如果要下载的是一张图片,一个文件,已知图片地址、文件地址、或者是后端get类型接口(接口返回文件流)
可以使用 HTML5中,a 标签新增的 download 属性
download属性可以自定义下载后的文件名,包含该属性的链接被点击时,浏览器会以下载文件方式下载。
代码示例:
<a href="https://xxx.com/assets/goods.png" download="商品.png">下载</a>
上述a链接的下载方式也可通过JS实现:
通过 js动态创建一个包含 download 属性的 a 元素,再触发点击事件,即可实现前端下载。
代码示例:
function download(href, title) { const a = document.createElement('a'); a.setAttribute('href', href); a.setAttribute('download', title); a.click(); }
说明:
- href 属性设置要下载的文件地址。这个地址支持多种方式的格式,因此可以实现丰富的下载方法。
- download 属性设置了下载文件的名称。但 href 属性为普通链接并且跨域时,该属性值设置多数情况下会被浏览器忽略。
优点:最简洁;
弊端:当href地址有误,或接口请求失败,这时无法监听错误信息,点击a链接会页面中直接输出错误信息,体验不好;
当在下载.mp3格式,或者视频文件时,浏览器会直接播放该文件,而达不到直接下载的功能
其他的方法:form、iframe、location.href、window.open(),这里就不细讲了。
通过请求的方式下载文件,可以解决无法监听错误信息的弊端,也可以实现post请求下载文件
1.首先请求服务端接口,将接口返回内容拿下来,你可以使用任何库,比如:ajax、fetch、axios等,当然也可以使用XMLHttpRequest
此处给出axios的示例:
axios({ url: '/api/file/info/download/' + ids, // ids是我接口的参数 method: 'post', // 根据接口定义的请求类型 responseType: 'blob', // 接口返回文件流的话,需要增加这个属性 headers: { 'Authorization': `${getToken()}` } // 请求头参数 }).then(res => { saveAs(res.data,fileName) this.$message.success('下载成功') }).catch(e => { this.$message.error('下载失败') })
加不加【responseType: 'blob'】从浏览器控制台的network上看不出来,如下图:
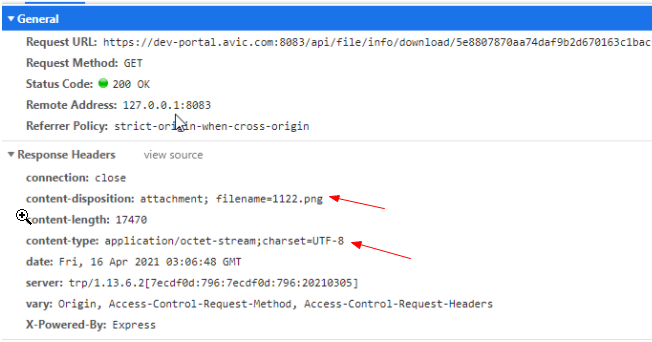

加不加【responseType: 'blob'】,控制台network的【Headers】和【Preview】没有区别
此时我们打印接口返回的数据res(response返回体),如下图:
【没加的情况】

【加上的情况】

请求头没有设置【responseType: 'blob'】,response.data是一串字符串,设置了responseType,response.data是Blob类型的二进制流。
字符串转Blob,可以使用 new Blob(res.data)
细心的你可以发现,【Response Headers】中箭头标出的两个属性:content-disposition、content-type
【Content-disposition】:attachment;filename="fliename.fileType"
用于指定文件类型、文件名等,浏览器接收到响应头后(重点是attachment)就会触发下载行为。服务器向浏览器发送文件时,如果是浏览器支持的文件类型,一般会默认使用浏览器打开,比如
txt、jpg等。如果需要提示用户保存,就要利用Content-Disposition进行处理,(敲黑板,划重点)关键在于一定要加上attachment
【Content-type】:application/octet-stream;charsetUTF-8
Content-type用于定义网络文件的类型和网页的编码,决定浏览器将以什么形式、什么编码读取这个文件。
application/octet-stream 二进制流数据(如常见的文件下载)
参考文档: HTTP content-type
拿到后台返回的数据我们又该如何处理呢?
一、使用URL.createObjectURL(blob),创建一个指向blob对象的“内存引用”,并结合a标签的download属性实现下载
二、使用FileReader的readAsDataURL转化为base64,并结合a标签的download属性实现下载
注意:a标签的download属性不兼容IE11及其以下,使用window.navigator.msSaveBlob替代
方法一:
const saveAs = (blob, filename) => { if (window.navigator.msSaveOrOpenBlob) { navigator.msSaveBlob(blob, filename) } else { const link = document.createElement('a') const body = document.querySelector('body') link.href = window.URL.createObjectURL(blob) // 创建对象url link.download = filename link.style.display = 'none' body.appendChild(link) link.click() body.removeChild(link) window.URL.revokeObjectURL(link.href) // 销毁对象url } }
方法二:
const saveAs = (blob, filename) => { if (window.navigator.msSaveOrOpenBlob) { navigator.msSaveBlob(blob, filename) } else { const reader = new FileReader(); reader.readAsDataURL(blob); // 转换为base64,可以直接放入a标签的href里 reader.onload = function (e) { const link = document.createElement('a') const body = document.querySelector('body') link.href = e.target.result link.download = filename link.style.display = 'none' body.appendChild(link) link.click() body.removeChild(link) } } }
URL.createObjectURL与FileReader.readAsDataURL比较
相同点:二者都接受一个Blob或File做为参数
区别
通过FileReader.readAsDataURL(file)可以获取一段data:base64的字符串
通过URL.createObjectURL(blob)可以获取当前文件的一个内存URL
执行时机
createObjectURL是同步执行(立即的)
FileReader.readAsDataURL是异步执行(过一段时间)
内存使用
createObjectURL返回一段带hash的url,并且一直存储在内存中,直到document触发了unload事件(例如:document close关闭浏览器)或者执行revokeObjectURL来释放。
FileReader.readAsDataURL则返回包含很多字符的base64,并会比blob url消耗更多内存,但是在不用的时候会自动从内存中清除(通过垃圾回收机制)
兼容性方面两个属性都兼容ie10以上的浏览器。
优劣对比:
使用createObjectURL可以节省性能并更快速,只不过需要在不使用的情况下手动释放内存
如果不太在意设备性能问题,并想获取图片的base64,则推荐使用FileReader.readAsDataURL
扩展:
此处贴上链接:供予学习