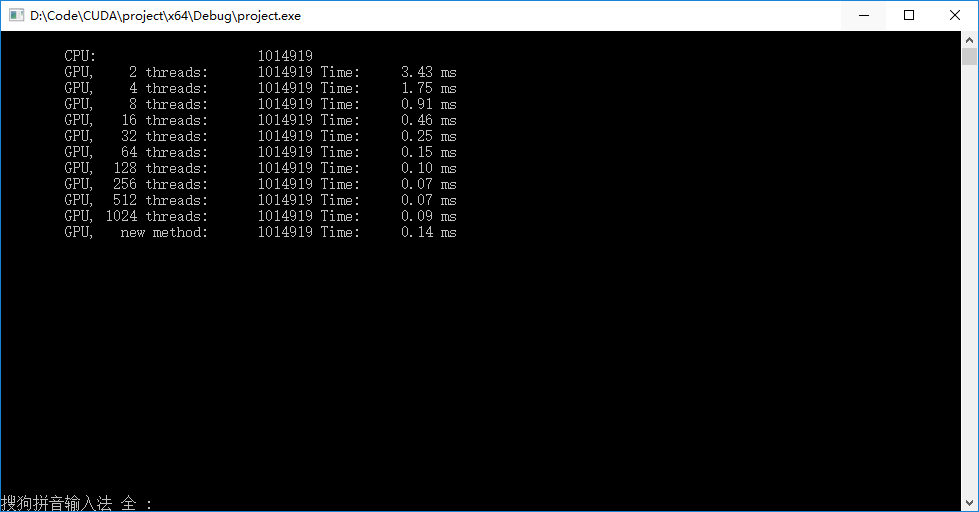
▶ 采用两种方法计算任意长度的数组规约加法。第一种是将原数组收缩到一个固定长度的共享内存数组中,再利用二分规约计算求和,这里测试了固定长度分别取2,4,8……1024的情形;第二种方法是将原数组分段,每段使用各自的共享内存进行二分规约,结果汇总后再次分段,规约,直至数组长度减小到1,输出结果。
● 代码
1 #include <stdio.h> 2 #include <stdlib.h> 3 #include <windows.h> 4 #include <time.h> 5 #include <math.h> 6 #include "cuda_runtime.h" 7 #include "device_launch_parameters.h" 8 9 #define ARRAY_SIZE (1024 * 7 + 119) 10 #define WIDTH 512 11 #define SEED 1 //(unsigned int)clock() 12 #define CEIL(x,y) (int)(( x - 1 ) / y + 1) 13 #define MIN(x,y) ((x)<(y)?(x):(y)) 14 //#define RESIZE(x) MIN(WIDTH, 1 << (int)ceil(log(x) / log(2))) 15 16 typedef int format; // int or float 17 18 void checkCudaError(cudaError input) 19 { 20 if (input != cudaSuccess) 21 { 22 printf(" find a cudaError!"); 23 exit(1); 24 } 25 return; 26 } 27 28 // 不超过1024个元素的,任意个元素的规约加法。调用时指定与原数组长度相同大小的共享内存数组 29 __global__ void add_1(const format *in, format *out) 30 { 31 extern __shared__ format sdata[]; 32 sdata[threadIdx.x] = in[threadIdx.x]; 33 34 for (int s = blockDim.x; s > 0; s = (s - 1) / 2 + 1) 35 { 36 sdata[threadIdx.x] += (threadIdx.x >= s / 2) ? 0 : sdata[threadIdx.x + (s - 1) / 2 + 1];// 考虑加数是否为奇数个,后半线程都加 0 37 __syncthreads(); 38 } 39 40 if (threadIdx.x == 0) 41 *out = sdata[0]; 42 return; 43 } 44 45 // 将原数组收缩到blockDim.x的尺度上进行二分规约。调用时指定与线程数相同大小的共享内存数组 46 __global__ void add_2(const format *in, format *out, int size)// size为原数组大小,可以远大于blockDim.x 47 { 48 extern __shared__ format sdata[]; 49 sdata[threadIdx.x] = (threadIdx.x < size) ? in[threadIdx.x] : 0; 50 51 // 收尾操作,在另外两个规约加法函数中没有的 52 for (int id = threadIdx.x + blockDim.x; id < size; id += blockDim.x) 53 sdata[threadIdx.x] += in[id]; 54 __syncthreads(); 55 56 for (int jump = blockDim.x / 2; jump > 0; jump /= 2) 57 { 58 sdata[threadIdx.x] += (threadIdx.x >= jump) ? 0 : sdata[threadIdx.x + jump]; 59 __syncthreads(); 60 } 61 __syncthreads(); 62 63 if (threadIdx.x == 0) 64 *out = sdata[0]; 65 return; 66 } 67 // 限制元素个数为2的整数次幂的规约加法。调用时指定共享内存数组大小为 1 << ((log(size) - 1) / 2 + 1) 68 __global__ void add_simple(const format *in, format *out, int size) 69 { 70 extern __shared__ format sdata[]; 71 sdata[threadIdx.x] = (blockIdx.x * blockDim.x + threadIdx.x < size) ? in[blockIdx.x * blockDim.x + threadIdx.x] : 0; 72 73 for (int jump = blockDim.x / 2; jump > 0; jump /= 2) 74 { 75 sdata[threadIdx.x] += (threadIdx.x < jump) ? sdata[threadIdx.x + jump] : 0; 76 __syncthreads(); 77 } 78 __syncthreads(); 79 80 if (threadIdx.x == 0) 81 out[blockIdx.x] = sdata[0]; 82 return; 83 } 84 85 int main() 86 { 87 int i, j, leftLength; 88 format h_in[ARRAY_SIZE], h_out[10 + 1], cpu_sum; 89 format *d_in, *d_out, *d_temp1, *d_temp2; 90 cudaEvent_t start, stop; 91 float elapsedTime[10 + 1]; 92 cudaEventCreate(&start); 93 cudaEventCreate(&stop); 94 95 checkCudaError(cudaMalloc((void **)&d_in, sizeof(format) * ARRAY_SIZE)); 96 checkCudaError(cudaMalloc((void **)&d_out, sizeof(format))); 97 checkCudaError(cudaMalloc((void **)&d_temp1, sizeof(format) * CEIL(ARRAY_SIZE, WIDTH))); 98 checkCudaError(cudaMalloc((void **)&d_temp2, sizeof(format) * CEIL(CEIL(ARRAY_SIZE, WIDTH), WIDTH))); 99 100 srand(SEED); 101 for (i = 0, cpu_sum = 0; i < ARRAY_SIZE; i++) 102 { 103 h_in[i] = rand() - RAND_MAX / 2; 104 cpu_sum += h_in[i]; 105 } 106 cudaMemcpy(d_in, h_in, sizeof(format) * ARRAY_SIZE, cudaMemcpyHostToDevice); 107 108 // 方法一 109 for (i = 0; i < 10; i++) 110 { 111 cudaEventRecord(start, 0); 112 add_2 << < 1, 2 << i, sizeof(format) * (2 << i) >> > (d_in, d_out, ARRAY_SIZE); 113 cudaMemcpy(&h_out[i], d_out, sizeof(format), cudaMemcpyDeviceToHost); 114 cudaDeviceSynchronize(); 115 cudaEventRecord(stop, 0); 116 cudaEventSynchronize(stop); 117 cudaEventElapsedTime(&elapsedTime[i], start, stop); 118 } 119 // 方法二 120 cudaEventRecord(start, 0); 121 for (i = 0; i < CEIL(log(ARRAY_SIZE), log(WIDTH)); i++)// 一次循环完成一次迭代,共需要 CEIL(log(ARRAY_SIZE), log(WIDTH))次迭代 122 { 123 if (i == 0)// 首次迭代,将d_in算到d_temp1中去 124 { 125 add_simple << <CEIL(ARRAY_SIZE, WIDTH), WIDTH, sizeof(format) * WIDTH >> > (d_in, d_temp1, ARRAY_SIZE); 126 cudaDeviceSynchronize(); 127 leftLength = ARRAY_SIZE / WIDTH + (bool)(ARRAY_SIZE % WIDTH); 128 } 129 else if (i % 2)// 非首次的偶数次,把d_temp1算到d_temp2中去 130 { 131 add_simple << <CEIL(leftLength, WIDTH), WIDTH, sizeof(format) * WIDTH >> > (d_temp1, d_temp2, WIDTH); 132 cudaDeviceSynchronize(); 133 leftLength = leftLength / WIDTH + (bool)(leftLength % WIDTH); 134 } 135 else// 非首次的奇数次,把d_temp2算到d_temp1中去 136 { 137 add_simple << <CEIL(leftLength, WIDTH), WIDTH, sizeof(format) * WIDTH >> > (d_temp2, d_temp1, WIDTH); 138 cudaDeviceSynchronize(); 139 leftLength = leftLength / WIDTH + (bool)(leftLength % WIDTH); 140 } 141 } 142 if (i % 2)//说明经历了i次规约,i奇结果在d_temp1中,i偶结果在d_temp2中 143 cudaMemcpy(&h_out[10], d_temp1, sizeof(format), cudaMemcpyDeviceToHost); 144 else 145 cudaMemcpy(&h_out[10], d_temp2, sizeof(format), cudaMemcpyDeviceToHost); 146 cudaDeviceSynchronize(); 147 cudaEventRecord(stop, 0); 148 cudaEventSynchronize(stop); 149 cudaEventElapsedTime(&elapsedTime[10], start, stop); 150 151 printf(" CPU: %f", (float)cpu_sum); 152 for (i = 0; i < 10; i++) 153 printf(" GPU, %4d threads: %d Time: %6.2f ms", 2 << i, (int)h_out[i], elapsedTime[i]); 154 printf(" GPU, new method: %d Time: %6.2f ms", (int)h_out[10], elapsedTime[10]); 155 156 cudaFree(d_in); 157 cudaFree(d_out); 158 cudaFree(d_temp1); 159 cudaFree(d_temp2); 160 cudaEventDestroy(start); 161 cudaEventDestroy(stop); 162 163 getchar(); 164 return 0; 165 }
● 输出结果,可见随着一个线程块内的线程数的增大,每次全局内存读取的带宽增大,计算所需迭代次数减小,但共享内存结果的汇总耗时增加,总时间先减小后增大,在blockDim.x在256和512左右接近最优。采用第二种方法在CPU中逻辑较为复杂,没有去的较好的改进。