原文:A Beginner’s Guide to Optimizing Pandas Code for Speed
作者:Sofia Heisler
翻译:无阻我飞扬
摘要:Pandas 是Python Data Analysis Library的简写,它是为了解决数据分析任务而创建的工具,本文介绍了五种由慢到快逐步优化其效率的方法 ,以下是译文
如果你用Python语言做过任何的数据分析,那么可能会用到Pandas,一个由Wes McKinney写的奇妙的分析库。通过赋予Python数据帧以分析功能,Pandas已经有效地把Python和一些诸如R或者SAS这样比较成熟的分析工具置于相同的地位。
不幸的是,在早期,Pandas因“慢”而声名狼藉。的确,Pandas代码不可能达到如完全优化的原始C语言代码的计算速度。然而,好消息是,对于大多数应用程序来说,写的好的Pandas代码已足够快;Pandas强大的功能和友好的用户体验弥补了其速度的缺点。
在这篇文章中,我们将回顾应用于Pandas DataFrame函数的几种方法的效率,从最慢到最快:
1. 在用索引的DataFrame行上的Crude looping
2. 用iterrows()循环
3. 用 apply()循环
4. Pandas Series矢量化
5. NumPy数组矢量化
对于我们的实例函数,将使用Haversine(半正矢)距离公式。函数取两点的经纬度,调整球面的曲率,计算它们之间的直线距离。这个函数看起来像这样:
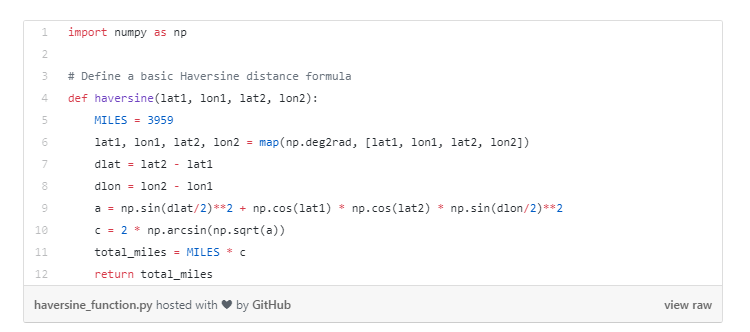
为了在真实数据上测试函数,我们用一个包含纽约所有酒店坐标的数据集,该数据来自Expedia开发者网站。要计算每一个酒店和一个样本集坐标之间的距离(这恰好属于在纽约市名为布鲁克林超级英雄供应店的一个梦幻般的小商店)
大家可以下载数据集,Jupyter notebook(是一个交互式笔记本,支持运行 40 多种编程语言)包含了用于这篇博客的函数,请点击这里下载。
这篇文章基于我的PyCon访谈,大家可以在这里观看。
Pandas中的Crude looping,或者你永远不应该这么做
首先,让我们快速回顾一下Pandas数据结构的基本原理。Pandas的基本结构有两种形式:DataFrame和Series。一个DataFrame是一个二维数组标记轴,很多功能与R中的data.frame类似,可以将DataFrame理解为Series的容器。换句话说,一个DataFrame是一个有行和列的矩阵,列有列名标签,行有索引标签。在Pandas DataFrame中一个单独的列或者行是一个Pandas Series—一个带有轴标签的一维数组。
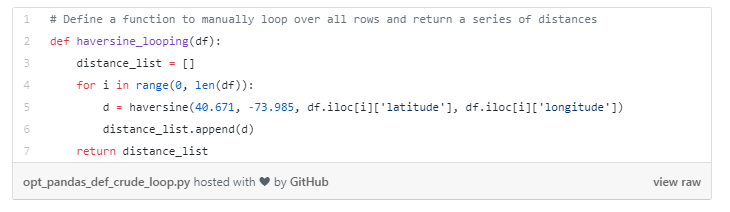
几乎每一个与我合作过的Pandas初学者,都曾经试图通过一次一个的遍历DataFrame行去应用自定义函数。这种方法的优点是,它是Python对象之间交互的一致方式;例如,一种可以通过列表或数组循环的方式。反过来说,不利的一面是,在Pandas中,Crude loop是最慢的方法。与下面将要讨论的方法不同,Pandas中的Crude loop没有利用任何内置优化,通过比较,其效率极低(而且代码通常不那么具有可读性)
例如,有人可能会写像下面这样的代码:
为了了解执行上述函数所需要的时间,我们用%timeit命令。%timeit是一个“神奇的”命令,专用于Jupyter notebook(所有的魔法命令都以%标识开始,如果%命令只应用于一行,那么%%命令应用于整个Jupyter单元)。%timeit命令将多次运行一个函数,并打印出获得的运行时间的平均值和标准差。当然,通过%timeit命令获得的运行时间,运行该函数的每个系统都不尽相同。尽管如此,它可以提供一个有用的基准测试工具,用于比较同一系统和数据集上不同函数的运行时间。

