对于SQL Server,我是个拿来主义。很多底层的原理并不了解,就直接模仿拿着来用了,到了报错的时候,才去找原因进而逐步深入底层。我想,是每一次的报错,逼着我一点点进步的吧。
近期由于项目的原因,我需要写一些存储过程。同时学校还开了一门《数据库系统》的课程。两者结合满足了我浓厚的兴趣。
下面写写我对存储过程的简单认识。
首先声明:初学者最好看一些参考书,有些规范什么的,我并没有遵守,中间可能有一些不好的习惯,或者一些不太注重的细节,比如变量的命名等,请提出指正。
一、基础知识:
1.select,insert,update,delete 的语法 ,这是核心中的核心
2.一点点的T-SQL编程基础:了解基本的过程流,如if...else,wihle ,for ;变量的赋值,变量类型,简单函数等等
可能大家对sq语句最熟悉,那从sql首先经过T-SQL编程,再进化到存储过程。
存储过程的优点:

二、实例:(可观察存储过程与其他编程语言异同,然后看下面的基本语法,着重看两者的不同之处)
--建立测试数据库
CREATE DATABASE Test
go
--建立测试表
USE Test
CREATE TABLE t2 ([Item_Code] [varchar](500) NULL,[Item_FileName] [varchar](500) NULL);
--带输入参数和控制流程语句的存储过程 CREATE PROCEDURE [dbo].[ProcT] (@code_name varchar(50)) AS BEGIN insert into t2 ([Item_Code],[Item_FileName]) values('1','测试1'),('2','测试2'),('3','测试3'),('4','测试4'); if @code_name='1' begin select '请重新输入' as warning; end else begin select [Item_Code] ,[Item_FileName] from t2 where Item_Code like '%'+@code_name+'%'; end END --执行存储过程 exec [ProcT] @code_name='1'
结果:
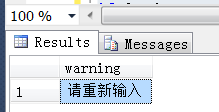
--执行存储过程 exec [TansProc] @code_name='2'
结果:
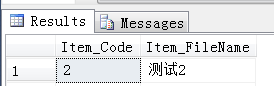
--删除存储过程 drop PROCEDURE TansProc
三、我理解的基本语法:
首先,我对存储过程的理解就是把sql 语句封装起来,存起来,等到需要的的时候只要执行存错过程的名称就好了。
最简单的一个例子,就是
use CrawlData --表明在哪个数据库里面创建存储过程 go create proc dbo.ProcTest --其中proc为 procedure的缩写,SQL Sever中,一些长的命令如execute 可简写前面的4个字母为exec; --dbo为架构名; --ProcTest为存储过程的名称,一般以Proc命名较容易识别这创建的对象为存储过程,不要以sp_为前缀,因为sp_一般为系统函数 as --as 为关键字 print '我是好人'; --一个输出 go
第二部分:常识(其实越简单的越容易被忽略,这些常识我之前几乎没有重视过,但是他们真的很重要):
1.go为批处理分隔符关键字,必须为这一行的唯一关键字
除此之外,他还可以用来多次提交批处理,例如:这个可输出5次'It is funny'
PRINT 'It is funny' go 5
2.语句终止用“;”,虽然有时不用也不影响结果,最好还是养成习惯用
3.关键字不区分大小写,例如EXEC 和 exec是一个作用
4.参数直接在存储过程名后面声明,前面均有@,后指明参数的类型如int,char,varchar等等
5.begin,end常常用在一个过程流的开始和结束,否则该判断将失效。例如 if @t=1 begin select @t end ,如果不加,则select @t将会被顺序执行,判断“ if @t=1”失效
6.use database_name,在执行存储过程或sql语句事,要么适用use 来定位到相应的数据库,要么在图形化界面中先选好。
我一般事先选好,所以use命令较少用。当需跨数据库查询时,可在查询的表格前加上数据库名,例如 insert into databaseB.[dbo].tableB (b) select a from databaseA.[dbo].tableA
第三部分:基本命令(经常用到的):
1.set命令,主要用于从表达式中赋值,例如 declare @T VARCHAR(10) set @T='5',这是与其它编程语言的不同之处。
2.select命令,它神通广大,作用非常多。其一,可以从数据源中检索数据赋值,例如 select @T=Item_Code from t2 where Item_FileName='测试2' ;其二可以输出变量的值,例如 select @T;
两者的相同之处是都可以把表达式的值复制给变量,当select从数据源的赋值时,若其后无WHERE条件子句的限制,一次查出了多条语句,此时,会将查询到的最后一条语句中相应的值赋值给变量。
