此文的目的:
1、重点理解Hbase的整体工作机制
2、熟悉编程api,能够用来写程序
1. 什么是HBASE
1.1. 概念特性
HBASE是一个数据库----可以提供数据的实时随机读写
HBASE与mysql、oralce、db2、sqlserver等关系型数据库不同,它是一个NoSQL数据库(非关系型数据库)
* Hbase的表模型与关系型数据库的表模型不同:
* Hbase的表没有固定的字段定义;
* Hbase的表中每行存储的都是一些key-value对
* Hbase的表中有列族的划分,用户可以指定将哪些kv插入哪个列族
* Hbase的表在物理存储上,是按照列族来分割的,不同列族的数据一定存储在不同的文件中
* Hbase的表中的每一行都固定有一个行键,而且每一行的行键在表中不能重复
* Hbase中的数据,包含行键,包含key,包含value,都是byte[ ]类型,hbase不负责为用户维护数据类型
* HBASE对事务的支持很差
HBASE相比于其他nosql数据库(mongodb、redis、cassendra、hazelcast)的特点:
Hbase的表数据存储在HDFS文件系统中
从而,hbase具备如下特性:存储容量可以线性扩展; 数据存储的安全性可靠性极高!
1.1.1、各种数据库之间的差别比较

Hbase,Hive区别:
对Hive数据仓库的理解:
1、仓库就是存放历史数据存的地方,反复对历史数据进行读操作,统计分析操作,历史数据不需要修改。
2、Hive严格意义上来讲不能算是数据库;
Hive与Hbase巨大的区别在于,Hive底层依赖的文件系统HDFS中的数据是用户提交的,没有固定的格式,可以理解成按照分隔符分割的简单文本,而不是精心设计的文件(如Mysql那样精心设计的文件加上mysql中共的软件系统,可以对数据进行随机的访问和修改操作),Hive只能对这些数据进行读取,分析,不能对修改和跟新数据。
3、mysql也当然具备做为数据仓库的功能和能力,但是数据量太大是,mysql不适合,mysql适于联机事务处理(在线实时交互)。
Hbase
1、同msyql一样,底层的文件系统的精心设计的,Hbase的底层文件系统也是HDFS。
2、具有联机事务处理数据库的特性(快速 实时操作数据库,增删改查)。
3、Hbase本身的特性:
-
-
-
-
文件系统:HDFS(表可以很大很大)
- 分布式系统
- nosql表结构。
-
-
-
1.2 Hbase快速理解
两个基本问题:
1、怎么存数据
2、怎么查数据
1.2.1 、Hbase特性与表结构

(以上是Hbase的逻辑结构)
列族:KV分为若干的大类:,如上表所示。
1、每个列族中的kv数据可以随意存放,key可以不同,没有严格要求,完全有用户决定,当然一般使用情况下,数据是规整的;
如:下表是可以的,但是为了数据的规整,一般不建议随意为key起名字,最好保持一致。
| rowkey | base_info |
| 001 | name:jj, age:12, sex:mal |
| 002 | nick:ls, age:15, xb:male |
2、同一个列祖中的kv的个数也是灵活的,可以省略某些kv
cell:同一个数据可以保存多个值
1、一个kv就是一个cell
2、一个key可有有多个版本的值
3、时间戳作为版本
1.2.2、Hbase整体工作机制示意图
如下图:
1.2.2.1、存储问题(分散存储)
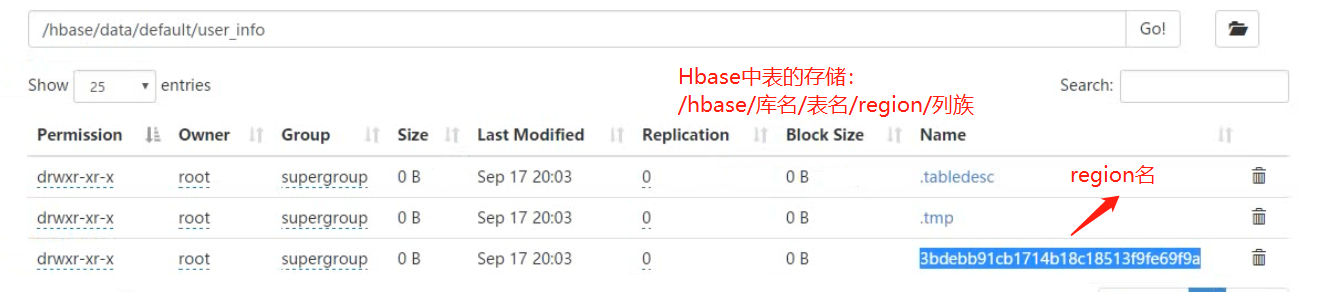
按照region划分范围存储(region目录还细分为列族目录,列族目录下才存放具体的文件)
1.2.2.2、查询问题(分布式:分任务查询)
Hbase底层文件系统是HDFS,Hbase中的表最终也会落地HDFS,那么Hbase的一张表可以很大很大,表中的数据不断的增加增加存储也是可以的,但是怎么查询呢?
当请求特别多的时候,一台Hbase服务器(region server)是不行的,Hbase是一个分布式的系统,当有多个Hbase提供服务的时候,某一次客户端的请求具体由那个服务器来处理呢?
当某一台服务器挂了,谁来接替他的工作,如何接替?
解决:服务器需要分任务(分布式系统里肯定是要分任务的)
一台服务器,负责Hbase中某个表的某一个部分。
如何界定部分?
需要划分范围:按照行健范围
这样通过分任务之后就是一个分布式系统。不同的regionServer可以并行的去访问hdfs中的数据(表数据),这样还有一个问题,若某一张表中的所有数据都存在同一个HDFS中的文件中,即使是负责同一张表的不同范围regionserver,大量的并行请求也会同时访问同一个hdfs文件,这会造成性能上的瓶颈,所以表中的数据在HDFS中是按照region划分范围存储(region目录还细分为列族目录,列族目录下才存放具体的文件)的这样同一个表的不同region范围的数据落地HDFS中不同的文件中。否则会造成即是分了任务一个dataNode被频繁的访问。
1.2.2.2.1、客户端读写数据是的路由流程:客户端找数据的流程
问题描述:客户端怎么知道他要访问的某个region在那一台regionserver上呢?
master是不会保存哪些region在哪些regionserver上的,否则就是有状态的节点了,一旦master挂了,regionserver立刻无法提供服务,而事实不是这样。
上述信息就是所谓的索引信息,master是不会保存索引信息的,索引信息是保存在系统索引表中的。
1、索引表当然也存在于hdfs中,且只有一个region;
2、谁来负责查询索引表
下图所示,索引表数据的查询由hdp-02机器上的regionserver负责,那么客户端怎样知道meta数据由hdp-02负责

