只有201302的数据,但是为什么这里还需要在左连接的时候写上月份标识,这个比较不合理,而且根据我以往的经验判断,左连接或者右连接的时候,如果and条件写的太多,往往会影响执行计划,导致SQL长久的无法得到结果。于是我做了一个很简单的事情,就是把TABLE4的month_id部分去掉,后来我又进了一步,将TABLE3的month部分也去掉了,这是一个分区表,于是我用了这个办法:
left join TABLE3 partition(part_02),这样即实现了减少and条件的目的,又不会影响数据准确的效果,一举两得。在进行了相关的优化之后,执行计划变成了这个样子:
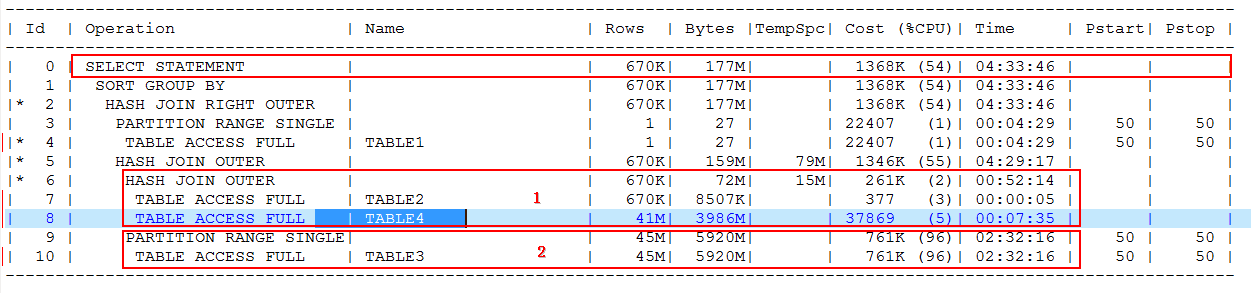
可以看到执行计划发生了翻天覆地的变化,直接能看到的就是少了NESTED LOOPS OUTER,取而代之的是图中1部分和2部分的HASH JOIN OUTER和TABLE1的HASH JOIN OUTER,这是我喜欢看到的事情,我就喜欢看到简单的执行计划。虽然这个COST依旧很大,但是我实在不想动弹了,这个的数据量实在是太巨大了,我面对的优化工作难度已经无法让我有精力想过去那样,仔细研究思考,然后把COST弄到几千或者更小的程度了,就这样吧,天要下雨,娘要嫁人,随他去吧。
我以前看到论坛上或者书上都在写,如果你的表超过1G,那么最好进行分区,这句话现在我深有体会,如果没有分区表,这个SQL也没有办法优化了(或者说我就没有能力去优化了),因为没有办法去掉month的条件,除非是将特定月份的数据取出来建立一个中间表,不过那么做似乎有点麻烦了,不符合我一贯喜欢写短代码的习惯。