前言
在开发过程中,人人都会用到排序,每种编程语言也会提供排序函数,可是编程语言的排序函数运用环境复杂,必须得达到最大程度的兼容。我们得怎么实现一种通用的,高效的排序函数呢?
正文
1.最通用的排序算法
如下图所示:
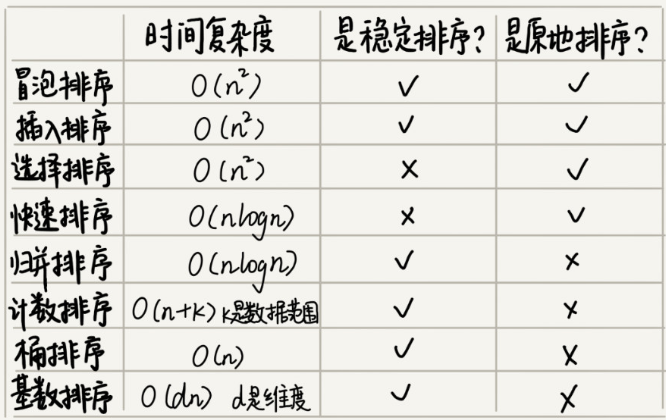
在我们选取的排序函数中,O(n2)时间复杂度适合小规模的排序,O(nlogn)时间复杂度适合大规模的排序,为了兼顾任意规模,我们选取时间复杂为O(nlogn)的算法,如:归并,快排,堆排序。
归并排序,时间复杂度符合要求,可是他不属于原地排序算法,空间复杂度太大,排序1G的数据就需要占用2G的空间
2.怎么优化快速排序?
快速排序的时间复杂度为O(nlogn),但是在最坏的情况时,我们每次选取的分区结点都选择最后一个数据时,时间复杂都会变为0(n2),那么最好的分区点就是:被分区点分开的两个分区中,数据数量差不多。
刚好有两种简单常用的分区算法来优化:
1.三数取中法
我们从区间的首尾中,分别取出一个数据,然后对比大小,取中间值作为分区点。
但是这里有个弊端:当数据规模太大时,三数取中显然就不够了,需要五数取中,甚至十数取中法。
2.随机发
每次从区间中,选取一个元素作为分区点,这种方法并不能保证每次分区点都非常好,但是从概率学的角度来看,不太可能会出现每次分区点都选的很差的情况,所以这样分区是比较好的。
还有很多的分区算法这里就不重点叙述了。有兴趣的,自己学习一下
3.Java的Sort函数
在各大编程语言中都提供了排序函数,在Java中的sort你阅读源码会发现,
在JDK1.7版本中Arrays.sort()方法是根据传出参数的长度的大小来判断用哪种排序方法,一种是针对基本类型的数据,主要是有归并排序、快速排序、插入排序、计数排序,而另一种则是针对对象类型的排序,改进的归并排序--合并排序
合并排序是稳定的并且合并排序比较的次数比快排,合并排序的时间复杂度是n*logn, 快速排序的平均时间复杂度也是n*logn,但是合并排序的需要额外的n个引用的空间。排序100M的数据,需要额外100M的空间。
函数中关于阈值的源码如下:
/** * The maximum number of runs in merge sort. 合并排序的最大运行次数。 */ private static final int MAX_RUN_COUNT = 67; /** * The maximum length of run in merge sort. * 归并排序中的最大值,归并排序是稳定的,时间复 杂度为O(nlogn) */ private static final int MAX_RUN_LENGTH = 33; /** * If the length of an array to be sorted is less than this * constant, Quicksort is used in preference to merge sort. * 快速排序中的最大值,快速排序是不稳定的,时间复杂度为O(nlogn),最坏情况下是O(n^2) */ private static final int QUICKSORT_THRESHOLD = 286; /** * If the length of an array to be sorted is less than this * constant, insertion sort is used in preference to Quicksort. 如果要排序的数组的长度小于此值 常量,插入排序优先于Quicksort使用。 */ private static final int INSERTION_SORT_THRESHOLD = 47; /** * If the length of a byte array to be sorted is greater than this * constant, counting sort is used in preference to insertion sort. 如果要排序的字节数组的长度大于此值 常量,计数排序优先于插入排序。 */ private static final int COUNTING_SORT_THRESHOLD_FOR_BYTE = 29; /** * If the length of a short or char array to be sorted is greater * than this constant, counting sort is used in preference to Quicksort. 如果要排序的short或char数组的长度更大 比这个常量,计数排序优先于Quicksort使用。 */ private static final int COUNTING_SORT_THRESHOLD_FOR_SHORT_OR_CHAR = 3200;
当排序的数据规模较少时:插入排序优于快速排序
在快排时,其中有一段是:当数组大小 7<size<=40时,取首、中、末三个元素中间大小的元素作为划分元。采用的优化方案也是三数取中法。
具体的大家可以阅读源码;
4、c语言中qsort()函数
它是一种基于快速排序,归并排序,插入排序的排序函数
当排序的数据规模很小时,如1k、2k这种我们都是用的归并排序,虽然归并排序需要额外的空间,但是这些小规模的数据用递归是速度最快的,而且空间消耗我们也负担得起,这里就很好的使用空间交换时间的技巧。
当排序的数据规模很大时,源码中采用的就是优化过的快排,而且优化的方法就是“三数取中法”。在使用快排中,当排序的区间中,元素的个数小于等于4时,qsort()就会退化为插入排序,不再使用递归来做快速排序,小规模数据面前O(n2)时间复杂度并不一定比O(nlogn)执行时间长。
下图为y=n2的函数
下图网上寻找到的y=nlogn与y=n2在一张图里的图片。你会发现O(n2) 比 O(nlogn) 增涨趋势更猛烈,所以对于小数据量的排序,我们使用比较简单,不需要递归的插入排序

相关文章
以上内容为个人的学习笔记,仅作为学习交流之用。

欢迎大家关注公众号,不定时干货,只做有价值的输出