一、re模块
1、正则的概念:
正则就是用一些具有特殊含义的符号组合到一起(称为正则表达式)来描述字符或者字符串的方法。或者说:正则就是用来描述一类事物的规则。(在Python中)它内嵌在Python中,并通过 re 模块实现。正则表达式模式被编译成一系列的字节码,然后由用 C 编写的匹配引擎执行。
2、常用匹配模式(元字符)
import re
w与W
print(re.findall("w","hello_123 * -+")) # 小w匹配字母数字下划线
print(re.findall("W","hello_123 * -+")) # 大W匹配非字母数字下划线
print(re.findall("awb","a1b a_b a+b a-b aab aaaaaab"))
s与S
print(re.findall("s","a b
c123")) # 小s取空格符
print(re.findall("S","a_b+ * b
c123")) # 大S取非空格符
d与D
print(re.findall("d","a b
c123")) # 只匹配数字
print(re.findall("D","a b
c123")) # 取非数字
^与$
print(re.findall("^awb","a1b a_b a+b a-b aab aaaaaab")) # ^匹配第一个
print(re.findall("awb$","a1b a_b a+b a-b aab aaaaaab")) # $匹配最后一个
print(re.findall('^egon$',"egon")) # 第一个和最后一个
A与
print(re.findall('Ahe','hello egon 123')) # A==>^匹配第一个
print(re.findall('123','hello egon 123')) #==>$ 匹配最后一个
^== 指定匹配必须出现在字符串的开头或行的开头。
A ==指定匹配必须出现在字符串的开头(忽略 Multiline 选项)。
$ ==指定匹配必须出现在以下位置:字符串结尾、字符串结尾的
之前或行的结尾。
==指定匹配必须出现在字符串的结尾或字符串结尾的
之前(忽略 Multiline 选项)。
print(re.findall('^egon$',"""
egon
123egon
egon123
egon
""",re.M)) # 取^$,re.M是可以换行取值
print(re.findall('Aegon',"""
egon
123egon
egon123
egon
""",re.M)) # 用A不能换行匹配
与
print(re.findall(r'
','hello e
gon
123')) # 取['
']
print(re.findall(r' ','hello eg
on 123')) # 取[' ']
其他
print(re.findall('a.c',"a1c a2c aAc a
c aaaac")) #除了换行符以外的任意字符
print(re.findall('a.c',"a1c a2c aAc a
c aaaac",re.DOTALL)) #匹配任意字符
print(re.findall('a[1+]c',"a1c a+c aAc a
c aaaac",re.DOTALL)) #指定匹配1或+
print(re.findall('a[0-9]c',"a1c a9c a10c aAc a
c aaaac",re.DOTALL)) #指定0-9范围
print(re.findall('a[a-z]c',"a1c a9c a10c aAc a
c aaaac",re.DOTALL)) #指定a-z小写字母范围
print(re.findall('a[A-Z]c',"a1c a9c a10c aAc a
c aaaac",re.DOTALL)) #指定A-Z大写字母范围
print(re.findall('a[-+*/]c',"a+c a-c a*c a/c a1c a9c aAc")) #指定+-*/,-不能放中间,-代表范围
print(re.findall('a[^-+*/]c',"a+c a-c a*c a/c a1c a9c aAc")) # 取反,除了+-*/。都可以取
?:左边那一个字符出现0次或者1次
print(re.findall('ab?',"b a abbbbbbbb ab"))
print(re.findall('ab{0,1}',"b a abbbbbbbb ab"))
*:左边那一个字符出现0次或者无穷次
print(re.findall('ab*',"b a abbbbbbbb ab"))
print(re.findall('ab{0,}',"b a abbbbbbbb ab"))
+:左边那一个字符出现1次或者无穷次
print(re.findall('ab+',"b a abbbbbbbb ab"))
print(re.findall('ab{1,}',"b a abbbbbbbb ab"))
{n,m}:左边那一个字符出现n次或m次
print(re.findall('ab{2,4}',"b a abbbbbbbb ab"))
print(re.findall('ab{2,4}',"b a abb abbb abbbbbbbb ab"))
# ===========================re模块提供的方法介绍===========================
import re
#1
print(re.findall('e','alex make love') ) #['e', 'e', 'e'],返回所有满足匹配条件的结果,放在列表里
#2
print(re.search('e','alex make love').group()) #e,只到找到第一个匹配然后返回一个包含匹配信息的对象,该对象可以通过调用group()方法得到匹配的字符串,如果字符串没有匹配,则返回None。
#3
print(re.match('e','alex make love')) #None,同search,不过在字符串开始处进行匹配,完全可以用search+^代替match
#4
print(re.split('[ab]','abcd')) #['', '', 'cd'],先按'a'分割得到''和'bcd',再对''和'bcd'分别按'b'分割
#5
print('===>',re.sub('a','A','alex make love')) #===> Alex mAke love,不指定n,默认替换所有
print('===>',re.sub('a','A','alex make love',1)) #===> Alex make love
print('===>',re.sub('a','A','alex make love',2)) #===> Alex mAke love
print('===>',re.sub('^(w+)(.*?s)(w+)(.*?s)(w+)(.*?)$',r'52341','alex make love')) #===> love make alex
print('===>',re.subn('a','A','alex make love')) #===> ('Alex mAke love', 2),结果带有总共替换的个数
#6
obj=re.compile('d{2}')
print(obj.search('abc123eeee').group()) #12
print(obj.findall('abc123eeee')) #['12'],重用了obj
二、json&pickle模块
之前我们学习过用eval内置方法可以将一个字符串转成python对象,不过,eval方法是有局限性的,对于普通的数据类型,json.loads和eval都能用,但遇到特殊类型的时候,eval就不管用了,所以eval的重点还是通常用来执行一个字符串表达式,并返回表达式的值。
什么是序列化?
