前言
微服务架构下,会有很多微服务,服务之间调用关系会非常复杂,就非常有必要对每个请求的完整调用链进行跟踪,了解调用了那些服务,当出现问题时可以快速定位。
Spring Cloud Sleuth 为 Spring Cloud 实现了一个分布式跟踪解决方案,该组件大量借签了 Dapper、Zipkin 和 HTrace。
对于大多数用户来说,Sleuth 应该是不可见的,它会自动检测系统的交互,可以在日志中捕获跟踪数据,或将其它送到远程日志收集服务器。
Spring Cloud Sleuth 官方文档,Sleuth Zipkin 日志存储跟踪示例,Zipkin GitHub Zipkin UI 示例、OpenZipkin/Brave 捕获延迟信息的库。
1. Sleuth
1.1 Spring Cloud 集成 Sleuth
在详细介绍 Sleuth 之前,先通过 Spring Cloud 集成 Sleuth 来查看效果,可能更直观的理解。
- 准备工作
这里我们需要创建两个微服务Server-Provider1和Server-Provider2,它们都具有一个名为hello的REST接口,Server-Provider1的hello接口依赖于Server-Provider2的hello接口。
并将这两个服务注册到Eureka-Server服务注册中心集群。Eureka-Server服务注册中心集群直接使用https://mrbird.cc/Spring-Cloud-Eureka.html里构建的即可,这里不再赘述。
- 创建Server-Provider1
1、新建一个Spring Boot工程,artifactId为Server-Provider1,并引入如下依赖:
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-eureka</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-ribbon</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-sleuth</artifactId>
</dependency>
</dependencies>
spring-cloud-starter-eureka用于注册微服务,spring-cloud-starter-ribbon用于调用Server-Provider2提供的服务,spring-cloud-starter-sleuth为Spring Cloud Sleuth依赖,用于跟踪微服务请求。
2、接着在配置文件application.yml里添加如下配置:
spring: application: name: server-provider1 server: port: 9000 eureka: client: serviceUrl: defaultZone: http://mrbird:123456@peer1:8080/eureka/,http://mrbird:123456@peer2:8081/eureka/
配置中指定了微服务名称为server-provider1,端口号为9000以及服务注册中心地址。
3、配置logback-spring.xml文件,在Pattern中使用 ${LOG_LEVEL_PATTERN:-%5p},日志中会输出TraceId的信息:
<appender name="Console" class="ch.qos.logback.core.ConsoleAppender"> <layout class="ch.qos.logback.classic.PatternLayout"> <Pattern> %black(%d{ISO8601}) %highlight(${LOG_LEVEL_PATTERN:-%5p}) [%blue(%t)] %yellow(%C{1.}): %msg%n%throwable </Pattern> </layout> </appender>
4、然后我们在入口类中添加@EnableDiscoveryClient注解,开启服务的注册与发现。并且注册RestTemplate,用于Ribbon服务远程调用:
@SpringBootApplication @EnableDiscoveryClient public class DemoApplication { @Bean @LoadBalanced RestTemplate restTemplate() { return new RestTemplate(); } public static void main(String[] args) { SpringApplication.run(DemoApplication.class, args); } }
5、最后编写REST接口:
@RestController @RequestMapping("hello") public class HelloController { private Logger logger = LoggerFactory.getLogger(this.getClass()); @Autowired private RestTemplate restTemplate; @GetMapping public String hello() { logger.info("调用server-provider1的hello接口"); return this.restTemplate.getForEntity("http://server-provider2/hello", String.class).getBody(); } }
在hello接口中,我们通过RestTemplate远程调用了server-provider2的hello接口。
- 创建Server-Provider2
1、新建一个新建一个Spring Boot工程,artifactId为Server-Provider2,依赖和Server-Provider1相同,logback-spring.xml和Server-Provider1相同。
2、在application.yml中添加如下配置:
spring: application: name: server-provider2 server: port: 9001 eureka: client: serviceUrl: defaultZone: http://mrbird:123456@peer1:8080/eureka/,http://mrbird:123456@peer2:8081/eureka/
3、在入口类中添加@EnableDiscoveryClient注解,开启服务注册与发现,跟Server-Provider1相同。
4、最后编写一个REST接口,供Server-Provider1调用:
@RestController @RequestMapping("hello") public class HelloController { private Logger logger = LoggerFactory.getLogger(this.getClass()); @GetMapping public String hello() { logger.info("调用server-provider2的hello接口"); return "hello world"; } }
至此,Server-Provider2也搭建完了。
- 测试Spring Cloud Sleuth
启动8080和8081Eureka-Server集群,然后分别启动Server-Provider1和Server-Provider2。访问http://localhost:8080/查看服务是否都启动成功:

可见服务都启动成功了,我们往Server-provider1发送http://localhost:9000/hello请求,
然后观察各自的日志:
Server-Provider1:
2018-06-25 10:13:40.921 INFO [server-provider1,939ca3c1d060ed40,939ca3c1d060ed40,false] 12516 --- [nio-9000-exec-6] c.e.demo.controller.HelloController : 调用server-provider1的hello接口
Server-Provider2:
2018-06-25 10:13:40.931 INFO [server-provider2,939ca3c1d060ed40,3f31114e88154074,false] 6500 --- [nio-9001-exec-3] c.e.demo.controller.HelloController : 调用server-provider2的hello接口
可以看到,日志里出现了[server-provider2,939ca3c1d060ed40,3f31114e88154074,false]信息,这些信息由Spring Cloud Sleuth生成,用于跟踪微服务请求链路。
这些信息包含了4个部分的值,它们的含义如下:
-
server-provider2微服务的名称,与spring.application.name对应; -
939ca3c1d060ed40称为Trace ID,在一条完整的请求链路中,这个值是固定的。观察上面的日志即可证实这一点; -
3f31114e88154074称为Span ID,它表示一个基本的工作单元; -
false表示是否要将该信息输出到Zipkin等服务中来收集和展示,这里我们还没有集成Zipkin,所以为false。
1.2 Sleuth 详细介绍
通过 Spring Cloud 集成 Sleuth 的示例,对 Sleuth 有了个基本的了解。
- 将 Span ID 和 Trace ID 添加到 Slf4J MDC 中,这样可以在日志聚合器中根据 Span ID 和 Trace ID 提取日志。