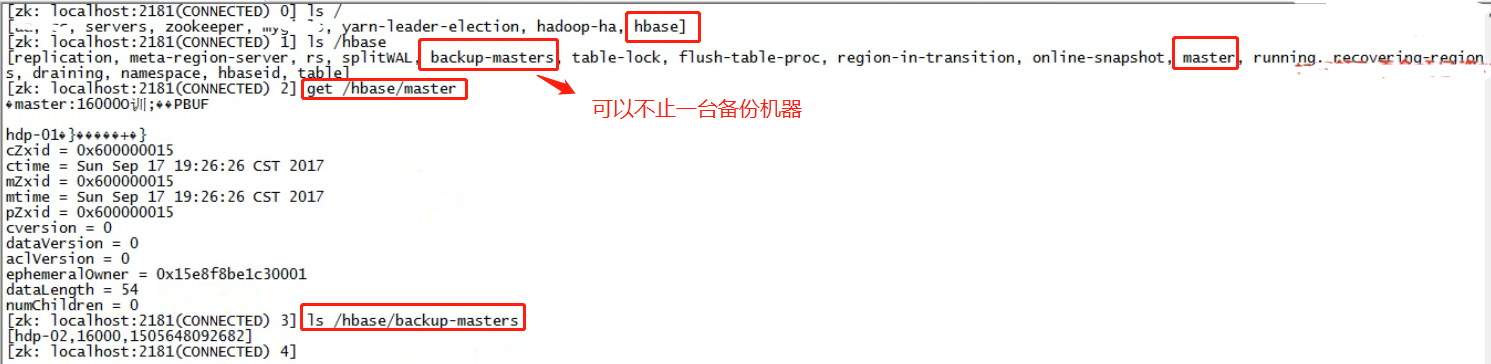
zookeeper上会记录元数据索引表,有哪一台regionserver负责管理。 客户单端,每次访问数据之前,先查询zookeeper。

下图为Zookeeper节点meta-region-server的信息

访问流程:
1、客户端去Zookeeper上查询,负责索引表数据的regionserver;
2、找该台regionserver服务器,查询出客户端要访问的region数据由哪一台regionserver负责;
3、客户端找具体的regionserver要数据;
总结:
1、Hbase表中的数据是存放在hdfs中的。
2、regionserver只负责逻辑功能,对数据进行增删改查,不存储它负责的region的数据。
3、一个regionserver可以负责多个表的多个region。
4、region是regionServer管理数据的基本单元。
1、客户端查找数据不经过master
2、客观端查找数据一定经过Zookeeper
Hbase整体工作机制示意图

Hbase集群中有两个角色
region server
master
region server负责数据的逻辑处理(增删改查),region server对数据的操作是不经过master。某一个瞬间master挂了,regionserver还是可以正常服务的,但是一定时间之后,万一某一个regionserver挂了,该regionserver负责的任务得不到重新分配,就会出问题。
1.2.2.3、服务器宕机问题(借助Zookeeper实现HA)
master对regionserver的监管,状态协调
1、所有的状态信息记录在Zookeeper里。
2、master负责监管region server的状态,知道每一个regionserver负责哪些表的哪些region,不负责帮用户查数据,一旦发现某个region server发生故障,会找另外的一台机器来接替该region server负责的region区域。
3、master通过Zookeeper来获取regionserver的状态。
4、master通过Zookeeper监听region server,maste是没有状态的节点,master存在单点故障的风险;通过主备容灾实现HA机制。
master HA
状态信息记录在Zookeeper里。master是无状态节点,standby 切换为 active状态,查看Zookeeper后,立马知道现在的集群是什么样子。
1.2.3、Hbase工作机制补充—regionserver数据管理
首先在hbase的表中插入一些数据,然后来观察一下hdfs中存的数据,发现hdfs下并没有数据,但是scan明明可以查到数据的,这是怎么回事呢?

scan可以查到数据。而上图hdfs中却没有数据文件。
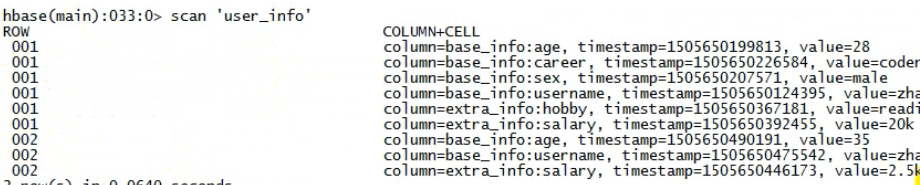
其实:此时此刻的数据位于内存中。

1.2.3.1、内存缓存热数据
每个region在内存中都对应分配一块缓存空间,memstore,但是memstore毕竟有限,不会将全部的数据都存入到内存中,还是有很大的数据是存在hdfs中的。当数据量很小的时候没有必要写入到hdfs文件中,这就解释了为什么上述hdfs中没有文件数据。
上述用户插入的数据都保存在了内存中,这样速度会比存入hdfs中快很多,但是又不能吧全部数据都存入到内存中,内存中只会保存一些热数据【刚刚被访问过的,刚刚被插入的数据】。
如果有人找regionserver查数据是,regionserver内存中没有该数据,就会去hdfs中查找,找到之后作为热数据,然后缓存在内存中,超过一段时间没有人访问就不是热数据了,就不会继续保存在内存中。
2、数据保存在内存中就有风险,万一没有来的落地hdfs,宕机了,内存中的数据会丢失,怎么办?
解决方案,regionserver一方面在自己内存中写数据,一方面在hdfs中写日志,一旦宕机后,master找来替换机器后,该机器会读取日志信息,还原内存中的数据。
hdfs中查看相应的痕迹


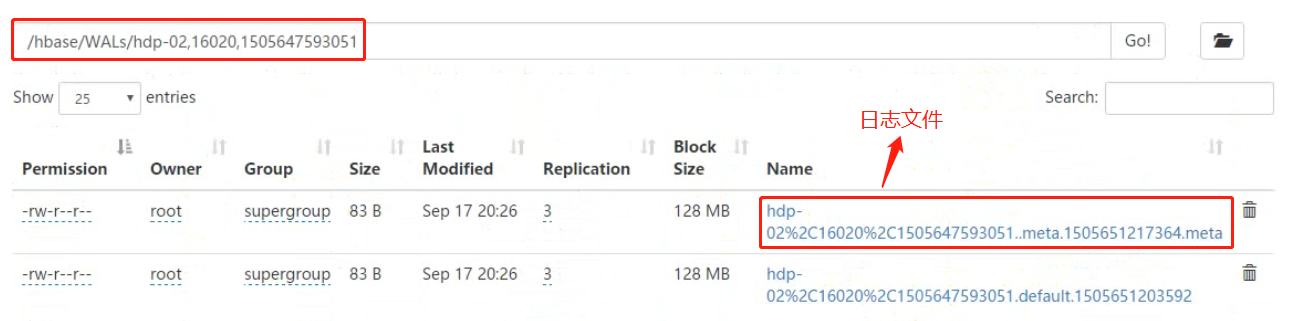
总结:
1、热数据存储
2、日志记录
1.2.3.2、持久化到hdfs
1、当内存中的数据插满时候,数据会持久化到hdfs中
2、当hbase退出时候,数据也会持久化到hdfs中