我们把对象(变量)从内存中变成可存储或传输的过程称之为序列化,在Python中叫pickling,在其他语言中也被称之为serialization,marshalling,flattening等等,都是一个意思。
为什么要序列化?
^ 持久保存状态
^ 跨平台数据交互
json
1、json序列化
import json
dic = {'name':"egon","xxx":True,"yyy":None,"zzz":1.3}
dic_json = json.dumps(dic)
print(dic_json,type(dic_json)) # 已序列化
with open('a.json',mode='wt',encoding='utf-8') as f:
f.write(dic_json) #文件写入序列化
json.dump(dic,open('a.json',mode='wt',encoding='utf-8')) #文件序列化一行搞定
2、json反序列化
import json
with open('a.json',mode='rt',encoding='utf-8') as f:
res = f.read()
dic = json.loads(res)
print(dic["xxx"]) #文件读反序列化
dic = json.load(open('a.json',mode='rt',encoding='utf-8'))
print(dic['xxx']) # 文件读反序列化 一行搞定
3、dumps 存数据时,先序列化,编成一个所有语言都能用的
dump 直接存文件
res = json.dumps((1,2,3))
print(res)
#json 没有元组,会转换成列表[1,2,3]
4、loads
dic = json.loads('{"k":true}')
print(dic)
# 手写的json格式转换成字典用loads 手写时千万不能用单引号,会报错
JSON表示的对象就是标准的JavaScript语言的对象,JSON和Python内置的数据类型对应如下:
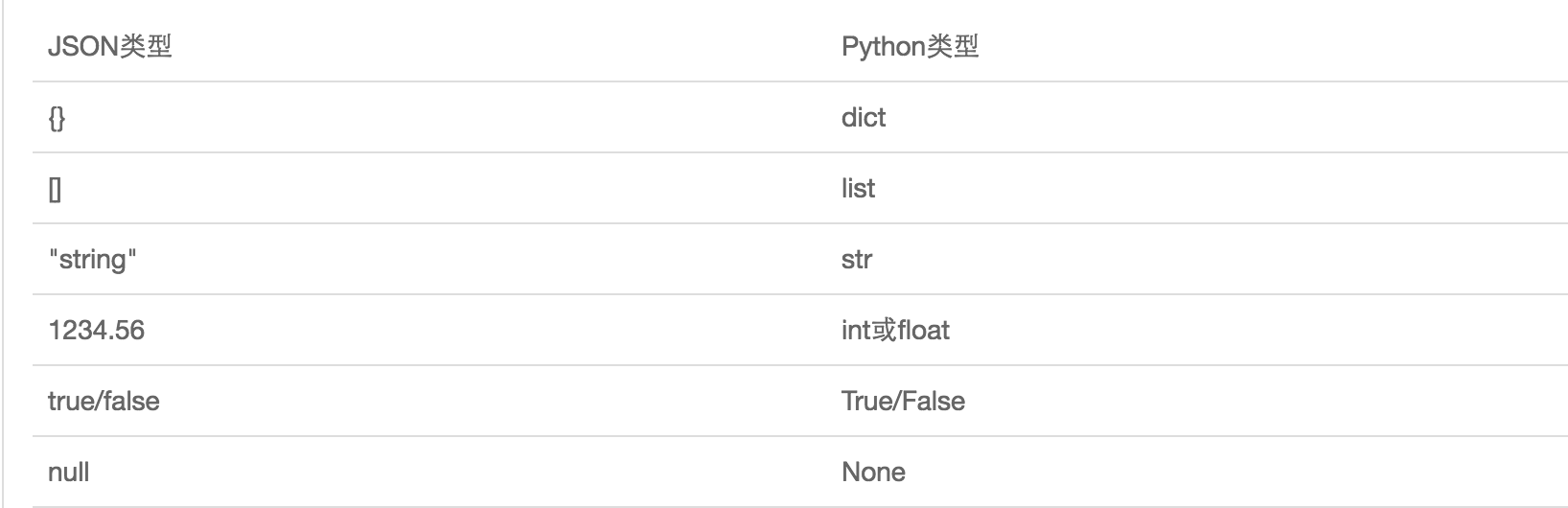
集合类型不能序列化,从而引发了pickle 模式
import pickle
res = pickle.dumps({1,2,3,4,5})
print(res) # 是二进制类型
pickle.dump({1,2,3,4,5},open('b.pkl',mode='wb')) #用b模式序列化
s = pickle.load(open('b.pkl',mode='rb')) #用b模式反序列化
print(s,type(s))
三、猴子补丁
属性在运行时的动态替换,叫做猴子补丁(Monkey Patch)
猴子补丁的核心就是用自己的代码替换所用模块的源代码
猴子补丁的功能(一切皆对象)
拥有在模块运行时替换的功能, 例如: 一个函数对象赋值给另外一个函数对象(把函数原本的执行的功能给替换了)
monkey patch的应用场景
如果我们的程序中已经基于json模块编写了大量代码了,发现有一个模块ujson比它性能更高,
但用法一样,我们肯定不会想所有的代码都换成ujson.dumps或者ujson.loads,那我们可能
会想到这么做
import ujson as json,但是这么做的需要每个文件都重新导入一下,维护成本依然很高
此时我们就可以用到猴子补丁了
只需要在入口处加上
, 只需要在入口加上:
import json
import ujson
def monkey_patch_json():
json.__name__ = 'ujson'