- 提供对常见分布式跟踪数据模型的抽象:traces(跟踪),spans(形成DAG(有向无环图)),注释,key-value注释。 松散地基于HTrace,但兼容Zipkin(Dapper)。
- Sleuth 常见的入口和出口点来自 Spring 应用(Servlet 过滤器、Rest Template、Scheduled Actions、消息通道、Zuul Filter、Feign Client)。
- 如果 spring-cloud-sleuth-zipkin 可用,Sleuth 将通过 HTTP 生成并收集与 Zipkin 兼容的跟踪。默认情况下,将跟踪数据发送到 localhost(端口:9411)上的 Zipkin 收集服务应用,可使用 spring.zipkin.baseUrl 修改服务器地址。
- Span:基本的工作单元。一个 RPC 调用就是一个新的 Span。Spand 还有此其他数据,如描述、时间戳事件、key-value 注释(tags)、Spand ID、进程ID(通常为 IP 地址)。
- Trace:整个请求的唯一ID,标识完速请求链路,是一组树形结构的 Span。
- Annotation:用于及时记录存在的事件。
- cs:客户端发送。客户端发起一个请求。此注释标识 HTTP 请求的开始,也是 Span 的起点,。
- sr:服务器收到,服务端接收到请求并准备开始处理。sr 时戳 - cs 时戳 = 网络延迟。
- ss:服务端发送。在完成请求处理时(当准备发送响应到客户端时)注释。ss 时戳 - sr 时戳 = 服务端处理请求耗时。
- cr:客户端收到。Span 的结束。客户端成功收到服务端的响应,标识这个 HTTP 请求的结束。cf 时戳 - cs 时戳 = 客户端发送出请求到收到服务端响应的总耗时。
下图展示了Span和Trace在系统中的联系:
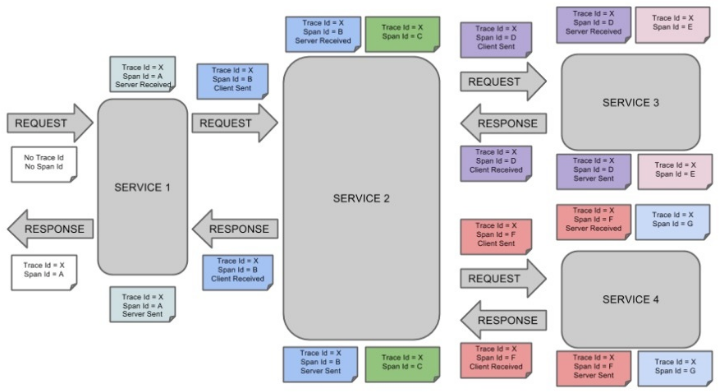
标记的每种颜色表示一个span(有七个span — 从A到G),请考虑以下标记:
Trace Id = X Span Id = D Client Sent
此标记表示当前span的Trace Id设置为X,Span Id设置为D,此外,还发生了Client Sent事件。
下图显示了span的父—子关系:

2. Zipkin
2.1 Zipkin概述
Zipkin 是一个分布式跟踪系统,用于收集、管理和查找跟踪数据。 它可以把分布式链路调用的顺序串起来,并计算链路中每个 RPC 调用的耗时,可以很直观的看出在整个调用链路中延迟问题。
Zipkin Server 提供了 UI 操作,可以非常方便地查看和搜索跟踪数据,直观的查看到链调用依赖关系。
该项目包括一个无依赖库和一个 spring-boot 服务器。 存储支持包括内存,JDBC(mysql),Cassandra 和 Elasticsearch。
在没有使用外部存储时,则默认使用内存存储数据,内存数据是有限且不可持久化的,所以建议使用外部存储,因日志数据通常很大,为了搜索日志的效率,所以建议使用 Elasticsearch。
apache/incubator-zipkin > Github, Zipkin 支持 Elasticsearch 存储的插件:storage-elasticsearch-http,zipkin-server,Zipkin 官网。
2.2 Zipkin整体架构
Zipkin 整体架构如下图所示,分成三个部分:
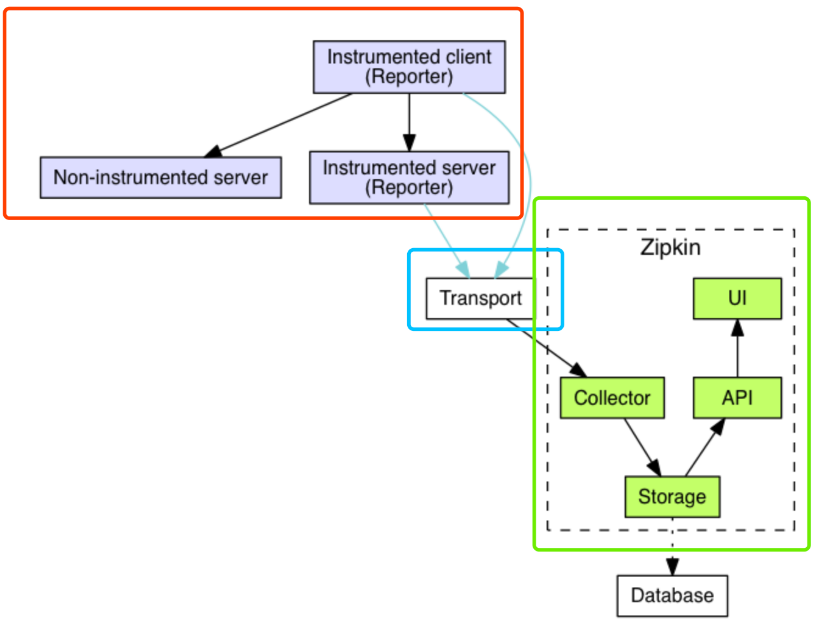
- 【红框】Zipkin Tracer :负责从应用中,收集分布式场景下的调用链路数据,发送给 Zipkin Server 服务。
- 【蓝框】Transport :链路数据的传输方式,目前有 HTTP、MQ 等等多种方式。
- 【绿框】Zipkin Server :负责接收 Tracer 发送的 Tracing 数据信息,将其聚合处理并进行存储,后提供查询功能。之后,用户可通过 Web UI 方便获得服务延迟、调用链路、系统依赖等等。
Zipkin 的基础架构由 4 个核心组件构成:
- Collector:收集器组件,处理从外部系统发过来的跟踪信息,将这些信息转换为 Zipkin 内部处理的 Span 格式,以支持后续的存储、分析、展示等功能。
- Stroage:存储组件,主要处理收集器收到的跟踪信息,默认存储在内存中,也可通过 ES 或 JDBC 来存储。
- Restful API:API 组件,提供外部访问接口。
- Web UI:UI组件,基于 API 组件实现的 Web 控制台,用户可以很方便直观地查询、搜索和分析跟踪信息。
2.3 Zipkin数据采集
项目应用作为 Zipkin 客户端,发跟踪数据(主要是日志数据)发送到 Zipkin Server,并在 Zipkin 查看。
- HTTP 方式发送
SpringCloud Sleuth 默认采用 Http 方式将 span 信息传输给 Zipkin。