列族目录下已经有数据文件。

使用hadoop 命令查看具体数据

1.3、Hbase表模型
hbase的表模型跟mysql之类的关系型数据库的表模型差别巨大
hbase的表模型中有:行的概念;但没有字段的概念
行中存的都是key-value对,每行中的key-value对中的key可以是各种各样,每行中的key-value对的数量也可以是各种各样
1.3.1、Hbase表模型的要点
1、一个表,有表名
2、一个表可以分为多个列族(不同列族的数据会存储在不同文件中)
3、表中的每一行有一个“行键rowkey”,而且行键在表中不能重复
4、表中的每一对kv数据称作一个cell
5、hbase可以对数据存储多个历史版本(历史版本数量可配置)
6、整张表由于数据量过大,会被横向切分成若干个region(用rowkey范围标识),不同region的数据也存储在不同文件中
7、hbase会对插入的数据按顺序存储:
要点一:首先会按行键排序
要点二:同一行里面的kv会按列族排序,再按k排序


1.3.2、Hbase的表能存什么数据类型
hbase中只支持byte[]
此处的byte[] 包括了: rowkey,key,value,列族名,表名
1.3.3、hbase表的物理结构

3、安装Hbase
HBASE是一个分布式系统
其中有一个管理角色: HMaster(一般2台,一台active,一台backup)
其他的数据节点角色: HRegionServer(很多台,看数据容量),最好部署在datanode节点上。
3.1、 安装准备:
首先,要有一个HDFS集群,并正常运行; regionserver应该跟hdfs中的datanode在一起
其次,还需要一个zookeeper集群,并正常运行
然后,安装HBASE
角色分配如下:
Hdp01: namenode datanode regionserver hmaster zookeeper
Hdp02: datanode regionserver zookeeper
Hdp03: datanode regionserver zookeeper
不需要yarn集群,不需要跑mapreduce等运算框架的程序,但是mapreduce可以读取操作Hbase中的数据。
3.2、安装步骤
3.2.1、安装Zookeeper
略
3.2.2、安装Hbase
解压hbase安装包,conf目录下的配置文件如下:

3.2.2.1、hbase-env.sh
1、java_Home
2、拒使用自己的zookeeper
修改conf目录下的hbase-env.sh
export JAVA_HOME=/root/apps/jdk1.7.0_67 export HBASE_MANAGES_ZK=false
Hbase自带一套Zookeeper,这里选择关闭再带的Zookeeper,用我们自己提供的zookeeper。

3.2.2.2、hbase-site.xml
1、HDFS
2、指定Hbase为分布式模式,默认是单机模式
3、Zookeeper地址
<configuration> <!-- 指定hbase在HDFS上存储的路径 --> <property> <name>hbase.rootdir</name>
<!-- 会在hdfs根目录/下建立一个文件夹,用来放hbase中的数据【Hbase基于HDFS】-->
<value>hdfs://hdp01:9000/hbase</value> </property> <!-- 指定hbase是分布式的 --> <property> <name>hbase.cluster.distributed</name> <value>true</value> </property> <!-- 指定zk的地址,多个用“,”分割 --> <property> <name>hbase.zookeeper.quorum</name> <value>hdp01:2181,hdp02:2181,hdp03:2181</value> </property> </configuration>
3.2.2.3、regionservers
告知Hbase启动脚本,在哪些机器上启动,regionservers
hdp01
hdp02
hdp03
确保hdfs没有问题

3.3、启动hbase集群
确保Zookeeper正常,确保hdfs正常。
3.3.1、批量启动
使用自动批量启动脚本
bin/start-hbase.sh
改命令会在本机起送master,
启动完后,还可以在集群中找任意一台机器启动一个备用的master
bin/hbase-daemon.sh start master
新启的这个master会处于backup状态
3.3.2、逐个启动
人肉,逐个机器,启动进程。
bin/hbase-daemon.sh start master
bin/hbase-daemon.sh start regionserever
同步服务器时间

写入硬件时钟,否则重启无效。
3.3.3、查看hdfs文件
启动Hbase后会在hbase-site.xml中配置的HDFS路径下,建立对应的文件夹。
hbase文件夹内容如下
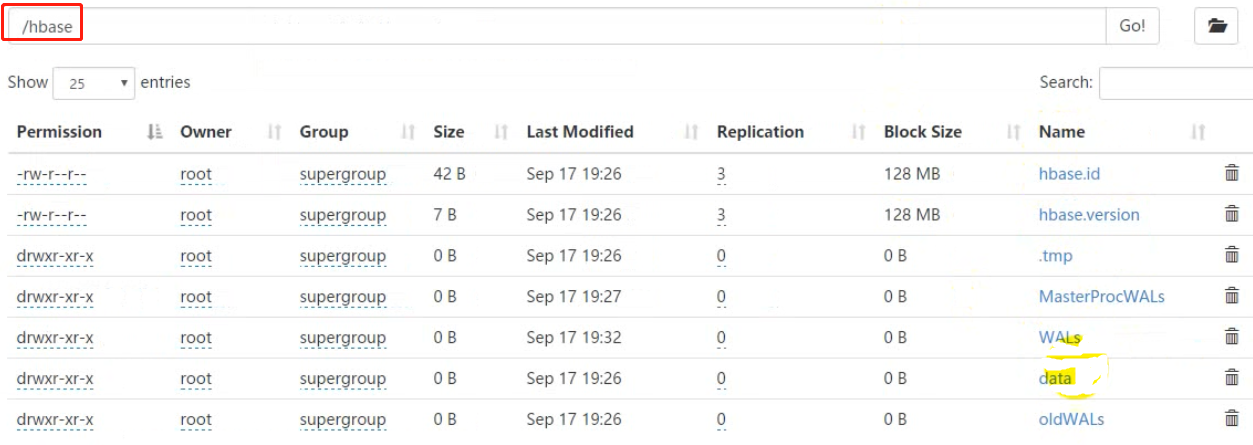
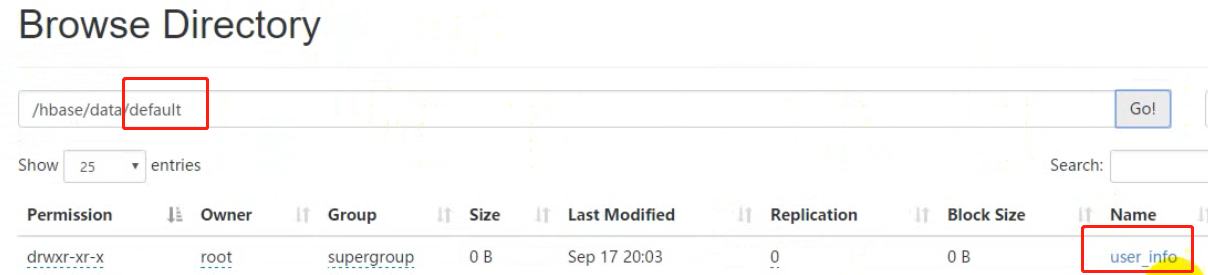
数据存放在data文件下,data文件夹里有default库【默认数据库】,库里会存放用户建立的表,hbase是系统的一些数据。