通过分析,crude looping函数运行了大约645ms,标准差是31ms。这似乎很快,但考虑到它仅需要处理大约1600行的代码,因此它实际上是很慢的。接下来看看如何改善这种不好的状况。
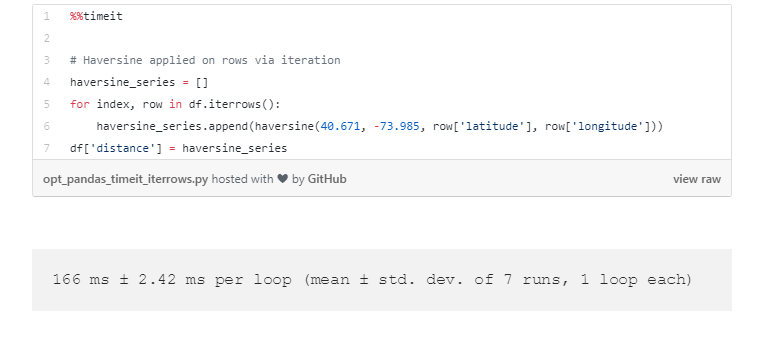
用iterrows()循环
如果循环是必须的,找一个更好的方式去遍历行,比如用iterrows()方法。iterrows()是一个生成器,遍历DataFrame的所有行并返回每一行的索引,除了包含行自身的对象。iterrows() 是用Pandas DataFrame优化,尽管它是运行大多数标准函数最不高效的方式(稍后再谈),但相对于Crude looping,这是一个重大的改进。在我们的案例中,iterrows()解决同一个问题,几乎比手动遍历行快四倍。
使用apply()方法实现更好的循环
一个比iterrows()更好的选择是用 apply() 方法,它应用一个函数,沿着DataFrame某一个特定的轴线(意思就是行或列)。虽然apply()也固有的通过行循环,但它通过采取一些内部优化比iterrows()更高效,例如在Cython中使用迭代器。我们使用一个匿名的lambda函数,每一行都用Haversine函数,它允许指向每一行中的特定单元格作为函数的输入。为了指定Pandas是否应该将函数应用于行(axis = 1)或列(axis = 0),Lambda函数包含最终的axis参数。
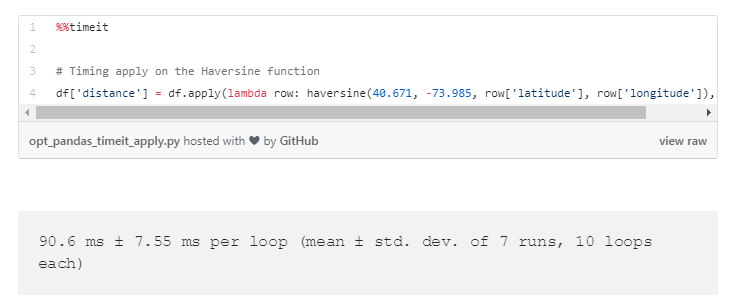
iterrows()方法用apply()方法替代后,大致可以将函数的运行时间减半。为了更深入地了解函数中的实际运行时间,可以运行一个在线分析器工具(Jupyter中神奇的命令%lprun)

结果如下:

我们可以从这个信息中得到一些有用的见解。例如,进行三角计算的函数占了总运行时间的近一半。因此,如果想优化函数的各个组件,可以从这里入手。现在,特别值得注意的是每一行都被循环了1631次—apply()遍历每一行的结果。如果可以减少重复的工作量,就可以降低整个运行时间。矢量化提供了一种更有效的替代方案。
Pandas Series矢量化
要了解如何可以减少函数所执行的迭代数量,就要记得Pandas的基本单位,DataFrame和Series,它们都基于数组。基本单元的固有结构转换成内置的设计用于对整个数组进行操作的Pandas函数,而不是按各个值的顺序(简称标量)。矢量化是对整个数组执行操作的过程。
Pandas包含一个总体的矢量化函数集合,从数学运算到聚合和字符串函数(可用函数的扩展列表,查看Pandas docs)。对Pandas Series和DataFrame的操作进行内置优化。结果,使用矢量Pandas函数几乎总是会用自定义的循环实现类似的功能。
到目前为止,我们仅传递标量给Haversine函数。所有的函数都应用在Haversine函数中,也可以在数组上操作。这使得距离矢量化函数的过程非常的简单:不是传递个别标量值的纬度和经度给它,而是把它传递给整个series(列)。这使得Pandas受益于可用于矢量函数的全套优化,特别是包括同时执行整个数组的所有计算。
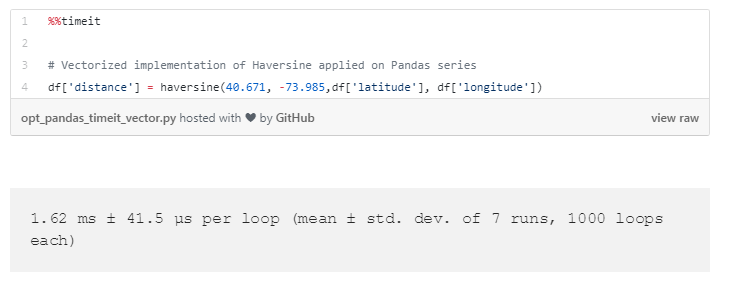
通过使用apply()方法,要比用iterrows()方法改进50倍的效率,通过矢量化函数则改进了iterrows()方法100倍—除了改变输入类型,什么都不要做!