依赖,pom.xml:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
配置,application.properties:
# Zipkin Server 地址 spring.zipkin.base-url=http://localhost:8020 # Zipkin 采样比例,默认是 0.1 spring.sleuth.sampler.probability=1 # 发送方式(默认值) spring.zipkin.sender.type=web
Zipkin 发送数据与接口调用次数默认比例为 0.1,即可能调用了 10 次接口,但 Zipkin 中只有一条数据。
这样设置,是因为在高并发下,如果所有数据都采集,大量的请求调用会产生海量的日志数据,特别是对于 HTTP 方式去发送采集的数据,收集过多的跟踪信息会对整个分布式系统的性能造成一定的影响。
这个比例可通过 spring.sleuth.sampler.probability 修改,为 1 的话表示全部发送。
虽然已有采样比例来收集数据,但 HTTP 发送方式仍对性能有影响,特别是在高并发性况下,如果 Zipkin 服务器重启或挂掉,这期间的采集数据就会丢失。
可以采用消息中间件的方式,异步通信,提高发送性能,数据也不会丢失。支持的MQ有RabbitMQ和Kafka。以下是使用Kafka的示例:
依赖,pom.xml:
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.kafka</groupId>
<artifactId>spring-kafka</artifactId>
</dependency>
配置,application.properties:
spring.zipkin.base-url=http://172.16.10.62:9411/ spring.sleuth.sampler.probability=1 spring.zipkin.sender.type=kafka spring.zipkin.kafka.topic=zipkin spring.kafka.bootstrap-servers=172.16.10.91:9092,172.16.10.92:9092,172.16.10.93:9092
2.4 Zipkin-Server 搭建
在官网 https://zipkin.io/pages/quickstart.html 提供了三种安装方式,我们这里采用官方已经构建好的 jar 包。
- 下载 jar 包
# 创建目录 $ mkdir -p /opt/zipkin $ cd /opt/zipkin # 下载 $ curl -sSL https://zipkin.io/quickstart.sh | bash -s
- 编写启动脚本
vim /opt/zipkin/start-zipkin.sh
#!/bin/bash
nohup java
-DKAFKA_BOOTSTRAP_SERVERS=172.16.10.91:9092,172.16.10.92:9092,172.16.10.93:9092
-DSTORAGE_TYPE=elasticsearch
-DES_HOSTS=http://172.16.10.75:9200
-jar /opt/zipkin/zipkin.jar >> /opt/zipkin/zipkin.log 2>&1 &
参数介绍:
-
- KAFKA_BOOTSTRAP_SERVERS:kafka broker地址
-
- STORAGE_TYPE:数据存储类型,这里我们选择elasticsearch
-
- ES_HOSTS :elasticsearch的地址
- 赋予脚本可执行权限
chmod +x /opt/zipkin/start-zipkin.sh
- 执行脚本启动服务
/opt/zipkin/start-zipkin.sh
查看 /opt/zipkin/zipkin.log 日志文件,如果文末出现如下日志,说明启动成功:
- 简单使用
使用浏览器,访问 http://127.0.0.1:9411/ 地址,查看 Zipkin UI 界面。如下图所示:
2.5 Zipkin-Dependencies 搭建
在使用 Elasticsearch、Cassandra、MySQL 作为存储器后,需要使用 zipkin-dependencies,计算服务之间的依赖关系。不然,我们在 Zipkin UI 的「依赖」菜单,是看不到服务之间的依赖关系图。
- 下载 jar 包
# 创建目录 $ mkdir -p /opt/zipkin $ cd /opt/zipkin # 下载 $ curl -sSL https://zipkin.io/quickstart.sh | bash -s io.zipkin.dependencies:zipkin-dependencies:LATEST zipkin-dependencies.jar
可能下载会比较慢,请耐心等待.