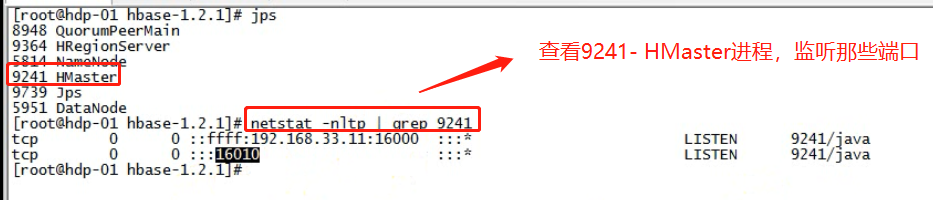
3.3.4、查看Hbase网页端
通过网页端查看Hbase信息,HMaster监听两个端口。一个是内部通信端口16000,一个是外部服务端口16010。



3.3.5、索引表
系统表
记录所有用户表的region位置信息。
索引表,记录索引,哪一个用户表的哪一个region范围在哪一台regionserver上。
客户端找数据的时候,先查索引表,确定自己要访问的数据范围在一个regionserver上,然后再去访问该regionserver去拿数据。


3.3.6、查看Zookeeper
Hbase集群中不同角色的信息沟通是通过Zookeeper的,那么必定会在Zookeeper记录一下状态信息。
4、hbase客户端
4.1、命令行客户端
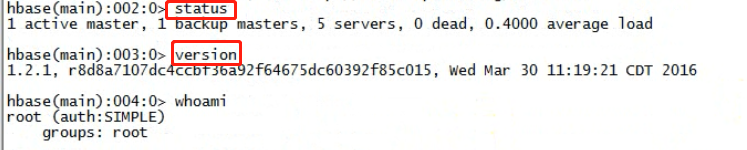
bin/hbase shell Hbase> list // 查看表 Hbase> status // 查看集群状态 Hbase> version // 查看集群版本
进入命令行客户端,help查看都有哪些命令【命令分为不同的组别 ddl dml tools replication...】。
bin/hbase shell
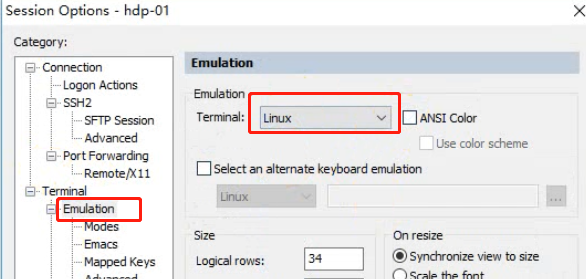
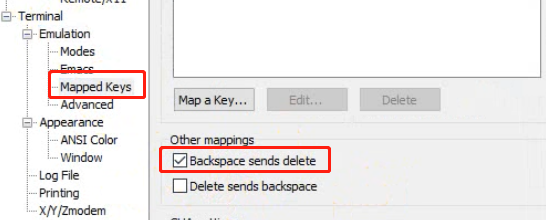
如果shell命令行无法退格删除字符,则如下操作
语句没有分号。
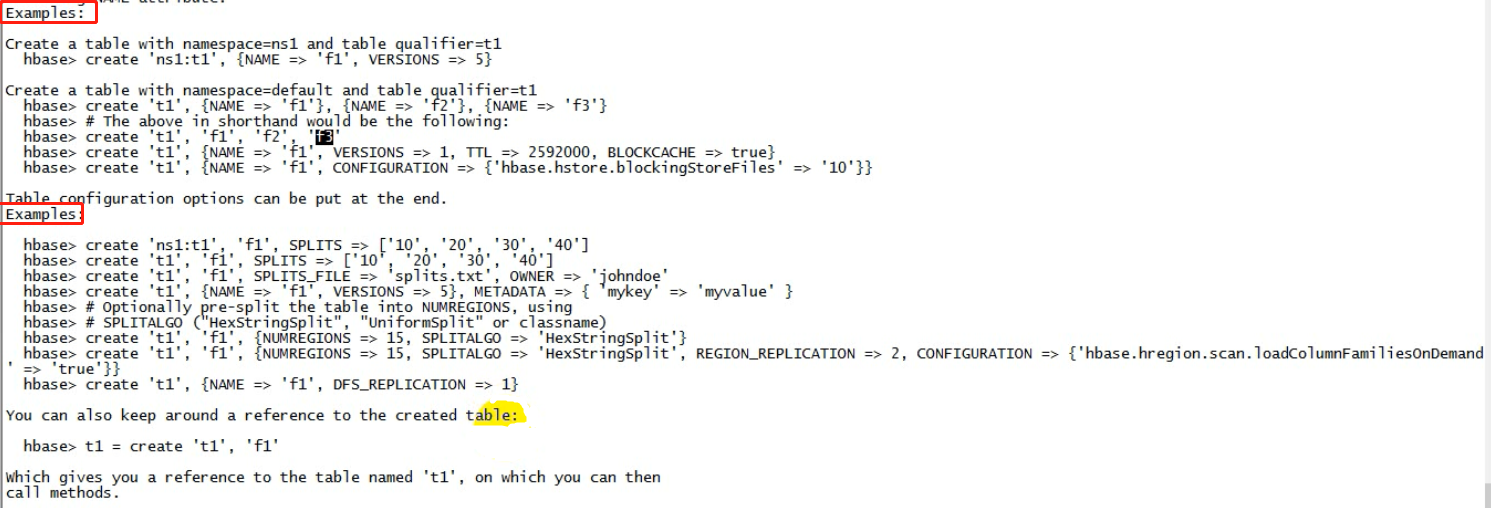
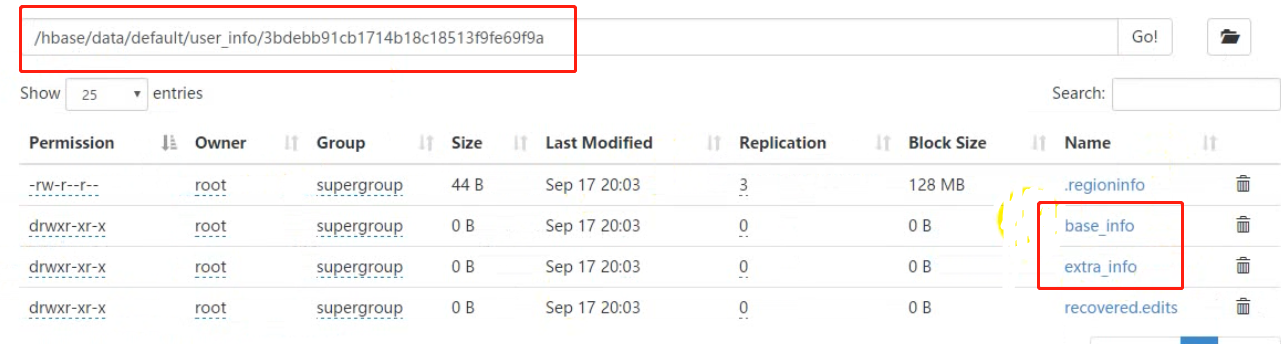
4.1.1、建表
create 't_user_info','base_info','extra_info' 表名 列族名 列族名
查看建表后的状态