看一眼后台,看看函数到底在做什么:

注意,鉴于 apply() 执行函数1631次,矢量化版本仅执行一次,因为它同时应用于整个数组,这就是主要的时间节省来源。
用NumPy数组矢量化
Pandas series矢量化可以完成日常计算优化的绝大多数需要。然而,如果速度是最高优先级,那么可以以NumPy Python库的形式调用援军。
NumPy库,将自己描述为一个“Python科学计算的基本包”,在后台执行优化操作,预编译C语言代码。跟Pandas一样,NumPy操作数组对象(简称ndarrays);然而,它省去了Pandas series操作所带来的大量资源开销,如索引、数据类型检查等。因此,NumPy数组的操作可以明显快于pandas series的操作。
当Pandas series提供的额外功能不是很关键的时候,NumPy数组可以用于替代Pandas series。例如,Haversine函数矢量化实现不使用索引的经度和纬度系列,因此没有那些索引,也不会导致函数中断。通过比较,我们所做的操作如DataFrame的连接,它需要按索引来引用值,可能需要坚持使用Pandas对象。
仅仅是使用Pandas series 的values的方法,把纬度和经度数组从Pandas series转换到NumPy数组。就像series矢量化一样,通过NumPy数组直接进入函数将可以让Pandas对整个矢量应用函数。
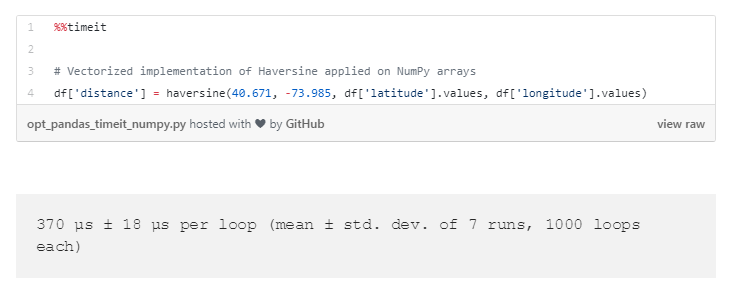
NumPy数组操作运行取得了又一个四倍的改善。总之,通过looping改进了运行时间超过半秒,通过NumPy矢量化,运行时间改进到了三分之一毫秒级!
总结
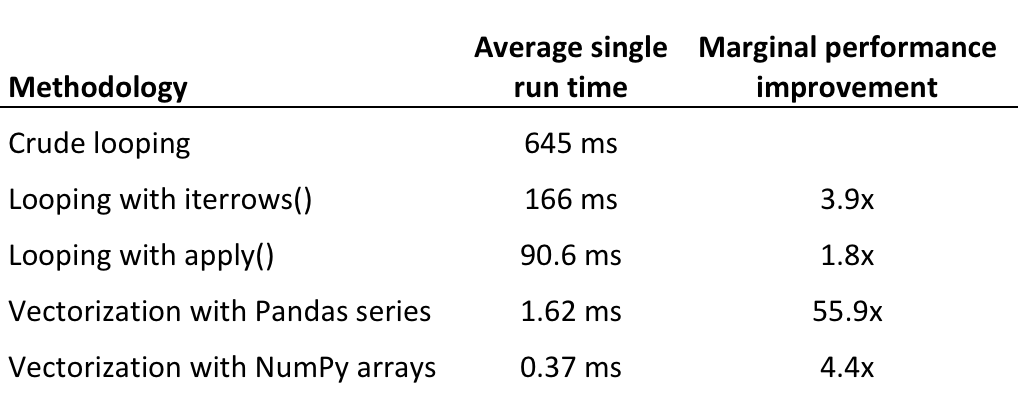
下面的表格总结了相关结果。用NumPy数组矢量化将会带来最快的运行时间,相对于Pandas series矢量化的效果而言,这是一个很小的改进,但对比最快的looping版本,NumPy数组矢量化带来了56倍的改进。
这给我们带来了一些关于优化Pandas代码的基本结论:
- 避免循环;它们很慢,而且在大多数情况下是不必要的。
- 如果必须使用循环,用 apply(),而不是迭代函数。
- 矢量化通常优于标量运算。在Pandas中的大部分常见操作都可以矢量化。
- NumPy数组矢量化操作比Pandas series更有效。
当然,以上并不是Pandas所有可能优化的全面清单。更爱冒险的用户或许可以考虑进一步用Cython改写函数,或者尝试优化函数的各个组件。然而,这些话题超出了这篇文章的范围。
关键的是,在开始一次宏大的优化冒险之前,要确保正在优化的函数实际上是你希望在长期运行中使用的函数。引用XKCD不朽的名言:“过早优化是万恶之源”。