3.alter,drop对存储过程也同样适用,例如修改存储过程,则alter ProcTest as select @T。而删除存储过程,则drop proc ProcTest
第四部分:数据传递
1.输入参数
有两种方式在存储过程执行期间传递参数值:命名参数和位置参数。例如exec ProcT @code_name='2'为命名参数传递;而exec ProcT '2'为位置参数传递,位置参数无须指定变量名,按照声明参数时的参数位置来传递。
当声明的变量较多时,一般命名参数较好。声明参数较少时,用位置参数即可。
调用存储过程时,必须给输入参数赋值,除非参数有默认值。
2.提供列表和表作为存储过程的输入参数
(1) 动态的构造T-SQL,先声明一个nvarchar类型的变量存一个sql语句,然后用函数sp_executesql执行。例如:


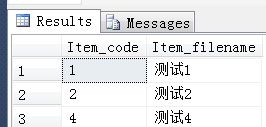
use Test; go create proc dbo.ProcSearch @code varchar(10) as Declare @SQLString nvarchar(1000) set @SQLString=N'SELECT Item_code,Item_filename from t2 where Item_code in ('+@code+');' exec sp_executesql @SQLString go exec ProcSearch @code='1,2,4'
结果:
(2)以XML格式传递列表,使用sp_xml_preparedocument准备XML文档,然后用OPENXML函数将XML文档的内容插入内部变量。这部分需要先了解下XSD,即xml的框架定义语言。这里只是稍微提及,以后用到这部分的时候再详细研究。
(3)提供表作为输入参数
将表值参数作为输入参数传入存储过程,必须首先将表值参数定义为用户定义的表类型。
在创建储存过程期间将用户定义的表类型指定为输入参数后,必须将表类型定位为READONLY
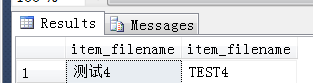
--第一步 :创建用户定义的表类型 create type t2Type1 as table (item_code varchar(500),item_filename varchar (500)) ; --第二步:定义存储过程,使用第一步的类型作为输入参数的数据类型 alter proc ProcT3 (@CodeTable [dbo].t2Type1 readonly) as select a.item_filename,b.item_filename from t2 as a join @CodeTable as b on a.item_code=b.item_code --第三步:执行该存储过程 --需要先声明一个表值参数,然后填充该参数的值 declare @Ctable as t2Type1 insert into @Ctable (item_code,item_filename) values('4','TEST4'); --执行 EXEC ProcT3 @CodeTable=@Ctable
结果:
3.从存储过程中返回数据
返回单个结果:
create proc ProT4 @countALL INT OUTPUT --输出参数声明时加 output关键字 AS SELECT @countALL=COUNT(*) FROM t2 declare @AC int ;--声明接收输出参数的局部变量 exec ProT4 @countALL=@AC OUTPUT --执行时也需加 output关键字 SELECT @AC --输出参数值
返回结果集:(有两种方式,第一种最简单的就是直接返回查询的表;第二种是用WITH RESULT SETS来重新定义输出列名和数据类型,此特性只在2012版或以上的版本支持)
create proc ProT5 as SELECT [Item_Code],item_filename FROM t2 EXEC ProT5 with RESULT sets (([Code] varchar(10),filename varchar(10))) --见结果ProT5-1
EXEC ProT5 --见结果ProT5-2
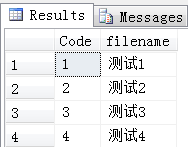
结果ProT5-1
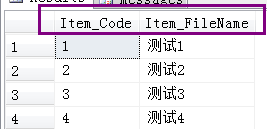
结果ProT5-2
除此之外还可用INSERT...EXECUTER与永久表,表变量,或临时表结合使用
例如 insert t2 exec ProT5 ,相当于把t2的数据翻倍,当然举的这个例子,不是很恰当,但是在其他时候,我们就可以模仿此种思路来转移表
四、概念辨析:
五、c#调用存储过程
参考资料:
1.存储过程详解:https://msdn.microsoft.com/zh-CN/library/ms345415(v=sql.120).aspx
2.张慧娟(译).SQL Server 2012 宝典(第四版).清华大学出版社.2014.5:第295-343页,第IV部分:使用T-SQL编程
3. 表值参数问题:https://msdn.microsoft.com/zh-cn/library/bb675163.aspx