HDFS中的数据

4.1.2、插入数据
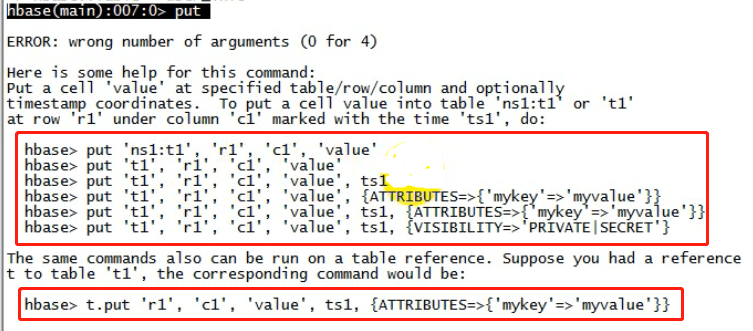
put命令
语法:
put 't_user_info','行健','列族:key','value'
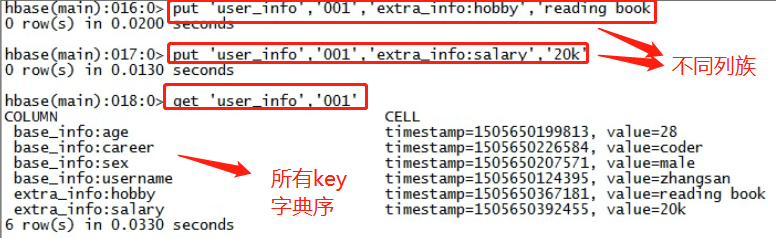
hbase(main):011:0> put 't_user_info','001','base_info:username','zhangsan' 0 row(s) in 0.2420 seconds hbase(main):012:0> put 't_user_info','001','base_info:age','18' 0 row(s) in 0.0140 seconds hbase(main):013:0> put 't_user_info','001','base_info:sex','female' 0 row(s) in 0.0070 seconds hbase(main):014:0> put 't_user_info','001','extra_info:career','it' 0 row(s) in 0.0090 seconds hbase(main):015:0> put 't_user_info','002','extra_info:career','actoress' 0 row(s) in 0.0090 seconds hbase(main):016:0> put 't_user_info','002','base_info:username','liuyifei' 0 row(s) in 0.0060 seconds
4.1.3、查询数据方式一:get 单行查询
语法:
-- 返回该行全部数据 get 't_user_info','行健' -- 返回该行指定列族:key的值 get 't_user_info','行健', '列族:key'
特性:Hbase会对 ' 列族:key ' 进行字典序排序
timestamp:是key的版本号
hbase(main):020:0> get 't_user_info','001' COLUMN CELL base_info:age timestamp=1496568160192, value=19 base_info:sex timestamp=1496567934669, value=female base_info:username timestamp=1496567889554, value=zhangsan extra_info:career timestamp=1496567963992, value=it 4 row(s) in 0.0770 seconds

4.1.3、查询数据方式二:scan 扫描
scan是全表扫描
特性:
1、先按照行健排序。
2、同一行健,按照key的字典序排序。
hbase(main):017:0> scan 't_user_info' ROW COLUMN+CELL 001 column=base_info:age, timestamp=1496567924507, value=18 001 column=base_info:sex, timestamp=1496567934669, value=female 001 column=base_info:username, timestamp=1496567889554, value=zhangsan 001 column=extra_info:career, timestamp=1496567963992, value=it 002 column=base_info:username, timestamp=1496568034187, value=liuyifei 002 column=extra_info:career, timestamp=1496568008631, value=actoress 2 row(s) in 0.0420 seconds
4.1.4、delete 删除一个kv数据
hbase(main):021:0> delete 't_user_info','001','base_info:sex' 0 row(s) in 0.0390 seconds
4.1.5、deleteall 删除整行数据
hbase(main):024:0> deleteall 't_user_info','001' 0 row(s) in 0.0090 seconds hbase(main):025:0> get 't_user_info','001' COLUMN CELL 0 row(s) in 0.0110 seconds
4.1.6、删除整个表
disable
drop
删除表之前先要停用表。

hbase(main):028:0> disable 't_user_info' 0 row(s) in 2.3640 seconds hbase(main):029:0> drop 't_user_info' 0 row(s) in 1.2950 seconds hbase(main):030:0> list TABLE 0 row(s) in 0.0130 seconds => []
4.2、客户端api
DDL
如何描述一个表
如何创建一个表
删除一个表
修改一个表
* 1、构建连接
* 2、从连接中取到一个表DDL操作工具admin
* 3、admin.createTable(表描述对象);
* 4、admin.disableTable(表名);
* 5、admin.deleteTable(表名);
* 6、admin.modifyTable(表名,表描述对象);
DML
4.2.1、创建连接对象
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.HColumnDescriptor; import org.apache.hadoop.hbase.HTableDescriptor; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.client.Admin; import org.apache.hadoop.hbase.client.Connection; import org.apache.hadoop.hbase.client.ConnectionFactory; import org.apache.hadoop.hbase.regionserver.BloomType; Connection conn = null; @Before public void getConn() throws Exception{ // new Configuration() 加载的是hadoop的配置文件:core-site.xml hdfs-site.xml,不会加载hbase-site.xml
// 构建一个连接对象
// Hbase提供了HbaseConfiguraton 用来加载hbase-site.xml
Configuration conf = HBaseConfiguration.create(); // 会自动加载hbase-site.xml
// 客户端查询数据的路由流程可知:客户端需要先链接 Zookeeper 获取索引表 conf.set("hbase.zookeeper.quorum", "hdp-01:2181,hdp-02:2181,hdp-03:2181");
// 创建链接对象 conn = ConnectionFactory.createConnection(conf); }
4.2.2、DDL操作
1、创建一个连接
Connection conn = ConnectionFactory.createConnection(conf);
2、拿到一个DDL操作器:表管理器admin
Admin admin = conn.getAdmin();
3、用表管理器的api去建表、删表、修改表定义
admin.createTable(HTableDescriptor descriptor);
4.2.2.1、创建表
@Test public void testCreateTable() throws Exception{ // 从连接中构造一个DDL操作器 Admin admin = conn.getAdmin(); // 创建一个表定义描述对象 HTableDescriptor hTableDescriptor = new HTableDescriptor(TableName.valueOf("user_info")); // 创建列族定义描述对象
// 通过列族描述定义对象,可以设置列族的很多重要属性信息 HColumnDescriptor hColumnDescriptor_1 = new HColumnDescriptor("base_info"); hColumnDescriptor_1.setMaxVersions(3); // 设置该列族中存储数据的最大版本数,默认是1 HColumnDescriptor hColumnDescriptor_2 = new HColumnDescriptor("extra_info"); // 将列族定义信息对象放入表定义对象中 hTableDescriptor.addFamily(hColumnDescriptor_1); hTableDescriptor.addFamily(hColumnDescriptor_2); // 用ddl操作器对象:admin 来建表 admin.createTable(hTableDescriptor); // 关闭连接 admin.close(); conn.close(); }

