1、关系
Availability Zones 通常是对 computes 节点上的资源在小的区域内进行逻辑上的分组和隔离。例如在同一个数据中心,我们可以将 Availability Zones 规划到不同的机房,或者在同一机房的几个相邻的机架,从而保障如果某个 Availability Zone 的节点发生故障(如供电系统或网络),而不影响其他的 Availability Zones 上节点运行的虚拟机,通过这种划分来提高 OpenStack 的可用性。目前 OpenStack 默认的安装是把所有的 computes 节点划分到 nova 的 Availability Zone 上,但我们可以通过对 nova.conf 文件的配置来定义不同的 Availability zones。
/etc/nova/nova.conf
scheduler_default_filters=AggregateInstanceExtraSpecsFilter,其他filter
host aggregate是管理员用来根据硬件资源的某一属性来对硬件进行划分的功能,只对管理员可见,主要用来给nova-scheduler通过某一属性来进行instance的调度。其主要功能就是实现根据某一属性来划分物理机,比如按照地理位置,使用固态硬盘的机器,内存超过32G的机器,根据这些指标来构成一个host group。
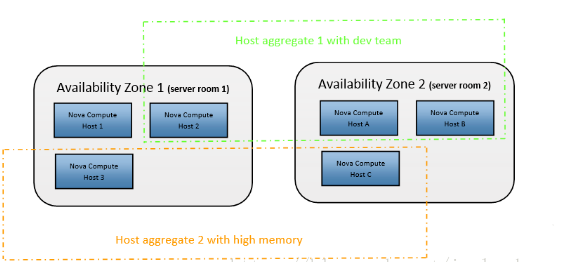
2、例子
此示例配置Compute服务以使用户能够请求具有固态驱动器(SSD)的节点。 您可以在nova可用域中创建fast-io主机集群,并将ssd = true键值对添加到该集群中。 然后,将node1和node2计算节点添加到该集群中。
$ nova aggregate-create fast-io nova +----+---------+-------------------+-------+----------+ | Id | Name | Availability Zone | Hosts | Metadata | +----+---------+-------------------+-------+----------+ | 1 | fast-io | nova | | | +----+---------+-------------------+-------+----------+ $ nova aggregate-set-metadata 1 ssd=true +----+---------+-------------------+-------+-------------------+ | Id | Name | Availability Zone | Hosts | Metadata | +----+---------+-------------------+-------+-------------------+ | 1 | fast-io | nova | [] | {u'ssd': u'true'} | +----+---------+-------------------+-------+-------------------+ $ nova aggregate-add-host 1 node1 +----+---------+-------------------+------------+-------------------+ | Id | Name | Availability Zone | Hosts | Metadata | +----+---------+-------------------+------------+-------------------+ | 1 | fast-io | nova | [u'node1'] | {u'ssd': u'true'} | +----+---------+-------------------+------------+-------------------+ $ nova aggregate-add-host 1 node2 +----+---------+-------------------+----------------------+-------------------+ | Id | Name | Availability Zone | Hosts | Metadata | +----+---------+-------------------+----------------------+-------------------+ | 1 | fast-io | nova | [u'node1', u'node2'] | {u'ssd': u'true'} | +----+---------+-------------------+----------------------+-------------------+
使用nova flavor-create命令创建使用ID为6,8 GB的RAM,80GB的disk和4个vCPU的一个规格,名称为:ssd.large。
$ nova flavor-create ssd.large 6 8192 80 4 +----+-----------+-----------+------+-----------+------+-------+-------------+-----------+ | ID | Name | Memory_MB | Disk | Ephemeral | Swap | VCPUs | RXTX_Factor | Is_Public | +----+-----------+-----------+------+-----------+------+-------+-------------+-----------+ | 6 | ssd.large | 8192 | 80 | 0 | | 4 | 1.0 | True | +----+-----------+-----------+------+-----------+------+-------+-------------+-----------+
创建flavor后,指定一个或多个键值对,让这些键值对与主机集群上的键值对匹配,范围为aggregate_instance_extra_specs。 在这种情况下,设置格式为:aggregate_instance_extra_specs:ssd = true键值对。
可以使用nova flavor-key命令在flavor上设置键值对。
nova flavor-key ssd.large set aggregate_instance_extra_specs:ssd=true
设置后,您应该看到ssd.large的extra_specs属性填充了ssd的键和相应的值true。
nova flavor-show ssd.large +----------------------------+--------------------------------------------------+ | Property | Value | +----------------------------+--------------------------------------------------+ | OS-FLV-DISABLED:disabled | False | | OS-FLV-EXT-DATA:ephemeral | 0 | | disk | 80 | | extra_specs | {u'aggregate_instance_extra_specs:ssd': u'true'} | | id | 6 | | name | ssd.large | | os-flavor-access:is_public | True | | ram | 8192 | | rxtx_factor | 1.0 | | swap | | | vcpus | 4 | +----------------------------+--------------------------------------------------+
现在,当用户请求具有ssd.large规格的实例时,调度程序仅考虑具有ssd = true键值对的主机。 在此示例中,这些是node1和node2。因为node1和node2所的集群fast-io设置了属性{u'ssd': u'true'},使得与规格ssd.large里面的extra_specs的对应。