json.dumps = ujson.dumps
json.loads = ujson.loads
monkey_patch_json() # 之所以在入口处加,是因为模块在导入一次后,后续的导入便直接引用第一次的成果
四、时间模块 time 与 datetime
时间分为三种格式:
1、时间戳
print(time.time()) #表示的是从1970年1月1日00:00:00开始按秒计算的偏移量,返回的是float类型
2、格式化的时间字符串
print(time.strftime("%Y-%m-%d %X")) #格式化的时间字符串:'2021-01-06 20:24:13'
3、 结构化的时间,元组共有9个元素共九个元素:(年,月,日,时,分,秒,一年中第几周,一年中第几天,夏令时)
print(time.localtime()) #本地时区的struct_time
print(time.gmtime()) #UTC时区的struct_time
datetime 模块
时间加减
import datetime
# print(datetime.datetime.now()) #返回 2016-08-19 12:47:03.941925
#print(datetime.date.fromtimestamp(time.time()) ) # 时间戳直接转成日期格式 2016-08-19
# print(datetime.datetime.now() )
# print(datetime.datetime.now() + datetime.timedelta(3)) #当前时间+3天
# print(datetime.datetime.now() + datetime.timedelta(-3)) #当前时间-3天
# print(datetime.datetime.now() + datetime.timedelta(hours=3)) #当前时间+3小时
# print(datetime.datetime.now() + datetime.timedelta(minutes=30)) #当前时间+30分
# c_time = datetime.datetime.now()
# print(c_time.replace(minute=3,hour=2)) #时间替换
五、random模块
import random
print(random.random())#(0,1)----float 大于0且小于1之间的小数
print(random.randint(1,3)) #[1,3] 大于等于1且小于等于3之间的整数
print(random.randrange(1,3)) #[1,3) 大于等于1且小于3之间的整数
print(random.choice([1,'23',[4,5]]))#1或者23或者[4,5]
print(random.sample([1,'23',[4,5]],2))#列表元素任意2个组合
print(random.uniform(1,3))#大于1小于3的小数,如1.927109612082716
item=[1,3,5,7,9]
random.shuffle(item) #打乱item的顺序,相当于"洗牌"
print(item)
生成随机验证码
import random
def make_code(n):
res=''
for i in range(n):
s1=chr(random.randint(65,90))
s2=str(random.randint(0,9))
res+=random.choice([s1,s2])
return res
print(make_code(9))