4.2.2.2、删除表
先停用表 disableTable
然后删除表 deleteTable
@Test public void testDropTable() throws Exception{ Admin admin = conn.getAdmin(); // 停用表 admin.disableTable(TableName.valueOf("user_info")); // 删除表 admin.deleteTable(TableName.valueOf("user_info")); admin.close(); conn.close(); }
4.2.2.3、修改表
// 修改表定义--添加一个列族 @Test public void testAlterTable() throws Exception{ Admin admin = conn.getAdmin(); // 取出旧的表定义信息 HTableDescriptor tableDescriptor = admin.getTableDescriptor(TableName.valueOf("user_info")); // 新构造一个列族定义 HColumnDescriptor hColumnDescriptor = new HColumnDescriptor("other_info"); hColumnDescriptor.setBloomFilterType(BloomType.ROWCOL); // 设置该列族的布隆过滤器类型 // 将列族定义添加到表定义对象中 tableDescriptor.addFamily(hColumnDescriptor); // 将修改过的表定义交给admin去提交 admin.modifyTable(TableName.valueOf("user_info"), tableDescriptor); admin.close(); conn.close(); }

完整代码


import java.io.IOException; import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.HColumnDescriptor; import org.apache.hadoop.hbase.HTableDescriptor; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.client.Admin; import org.apache.hadoop.hbase.client.Connection; import org.apache.hadoop.hbase.client.ConnectionFactory; import org.apache.hadoop.hbase.regionserver.BloomType; import org.junit.Before; import org.junit.Test; public class HbaseClientDemo { Connection conn = null; @Before public void getConn() throws Exception{ // 构建一个连接对象 Configuration conf = HBaseConfiguration.create(); // 会自动加载hbase-site.xml conf.set("hbase.zookeeper.quorum", "hdp-01:2181,hdp-02:2181,hdp-03:2181"); conn = ConnectionFactory.createConnection(conf); } /** * DDL * @throws Exception */ @Test public void testCreateTable() throws Exception{ // 从连接中构造一个DDL操作器 Admin admin = conn.getAdmin(); // 创建一个表定义描述对象 HTableDescriptor hTableDescriptor = new HTableDescriptor(TableName.valueOf("user_info")); // 创建列族定义描述对象 HColumnDescriptor hColumnDescriptor_1 = new HColumnDescriptor("base_info"); hColumnDescriptor_1.setMaxVersions(3); // 设置该列族中存储数据的最大版本数,默认是1 HColumnDescriptor hColumnDescriptor_2 = new HColumnDescriptor("extra_info"); // 将列族定义信息对象放入表定义对象中 hTableDescriptor.addFamily(hColumnDescriptor_1); hTableDescriptor.addFamily(hColumnDescriptor_2); // 用ddl操作器对象:admin 来建表 admin.createTable(hTableDescriptor); // 关闭连接 admin.close(); conn.close(); } /** * 删除表 * @throws Exception */ @Test public void testDropTable() throws Exception{ Admin admin = conn.getAdmin(); // 停用表 admin.disableTable(TableName.valueOf("user_info")); // 删除表 admin.deleteTable(TableName.valueOf("user_info")); admin.close(); conn.close(); } // 修改表定义--添加一个列族 @Test public void testAlterTable() throws Exception{ Admin admin = conn.getAdmin(); // 取出旧的表定义信息 HTableDescriptor tableDescriptor = admin.getTableDescriptor(TableName.valueOf("user_info")); // 新构造一个列族定义 HColumnDescriptor hColumnDescriptor = new HColumnDescriptor("other_info"); hColumnDescriptor.setBloomFilterType(BloomType.ROWCOL); // 设置该列族的布隆过滤器类型 // 将列族定义添加到表定义对象中 tableDescriptor.addFamily(hColumnDescriptor); // 将修改过的表定义交给admin去提交 admin.modifyTable(TableName.valueOf("user_info"), tableDescriptor); admin.close(); conn.close(); } }
4.2.3、布隆过滤器BloomType
假设有一个互联网爬虫程序,不断将网页中的url爬取下来,这里有一个问题,因为链接可能存在回路,会造成程序的死循环,因此需要判断每条url是否已经被爬取过。
最传统的办法就是将url放入数据库中,每次新爬取的url和数据库进行比对,但是当数据量很大是,每一条url都要和全部的数据进行一次比对,显然不可。
后来出现布隆过滤器专门来解决这个问题。
大致思路:
提供一个64k(或者其他长度,越长精度越大)大小的二进制数组。
将url通过一个算法(简单理解为hash算法)映射成8个bit,对应在一个64k大小的二进制的8个索引上。
经过这个算法索引位置全部吻合的连个url有很大概率是同一个url;
但是索引位置不吻合的两位url一定不是同一个url;
Hbase中的BloomType的应用
之前说过hbase中表在hdfs中是按照如下目录存放的,有hbase的持久化操作可知,一旦内存中的数据写满或者其他原因,就会序列化内存中的数据到hdfs,而内存中保存的是热数据,这样可能会造成同一个key出现在不同的序列化文件中,而且每个key还有不同的版本,更加大了这个可能性。
/库名/表名/region/列族/文件1
.../文件2
.../文件3
.../文件4
问题:
1、不同的文件中可能保存相同的key
2、文件太多,在查询时挨个比对显然效率太低
解决方式:
1、可以为每行数据生成已给bloom过滤器记录
2、或者为每个字段生成一个bloom过滤器记录
这样在找数据的时候,对数据进行结算得到若干比特,然后去比较bloom过滤器,这样会快很多。