- 编写启动脚本
vim /opt/zipkin/start-zipkin-dependencies.sh
#!/bin/bash
source /etc/profile
STORAGE_TYPE=elasticsearch ES_HOSTS=http://172.16.10.75:9200 nohup java -jar /opt/zipkin/zipkin-dependencies.jar >> /opt/zipkin/zipkin-dependencies.log 2>&1 &
参数介绍:
-
- STORAGE_TYPE:存储类型
- ES_HOSTS:若参数类型选择了es,则配置es的集群地址
- 赋予脚本可执行权限
chmod +x /opt/zipkin/start-zipkin-dependencies.sh
- 执行脚本启动服务
/opt/zipkin/start-zipkin-dependencies.sh
每执行一次,则会对历史数据计算一次结果服务之间的依赖关系的计算。查看 /opt/zipkin/zipkin-dependencies.log 输出结尾日志如下,代表执行成功:

因为 zipkin-dependencies.jar 实际是个 Spark Job,所以每次任务执行完后,JVM 进程就结束了。
我们需要参考 Running in a Spark cluster 文档,将 zipkin-dependencies.jar 部署到 Spark 集群中执行。
- crontab定时调用脚本
不过考虑到可能我们没有 Spark 服务,所以我们也可以考虑使用 Linux 自带的 crontab 定时任务,配置如下,每分钟执行一次:
crontab -e
* * * * * /opt/zipkin/start-zipkin-dependencies.sh
3. 集成Zipkin(Dubbo 应用)示例
因为springcloud的微服务框架是基于http构建的,所以sleuth默认是只支持http。在2.0版本中提供了对dubbo的支持,其实看一下源码就知道,就只是一个DubboFilter。
zipkin本身支持多种collector和storage,默认采用异步http的collector,存储默认在内存中。考虑到对应用本身的性能影响,我们采用kafka来做collector,最大程度的解耦以及减少性能影响。
存储选用es,用mysql的话当数据量较大时会影响zipkin-server的查询速度。
搭建一个 Spring Cloud Sleuth 对 Dubbo 的远程 RPC 调用的链路追踪。总共有3个应用:
该链路通过如下插件实现收集:
友情提示:Brave 一共提供了两个插件,其中本文使用的 brave-instrumentation-dubbo 适用于 Dubbo 2.7.X 版本,而另外的 brave-instrumentation-dubbo-rpc 适用于 Dubbo 2.6.X 版本。
3.1 搭建 API 项目
创建项目,服务接口,定义 Dubbo Service API 接口,提供给消费者使用。
- UserService
创建 UserService 接口,定义用户服务 RPC Service 接口。代码如下:
public interface UserService { /** * 根据指定用户编号,获得用户信息 * * @param id 用户编号 * @return 用户信息 */ String get(Integer id); }
3.2 搭建服务提供者项目
创建项目,服务提供者,实现 API 项目定义的 Dubbo Service API 接口,提供相应的服务。
- 引入依赖
创建 pom.xml 文件中,引入依赖。
<?xml version="1.0" encoding="UTF-8"?> <project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"> <parent> <artifactId>labx-13-sc-sleuth-dubbo</artifactId> <groupId>cn.iocoder.springboot.labs</groupId> <version>1.0-SNAPSHOT</version> </parent> <modelVersion>4.0.0</modelVersion> <artifactId>labx-13-sc-sleuth-dubbo-consumer</artifactId> <properties> <maven.compiler.target>1.8</maven.compiler.target> <maven.compiler.source>1.8</maven.compiler.source> <spring.boot.version>2.2.4.RELEASE</spring.boot.version> <spring.cloud.version>Hoxton.SR1</spring.cloud.version> <spring.cloud.alibaba.version>2.2.0.RELEASE</spring.cloud.alibaba.version> </properties> <!-- 引入 Spring Boot、Spring Cloud、Spring Cloud Alibaba 三者 BOM 文件,进行依赖版本的管理,防止不兼容。 