一、查询实践
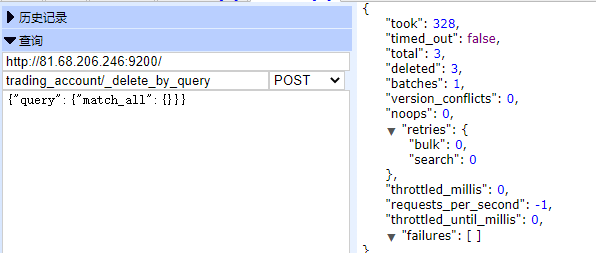
1.清空某个索引下的全部数据
使用 Elasticsearch-head 清空,请求方式 Post ,参数是: 索引名称/_delete_by_query
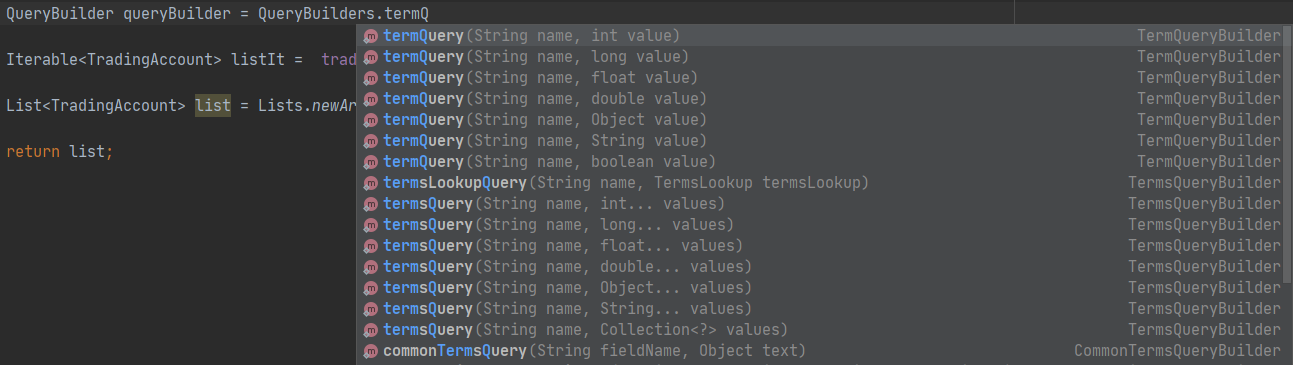
2.QueryBuilders 查询方法
所在包: org.elasticsearch.index.query.QueryBuilders
用法:
QueryBuilder queryBuilder = QueryBuilders.idsQuery("userId",id);
其查询方法非常多,简单列举
1 BoolQueryBuilder boolQuery() 2 BoostingQueryBuilder boostingQuery(QueryBuilder positiveQuery, QueryBuilder negativeQuery) 3 CommonTermsQueryBuilder commonTermsQuery(String fieldName, Object text) 4 ConstantScoreQueryBuilder constantScoreQuery(QueryBuilder queryBuilder) 5 DisMaxQueryBuilder disMaxQuery() 6 ExistsQueryBuilder existsQuery(String name) 7 FieldMaskingSpanQueryBuilder fieldMaskingSpanQuery(SpanQueryBuilder query, String field) 8 FuzzyQueryBuilder fuzzyQuery(String name, String value) 9 IdsQueryBuilder idsQuery() 10 MatchPhrasePrefixQueryBuilder matchPhrasePrefixQuery(String name, Object text) 11 MoreLikeThisQueryBuilder moreLikeThisQuery(String[] likeTexts) 12 PrefixQueryBuilder prefixQuery(String name, String prefix) 13 TermQueryBuilder termQuery(String name, float value) 14 WildcardQueryBuilder wildcardQuery(String name, String query)
....
termQuery 完全匹配
termsQuery
总结: tremQuery 是完全匹配,传递一个参数 termsQuery 是完全匹配多个参数
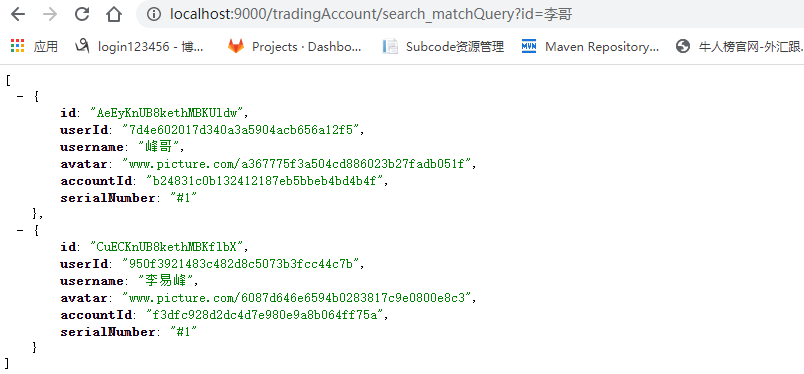
matchQuery
中文会分词匹配、全字符串需要空格分开才可匹配
search_matchAllQuery 查收所有
组合查询:
must(QueryBuilders) = and
mustNot(QueryBuilders) = NOT
should = or
fuzzyQuery 模糊查询 与 matchQuery 相似,但不具备分词匹配
queryStringQuery 对所有的String 串分词匹配查询,单词需要空格分开
wildcardQuery 通配符查询
二、ES 分布式架构原理
elasticsearch 设计的理念就是分布式搜索引擎,底层实现还是基于Lucene 的,核心思想是在多态机器上启动多个 es 进程实例,组成一个es 集群。
1.接近实时
es 是一个接近实时的搜索平台,意味着从索引一个文档到能够被搜索到有一个轻微的延迟
2.集群 cluster
一个集群有多个节点服务器组成,通过所有的节点一起保存全部数据并且通过联合索引和搜索功能的节点的集合,每个集群有一个唯一的名称标识
3.节点 node
一个节点就是一个单一的服务器,是集群的一部分,存储数据并且参与集群的搜索功能
4.索引 index
一个索引就是一些拥有共同特性的集合,一个索引被一个名称唯一标识
5.类型 type
type 在 6.X 中移除(原因是和存储有关)
6.文档 document
一个文档是一个基本的搜索单元、
总结:es 中 存储数据的基本单位是索引,索引类似数据库概念,type 概念相当于表
一个index 里面可以有多个 type ,而 mapping 就相当于表的结构定义,定义了什么类型的字段,就往index 的一个type 添加一行数据,就叫document ,每一个 document 有多个 field
7.分片 shards
在一个搜索里存储的数据,潜在的情况下可能会超过单节点硬件的存储限制,为了解决该问题,创建索引的时候可以指定分片的数量,每一个分片是一个功能完整的独立索引,可以部署到集群的任意节点
8.副本 replica
作用是提高高可用 与搜索能力,搜索行为可以在副本中进行