4.2.4、DML操作
// 获取一个操作指定表的table对象,进行DML操作 Table table = conn.getTable(TableName.valueOf("user_info"));
import org.apache.hadoop.conf.Configuration; import org.apache.hadoop.hbase.Cell; import org.apache.hadoop.hbase.CellScanner; import org.apache.hadoop.hbase.HBaseConfiguration; import org.apache.hadoop.hbase.TableName; import org.apache.hadoop.hbase.client.Connection; import org.apache.hadoop.hbase.client.ConnectionFactory; import org.apache.hadoop.hbase.client.Delete; import org.apache.hadoop.hbase.client.Get; import org.apache.hadoop.hbase.client.Put; import org.apache.hadoop.hbase.client.Result; import org.apache.hadoop.hbase.client.ResultScanner; import org.apache.hadoop.hbase.client.Scan; import org.apache.hadoop.hbase.client.Table; import org.apache.hadoop.hbase.util.Bytes;
4.2.4.1、增加数据
1、Table对象,进行DML操作;
2、数据封装对象put;
3、Table.put(put) | Table.put(List<put>puts);
/** * 增 * 改:put来覆盖 * @throws Exception */ @Test public void testPut() throws Exception{ // 获取一个操作指定表的table对象,进行DML操作 Table table = conn.getTable(TableName.valueOf("user_info")); // 构造要插入的数据为一个Put类型(一个put对象只能对应一个rowkey)的对象 Put put = new Put(Bytes.toBytes("001")); put.addColumn(Bytes.toBytes("base_info"), Bytes.toBytes("username"), Bytes.toBytes("张三")); put.addColumn(Bytes.toBytes("base_info"), Bytes.toBytes("age"), Bytes.toBytes("18")); put.addColumn(Bytes.toBytes("extra_info"), Bytes.toBytes("addr"), Bytes.toBytes("北京")); Put put2 = new Put(Bytes.toBytes("002")); put2.addColumn(Bytes.toBytes("base_info"), Bytes.toBytes("username"), Bytes.toBytes("李四")); put2.addColumn(Bytes.toBytes("base_info"), Bytes.toBytes("age"), Bytes.toBytes("28")); put2.addColumn(Bytes.toBytes("extra_info"), Bytes.toBytes("addr"), Bytes.toBytes("上海")); ArrayList<Put> puts = new ArrayList<>(); puts.add(put); puts.add(put2); // 插进去 table.put(puts); table.close(); conn.close(); }
/** * 循环插入大量数据 * @throws Exception */ @Test public void testManyPuts() throws Exception{ Table table = conn.getTable(TableName.valueOf("user_info")); ArrayList<Put> puts = new ArrayList<>(); for(int i=0;i<100000;i++){ Put put = new Put(Bytes.toBytes(""+i)); put.addColumn(Bytes.toBytes("base_info"), Bytes.toBytes("username"), Bytes.toBytes("张三"+i)); put.addColumn(Bytes.toBytes("base_info"), Bytes.toBytes("age"), Bytes.toBytes((18+i)+"")); put.addColumn(Bytes.toBytes("extra_info"), Bytes.toBytes("addr"), Bytes.toBytes("北京")); puts.add(put); } table.put(puts); }
4.2.4.2、删除数据
对称结构,插入的时候需要Put对象
删除的时候,需要Delete对象
/** * 删 * @throws Exception */ @Test public void testDelete() throws Exception{ Table table = conn.getTable(TableName.valueOf("user_info")); // 构造一个对象封装要删除的数据信息
// 全部删除 Delete delete1 = new Delete(Bytes.toBytes("001"));
// 删除指定的key Delete delete2 = new Delete(Bytes.toBytes("002"));
// qualifier为用户意义上的key,hbase中 family+qualifier 为一个key delete2.addColumn(Bytes.toBytes("extra_info"), Bytes.toBytes("addr")); ArrayList<Delete> dels = new ArrayList<>(); dels.add(delete1); dels.add(delete2); table.delete(dels); table.close(); conn.close(); }

4.2.4.3、修改数据
使用put来覆盖
4.2.4.5、查看数据
qualifier为用户意义上的key,hbase中 family+qualifier 为一个key
对称结构,插入的时候需要Put对象
删除的时候,需要Delete对象
查看单个行键数据,需要Get对象
4.2.4.5.1、取出单行数据
Table.get(Get)
可以取出该行特定 familyName:key 的 value
也可以遍历该行全部的value
/** * 查 * @throws Exception */ @Test public void testGet() throws Exception{ Table table = conn.getTable(TableName.valueOf("user_info")); // Get对象 指定行健
Get get = new Get("002".getBytes());
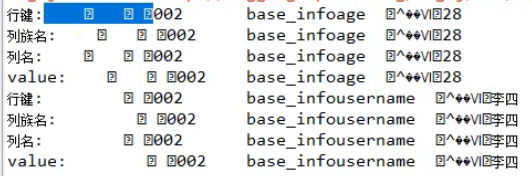
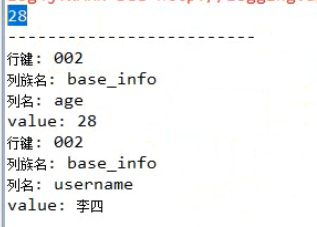
// 行健为002的全部数据 Result result = table.get(get); // 从结果中取用户指定的某个key的value byte[] value = result.getValue("base_info".getBytes(), "age".getBytes()); System.out.println(new String(value)); System.out.println("-------------------------"); // 遍历整行结果中的所有kv单元格
// 类似迭代器 CellScanner cellScanner = result.cellScanner(); while(cellScanner.advance()){ Cell cell = cellScanner.current(); byte[] rowArray = cell.getRowArray(); //本kv所属的行键的字节数组 byte[] familyArray = cell.getFamilyArray(); //列族名的字节数组 byte[] qualifierArray = cell.getQualifierArray(); //列名的字节数据 byte[] valueArray = cell.getValueArray(); // value的字节数组
// Hbase不仅仅是存储用户数据,同时还会存储很多附加的信息,以上get方法直接将用户数据和附加数据一起返回,若想获取用户信息,需要指定其实偏移量和数据长度 System.out.println("行键: "+new String(rowArray,cell.getRowOffset(),cell.getRowLength())); System.out.println("列族名: "+new String(familyArray,cell.getFamilyOffset(),cell.getFamilyLength())); System.out.println("列名: "+new String(qualifierArray,cell.getQualifierOffset(),cell.getQualifierLength())); System.out.println("value: "+new String(valueArray,cell.getValueOffset(),cell.getValueLength())); } table.close(); conn.close(); }
4.2.4.5.2、批量取出数据
取出多个行健范围的数据,需要Scan对象
Table.get(Get)只能取出一个行健范围的数据;
如何按照行健范围取出数据?
table.getScanner(scan)
拿到一个扫描器
/** * 按行键范围查询数据 * @throws Exception */ @Test public void testScan() throws Exception{ Table table = conn.getTable(TableName.valueOf("user_info")); // 包含起始行键,不包含结束行键,但是如果真的想查询出末尾的那个行键,那么,可以在末尾行键上拼接一个不可见的字节(�00)
// Scan scan = new Scan("10".getBytes(), "10000".getBytes());
Scan scan = new Scan("10".getBytes(), "10000�01".getBytes()); ResultScanner scanner = table.getScanner(scan); Iterator<Result> iterator = scanner.iterator(); while(iterator.hasNext()){ // 拿到一行数据 Result result = iterator.next(); // 遍历整行结果中的所有kv单元格 CellScanner cellScanner = result.cellScanner(); while(cellScanner.advance()){ Cell cell = cellScanner.current(); byte[] rowArray = cell.getRowArray(); //本kv所属的行键的字节数组 byte[] familyArray = cell.getFamilyArray(); //列族名的字节数组 byte[] qualifierArray = cell.getQualifierArray(); //列名的字节数据 byte[] valueArray = cell.getValueArray(); // value的字节数组 System.out.println("行键: "+new String(rowArray,cell.getRowOffset(),cell.getRowLength())); System.out.println("列族名: "+new String(familyArray,cell.getFamilyOffset(),cell.getFamilyLength())); System.out.println("列名: "+new String(qualifierArray,cell.getQualifierOffset(),cell.getQualifierLength())); System.out.println("value: "+new String(valueArray,cell.getValueOffset(),cell.getValueLength())); } System.out.println("----------------------"); } }
范围查询的细节
道理:
在真正的结尾行健后面,拼接一个数字0的字节
�00是一个字节,全是0
表示转移,此时后面的0不是数字0,不是字符0
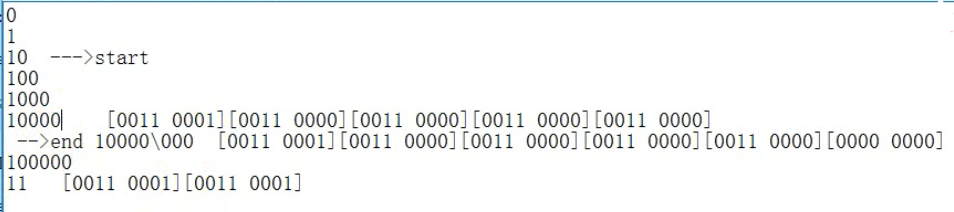
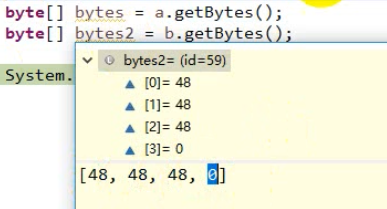
@Test public void test(){ String a = "000"; String b = "000�"; System.out.println(a); System.out.println(b); byte[] bytes = a.getBytes(); byte[] bytes2 = b.getBytes(); System.out.println(""); }
结果
000 000
5、 Hbase重要特性--排序特性(行键)
插入到hbase中去的数据,hbase会自动排序存储:
排序规则: 首先看行键,然后看列族名,然后看列(key)名; 按字典顺序
Hbase的这个特性跟查询效率有极大的关系
比如:一张用来存储用户信息的表,有名字,户籍,年龄,职业....等信息
然后,在业务系统中经常需要:
查询某个省的所有用户
经常需要查询某个省的指定姓的所有用户
思路:如果能将相同省的用户在hbase的存储文件中连续存储,并且能将相同省中相同姓的用户连续存储,那么,上述两个查询需求的效率就会提高!!!
做法:将查询条件拼到rowkey内
6、数据类型
Hbase中只有一种数据类型:二进制数组
Hbase内部没有对放入的数据维护类型。
这就要求,将来往Hbase里插入数据是,需要将数据转换成二进制数组,去除数据后还要进行解析。
无论是表名,列族名,key,还是value都是二进制数组。
在命令行客户端是以字符串形式来显示的二进制数组数据。
7、练习
{
"events": "1473367236143u00010u0001connectByQRCodeu0001u00010u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u00011609072239570000027u0001
1473367261933u00010u0001AppLaunchu0001u00010u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u00011609072239570000028u0001
1473367280349u00010u0001connectByQRCodeu0001u00010u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u00011609072239570000029u0001
1473367331326u00010u0001AppLaunchu0001u00010u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u00011609072239570000030u0001
1473367353310u00010u0001connectByQRCodeu0001u00010u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u00011609072239570000031u0001
1473367387087u00010u0001AppLaunchu0001u00010u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u00011609072239570000032u0001
1473367402167u00010u0001connectByQRCodeu0001u00010u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u00011609072239570000033u0001
1473367451994u00010u0001AppLaunchu0001u00010u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u00011609072239570000034u0001
1473367474316u00010u0001connectByQRCodeu0001u00010u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u00011609072239570000035u0001
1473367564181u00010u0001AppLaunchu0001u00010u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u00011609072239570000036u0001
1473367589527u00010u0001connectByQRCodeu0001u00010u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u00011609072239570000037u0001
1473367610310u00010u0001AppLaunchu0001u00010u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u00011609072239570000038u0001
1473367624647u00010u0001connectByQRCodeu0001u00010u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u00011609072239570000039u0001
1473368004298u00010u0001AppLaunchu0001u00010u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u00011609072239570000040u0001
1473368017851u00010u0001connectByQRCodeu0001u00010u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u00011609072239570000041u0001
1473369599067u00010u0001AppLaunchu0001u00010u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u00011609072239570000042u0001
1473369622274u00010u0001connectByQRCodeu0001u00010u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u0001u00011609072239570000043u0001
",
"header": {
"cid_sn": "1501004207EE98AA",
"mobile_data_type": "",
"os_ver": "22",
"mac": "1c:xx:xx:xx:xx:xx",
"resolution": "1080x1920",
"commit_time": "1473396818952",
"sdk_ver": "103",
"device_id_type": "mac",
"city": "江门市",
"android_id": "86783xx:xx:xx:xx:xx",
"device_model": "HUAWEI VNS-AL00",
"carrier": "中国xx",
"promotion_channel": "1",
"app_ver_name": "1.4",
"imei": "8678300xx:xx:xx:xx:xx",
"app_ver_code": "401xx:xx:xx:xx:xx",
"pid": "pid",
"net_type": "3",
"device_id": "m.1c:xx:xx:xx:xx:xx",
"app_device_id": "m.1c:xx:xx:xx:xx:xx",
"release_channel": "1009",
"country": "CN",
"time_zone": "28800000",
"os_name": "android",
"manufacture": "OPPO",
"commit_id": "fde7ee2e48494b24bf3599771d7c2a78",
"app_token": "XIAONIU_A",
"account": "none",
"app_id": "com.appid.xiaoniu",
"build_num": "YVF6R163xx:xx:xx:xx:xx",
"language": "zh"
}
}
1/假如公司有一个app,每日会在日志服务器上生成大量的日志(在给的样本数据中)
2/公司有一个需求,经常需要在网页上查看某一段时间范围内的日志数据
3/实现思路:
a、每天的日志数据要入库(读文件、解析、插入hbase)
行键:2017-09-17-10-device_id-commit_time .....
分两个列族:events数据列族; headers数据列族
b、开发一个web系统(页面-表单(填查询条件:日期范围; 日期范围+device_id); 页面--展现日志数据表格)
dao层有两种方式: 方式一,继承hbase的客户端jar包,直接在web项目中查询hbase数据
方式二,自己封装一个查询hbase的后台服务,web项目中就去请求你自己的服务
===================未完(下个笔记)==================