在 https://dwz.cn/mcLIfNKt 文章中,Spring Cloud Alibaba 开发团队推荐了三者的依赖关系 --> <dependencyManagement> <dependencies> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-parent</artifactId> <version>${spring.boot.version}</version> <type>pom</type> <scope>import</scope> </dependency> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-dependencies</artifactId> <version>${spring.cloud.version}</version> <type>pom</type> <scope>import</scope> </dependency> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-alibaba-dependencies</artifactId> <version>${spring.cloud.alibaba.version}</version> <type>pom</type> <scope>import</scope> </dependency> </dependencies> </dependencyManagement> <dependencies> <!-- 引入定义的 Dubbo API 接口 --> <dependency> <groupId>cn.iocoder.springboot.labs</groupId> <artifactId>labx-13-sc-sleuth-dubbo-api</artifactId> <version>1.0-SNAPSHOT</version> </dependency> <!-- 引入 SpringMVC 相关依赖,并实现对其的自动配置 --> <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-web</artifactId> </dependency> <!-- 引入 Spring Cloud Alibaba Nacos Discovery 相关依赖,将 Nacos 作为注册中心,并实现对其的自动配置 --> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-alibaba-nacos-discovery</artifactId> </dependency> <!-- 引入 Spring Cloud Alibaba Dubbo 相关依赖,实现呢 Dubbo 进行远程调用,并实现对其的自动配置 --> <dependency> <groupId>com.alibaba.cloud</groupId> <artifactId>spring-cloud-starter-dubbo</artifactId> </dependency> <!-- 引入 Spring Cloud Sleuth + Zipkin 相关依赖,实现对它们的自动配置,从而实现链路追踪 --> <dependency> <groupId>org.springframework.cloud</groupId> <artifactId>spring-cloud-starter-zipkin</artifactId> </dependency> <!-- Brave 针对 Dubbo 的插件,实现链路追踪 --> <dependency> <groupId>io.zipkin.brave</groupId> <artifactId>brave-instrumentation-dubbo</artifactId> <version>5.10.1</version> </dependency> </dependencies> </project>
重点是引入 brave-instrumentation-dubbo 依赖,实现对 Dubbo 的链路追踪。
- 配置文件
创建 application.yml 配置文件,添加相应配置项如下:
spring: application: name: demo-provider cloud: # Nacos 作为注册中心的配置项 nacos: discovery: server-addr: 127.0.0.1:8848 # Nacos 服务器地址 # Zipkin 配置项,对应 ZipkinProperties 类 zipkin: base-url: http://127.0.0.1:9411 # Zipkin 服务的地址 # Dubbo 配置项,对应 DubboConfigurationProperties 类 dubbo: scan: base-packages: cn.iocoder.springcloud.labx13.providerdemo.service # 指定 Dubbo 服务实现类的扫描基准包 # Dubbo 服务暴露的协议配置,对应 ProtocolConfig Map protocols: dubbo: name: dubbo # 协议名称 port: -1 # 协议端口,-1 表示自增端口,从 20880 开始 # Dubbo 服务注册中心配置,对应 RegistryConfig 类 registry: address: spring-cloud://127.0.0.1:8848 # 指定 Dubbo 服务注册中心的地址 # Dubbo 服务提供者的配置,对应 ProviderConfig 类 provider: filter: tracing # Spring Cloud Alibaba Dubbo 专属配置项,对应 DubboCloudProperties 类 cloud: subscribed-services: '' # 设置订阅的应用列表,默认为 * 订阅所有应用
重点是设置 dubbo.provider.filter 配置项为 tracing,使用 brave-instrumentation-dubbo 提供的 TracingFilter 过滤器,实现对 Dubbo 的链路追踪
- UserServiceImpl
创建 UserServiceImpl 类,实现 UserService 接口,用户服务具体实现类。代码如下:
@org.apache.dubbo.config.annotation.Service(protocol = "dubbo", version = "1.0.0") public class UserServiceImpl implements UserService { @Override public String get(Integer id) { return "user:" + id; } }
- ProviderApplication
创建 ProviderApplication 类,服务提供者的启动类。代码如下:
@SpringBootApplication public class ProviderApplication { public static void main(String[] args) { SpringApplication.run(ProviderApplication.class); } }
3.3 搭建服务消费者项目
创建项目,服务消费者,会调用 服务提供者 项目提供的 User Service 服务。
- 引入依赖
创建 pom.xml 文件中,引入依赖。和「服务提供者项目 引入依赖」基本是一致的。
- 配置文件
创建 application.yml 配置文件,添加相应配置项如下:
spring: application: name: demo-consumer cloud: # Nacos 作为注册中心的配置项 nacos: discovery: server-addr: 127.0.0.1:8848 # Zipkin 配置项,对应 ZipkinProperties 类 zipkin: base-url: http://127.0.0.1:9411 # Zipkin 服务的地址 # Dubbo 配置项,对应 DubboConfigurationProperties 类 dubbo: # Dubbo 服务注册中心配置,对应 RegistryConfig 类 registry: address: spring-cloud://127.0.0.1:8848 # 指定 Dubbo 服务注册中心的地址 # Dubbo 服务提供者的配置,对应 ConsumerConfig 类 consumer: filter: tracing # Spring Cloud Alibaba Dubbo 专属配置项,对应 DubboCloudProperties 类 cloud: subscribed-services: demo-provider # 设置订阅的应用列表,默认为 * 订阅所有应用。
重点是设置 dubbo.consumer.filter 配置项为 tracing,使用 brave-instrumentation-dubbo 提供的 TracingFilter 过滤器,实现对 Dubbo 的链路追踪。
- UserController
创建 UserController 类,提供调用 UserService 服务的 HTTP 接口。代码如下:
@RestController @RequestMapping("/user") public class UserController { @Reference(protocol = "dubbo", version = "1.0.0") private UserService userService; @GetMapping("/get") public String get(@RequestParam("id") Integer id) { return userService.get(id); } }
- ConsumerApplication
创建 ConsumerApplication 类,服务消费者的启动类。代码如下:
@SpringBootApplication public class ConsumerApplication { public static void main(String[] args) { SpringApplication.run(ConsumerApplication.class); } }
3.4 简单测试
使用 ProviderApplication 启动服务提供者,使用 ConsumerApplication 启动服务消费者。
① 首先,使用 curl http://127.0.0.1:8080/user/get?id=1 命令,使用 Dubbo 调用 user-service 服务。因为,我们要追踪下该链路。
② 然后,继续使用浏览器,打开 http://127.0.0.1:9411/ 地址,查看链路数据。点击「查找」按钮,便可看到刚才我们调用接口的链路数据。如下图所示:
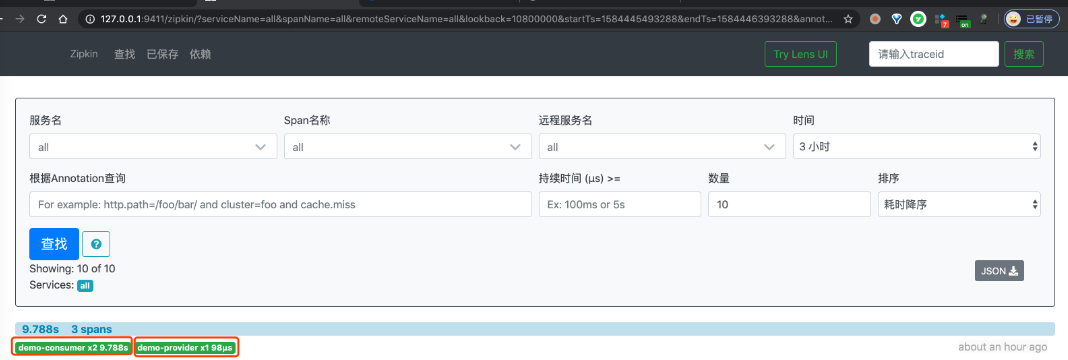
一条链路经过 demo-consumer 和 demo-provider 两个服务,一共有三个 Span。
③ 之后,我们点击该链路数据,可以看到一个 Trace 明细。如下图所示:
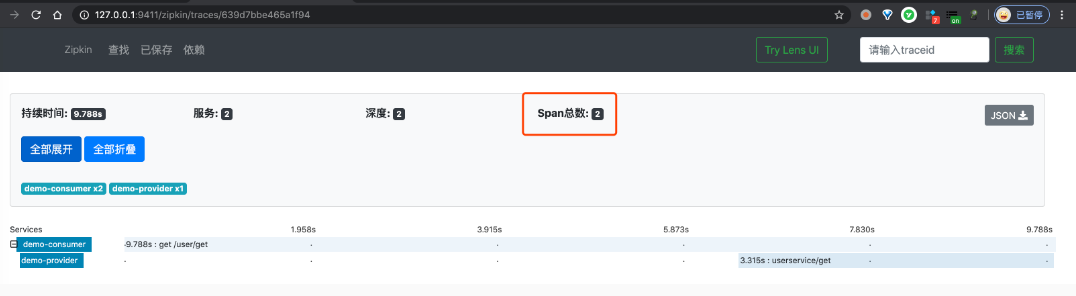
引用: