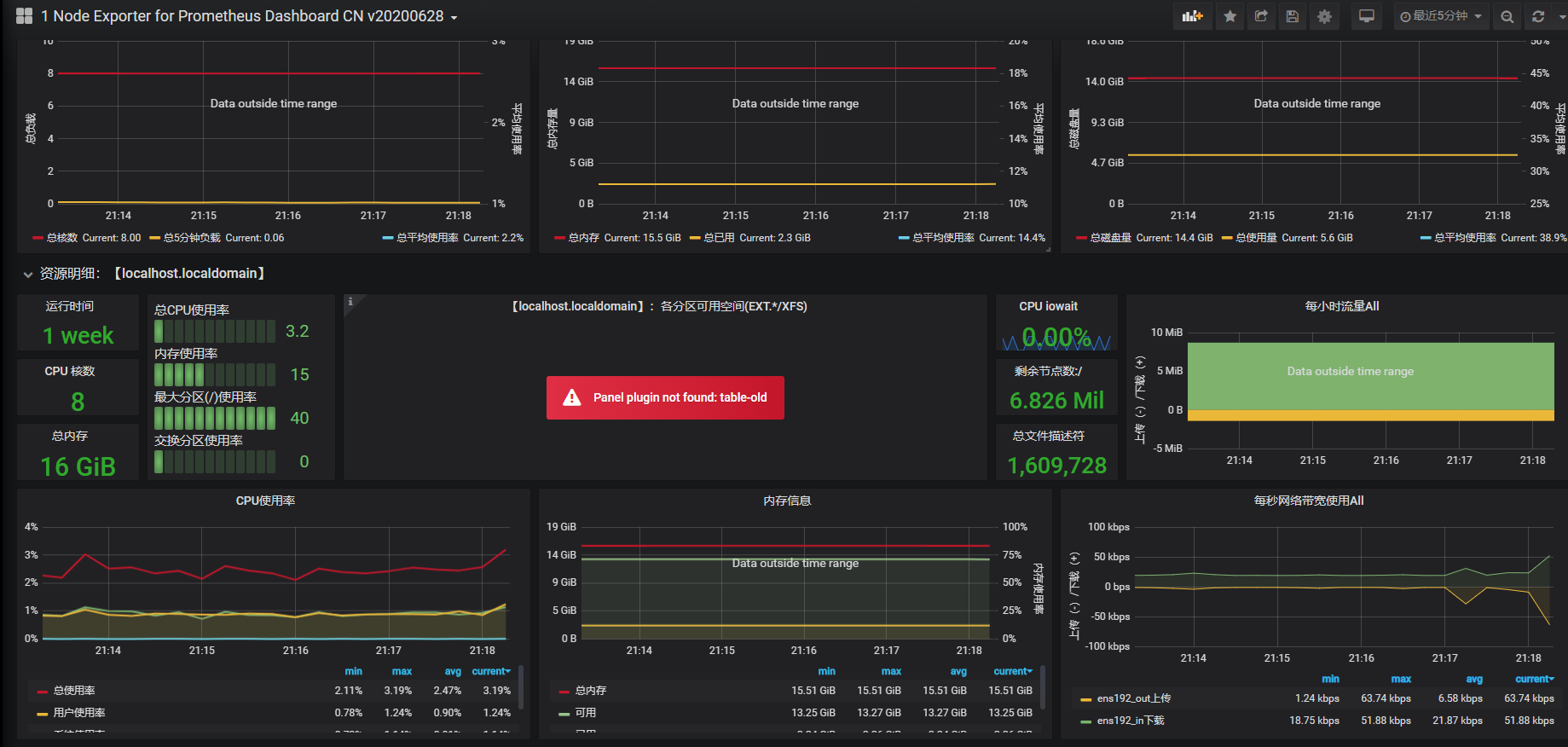
CPU使用率
我们从计算每个CPU模式的每秒速率开始。PromQL有一个名为irate的函数,用于计算距离向量中时间序列的每秒瞬时增长率。让我们在``node_cpu_seconds_total`度量上使用irate函数。在查询框中输入:
irate(node_cpu_seconds_total{job="node"}[5m])
avg(irate(node_cpu_seconds_total{job="node"}[5m])) by (instance)
现在,我们将irate函数封装在avg聚合中,并添加了一个by子句,该子句通过实例标签聚合。这将产生三个新的指标,使用来自所有CPU和所有模式的值来平均主机的CPU使用情况。
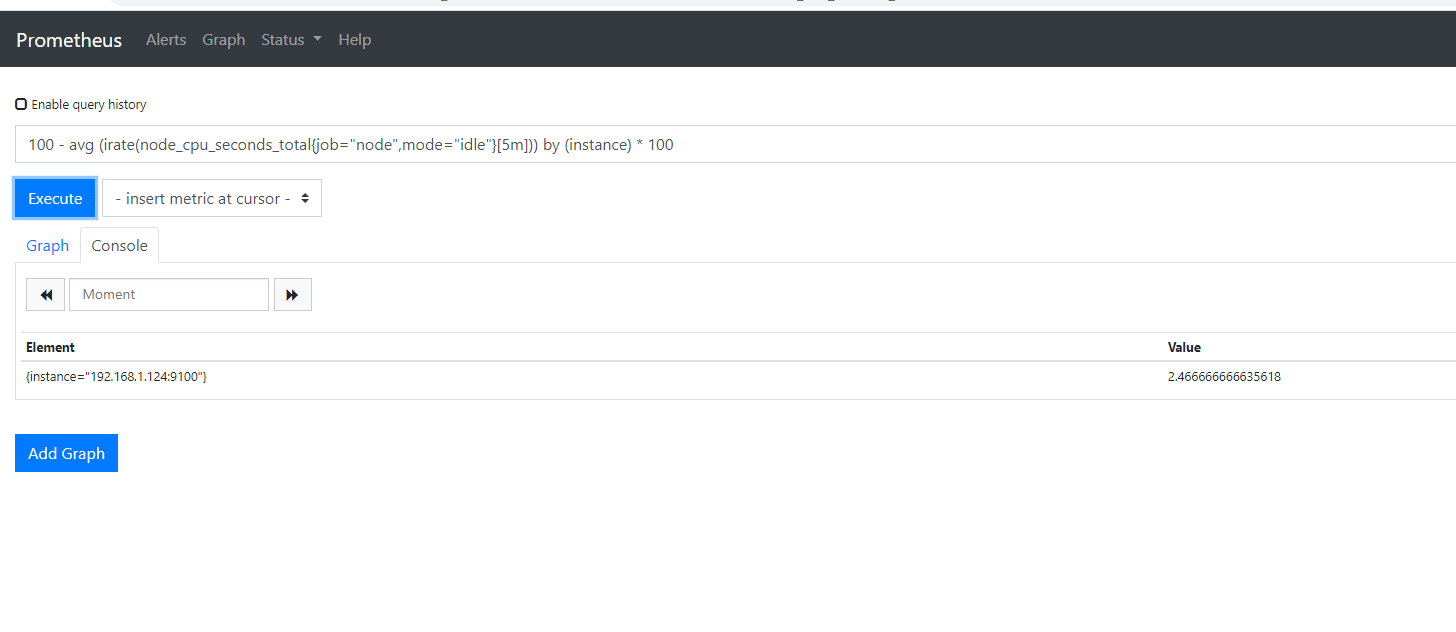
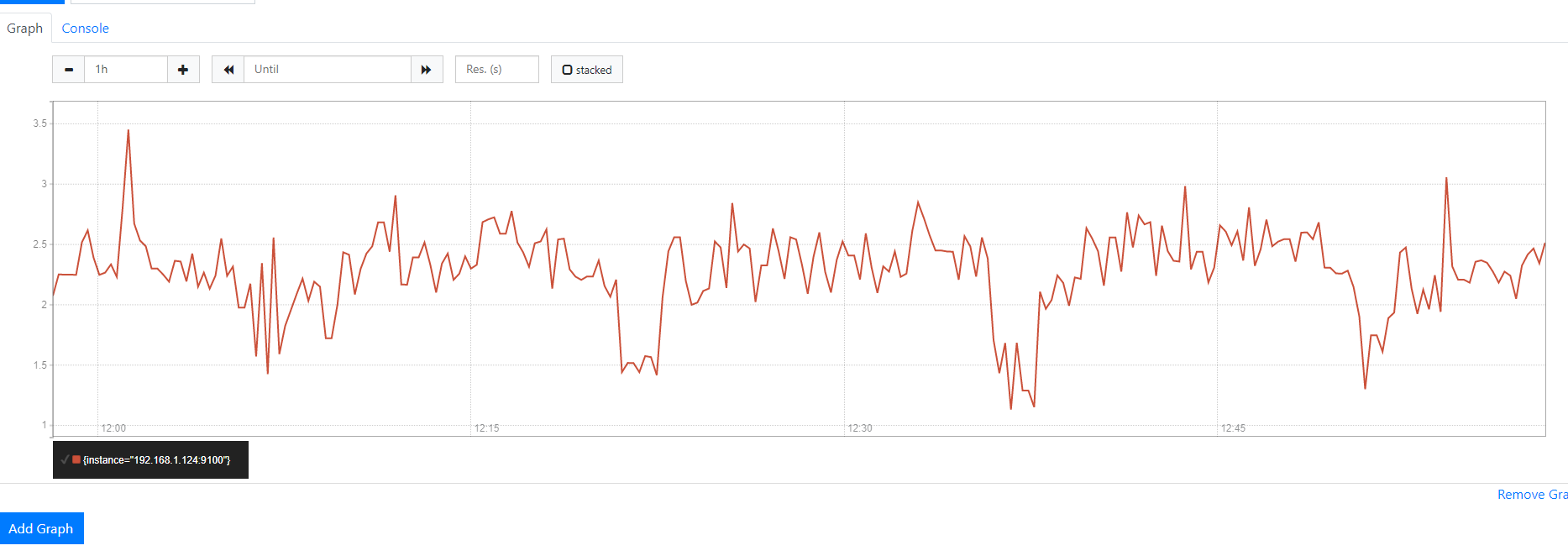
avg (irate(node_cpu_seconds_total{job="node",mode="idle"}[5m])) by (instance) * 100
在这里,我们查询中添加了一个值为idle的mode标签。这只查询空闲数据。我们通过实例求出结果的平均值,并将其乘以100。现在我们在每台主机上都有5分钟内空闲使用的平均百分比。我们可以把这个变成百分数用这个值减去100,就像这样:
100 - avg (irate(node_cpu_seconds_total{job="node",mode="idle"}[5m])) by (instance) * 100
现在我们有三个指标,每个主机一个指标,显示5分钟窗口内使用的平均CPU百分比。
这里就演示最后一个
CPU Saturation(饱和度)
获取主机上CPU饱和的一种方法是跟踪负载平均,即考虑主机上的CPU数量,在一段时间内平均运行队列长度。平均少于cpu的数量通常是正常的;
要查看主机的平均负载,我们可以使用node_load*指标来实现这些功能。它们显示平均负荷超过1分钟,5分钟和15分钟。我们将使用一分钟的平均负载:node_load1。
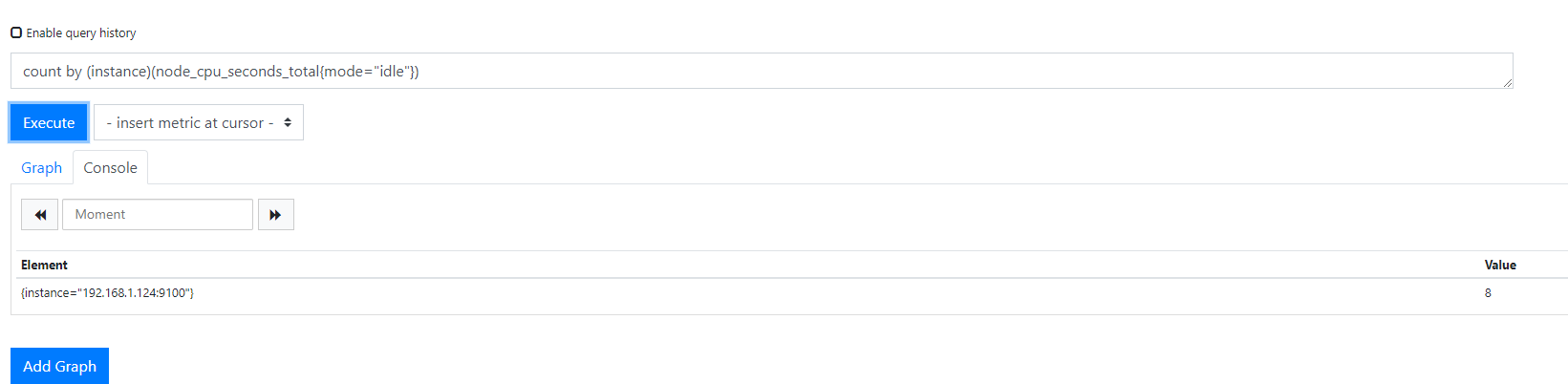
我们还需要计算主机上的cpu数量。我们可以这样使用count聚合:count by (instance)(node_cpu_seconds_total{mode="idle"})
内存使用
以node_memory为前缀的指标列表中找到它们。
我们将关注node_memory度量的一个子集,以提供我们的利用率度量:
• node_memory_MemTotal_bytes - 主机上的总内存
• node_memory_MemFree_bytes - 主机上的空闲内存
• node_memory_Buffers_bytes_bytes - 缓冲区缓存中的内存
• node_memory_Cached_bytes_bytes - 页面缓存中的内存。
所有这些指标都以字节表示。
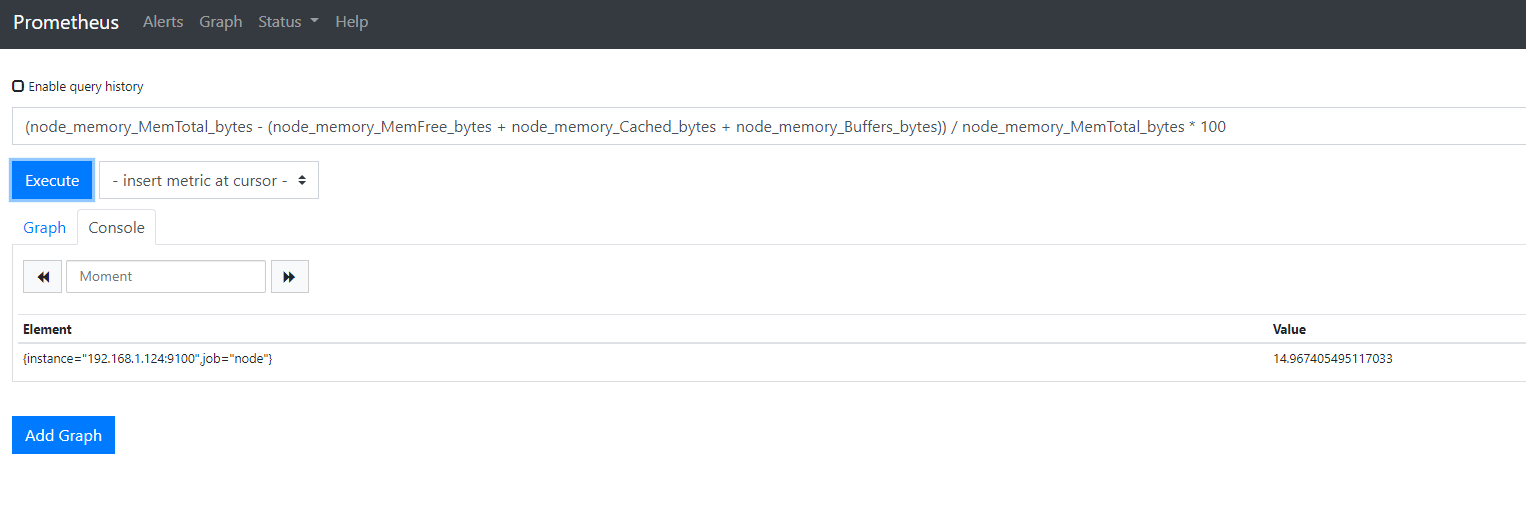
(node_memory_MemTotal_bytes - (node_memory_MemFree_bytes + node_memory_Cached_bytes + node_memory_Buffers_bytes)) / node_memory_MemTotal_bytes * 100
磁盘使用率
对于磁盘,我们只测量磁盘使用情况而不是使用率、饱和度或错误。这是因为在大多数情况下,它是对可视化和警报最有用的数据。Node Exporter的磁盘使用指标位于以node_filesystem为前缀的指标列表
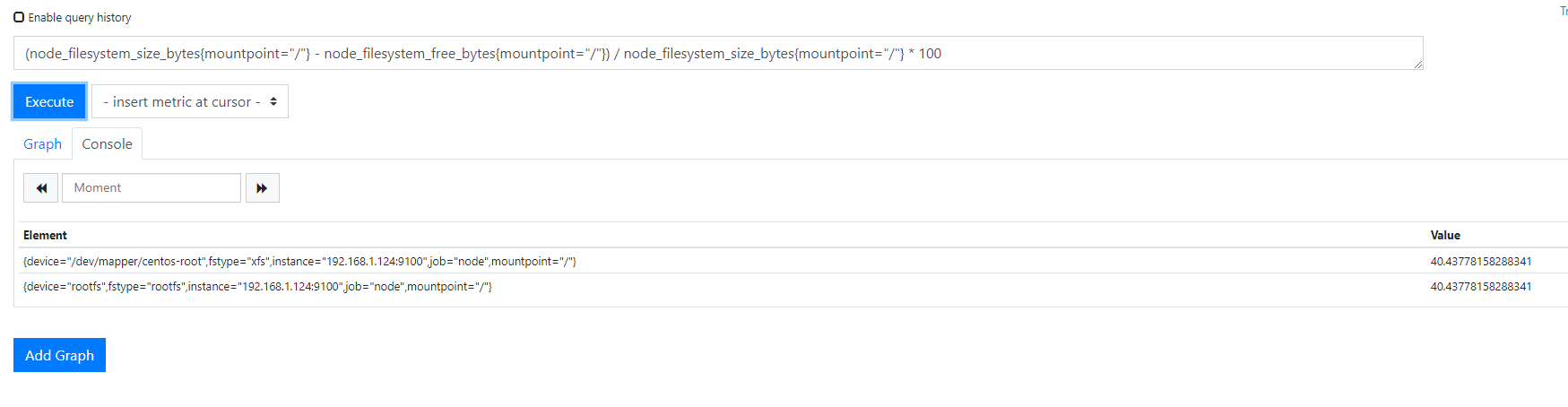
例如,node_filesystem_size_bytes指标显示了被监控的每个文件系统挂载的大小。我们可以使用与内存指标类似的查询来生成在主机上使用的磁盘空间的百分比。但是,与内存指标不同,我们在每个主机上的每个挂载点都有文件系统指标。所以我们添加了mountpoint标签,特别是根文件系统“/”挂载。这将在每台主机上返回该文件系统的磁盘使用指标。
(node_filesystem_size_bytes{mountpoint="/"} - node_filesystem_free_bytes{mountpoint="/"}) / node_filesystem_size_bytes{mountpoint="/"} * 100
如果我们想要或者需要,我们现在可以为配置的特定挂载点添加额外的查询。要监视一个称为/data的挂载点,我们
将使用:
(node_filesystem_size_bytes{mountpoint="/data"} - node_filesystem_free_bytes{mountpoint="/data"}) / node_filesystem_size_bytes{mountpoint="/data"} * 100
或者我们可以使用正则表达式来匹配多个挂载点。
(node_filesystem_size_bytes{mountpoint=~"/|/run"} - node_filesystem_free_bytes{mountpoint=~"/|/run"}) /node_filesystem_size_bytes{mountpoint=~"/|/run"} * 100
可以看到,我们已经更新了挂载点标签,将操作符从=改为=~,这告诉Prometheus右手边的值将是一个正则表达式。然后我们匹配了/run和/ 文件系统。
注意:
(1)不能使用匹配空字符串的正则表达式。
(2)对于不匹配的正则表达式,还有一个!~运算符。
预计多长时间磁盘爆满
predict_linear(node_filesystem_free_bytes{mountpoint="/"}[1h], 4*3600) < 0
predict_linear(node_filesystem_free_bytes{job="node"}[1h], 4*3600) < 0
监控服务状态
systemd收集器的数据,我们这里只收集了Docker SSH 和 Rsyslog
node_systemd_unit_state{name=“docker.service”} // 只查询 docker服务
node_systemd_unit_state{name=“docker.service”,state=“active”} // 返回活动状态
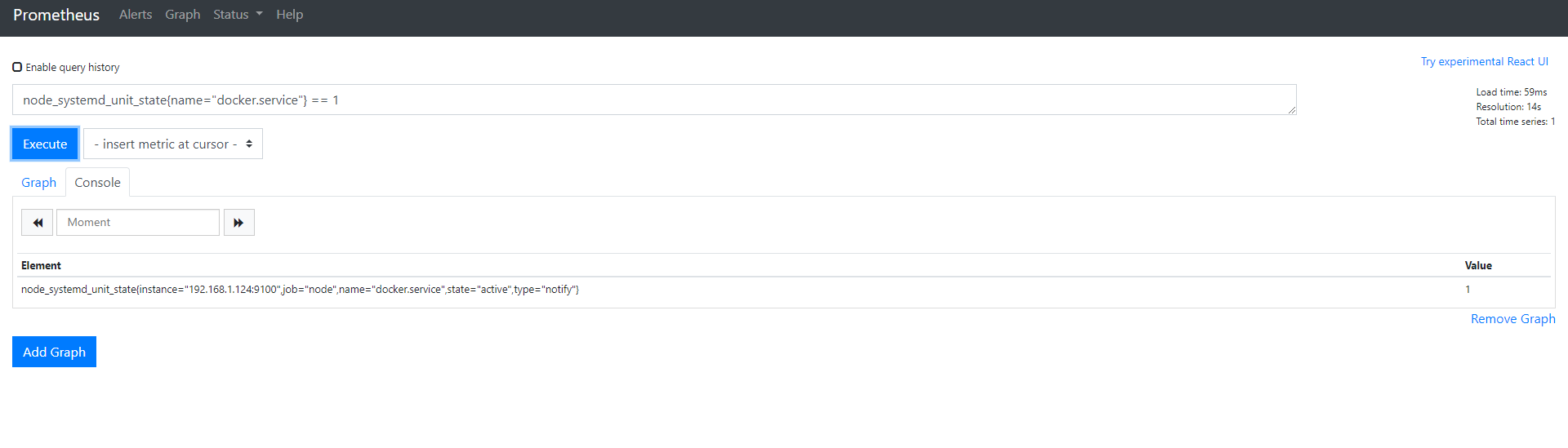
node_systemd_unit_state{name=“docker.service”} == 1 // 返回当前服务的状态
注:比较二进制运算符:==。这将检索所有值为1、名称标签为docker.service的指标。
持久查询
到目前为止,我们只是在表达式浏览器中运行查询。虽然查看该查询的输出很有趣,但结果被卡在普罗米修斯服务器上,是暂时的。有三种方法可以使我们的持久查询(不用每次都要输入查询规则):
• 记录规则 — 从查询中创建新的指标。
• 警报规则 - 从查询生成警报。
• 可视化 —使用像Grafana这样的仪表盘来可视化查询。
(1)记录规则
记录规则是一种计算新时间序列的方法,特别是从输入的时间序列中聚合的时间序列。我们可以这样做:
• 跨多个时间序列生成聚合。
• 预计算昂贵的查询,即消耗大量时间或计算能力的查询。
• 生成一个时间序列,我们可以用它来生成警报。
(2)配置记录规则
记录规则存储在Prometheus服务器上,存储在Prometheus服务器加载的文件中。规则是自动计算的,频率由prometheus.yml 全局块中的evaluation_interval参数控制。
[root@localhost docker]# cat /wgr/prometheus/rules/node_rules.yml
groups:
- name: node_rules
rules:
- record: instance:node_cpu:avg_rate1m
expr: 100 - avg(irate(node_cpu_seconds_total{mode="idle"}[1m])) by (instance) * 100
labels:
metric_type: aggregation
[root@localhost docker]#
注意:我这里用的是docker的,一开始创建容器的时候是挂载的yml文件,导致容器里面node_rules.yml,找了一会原因。
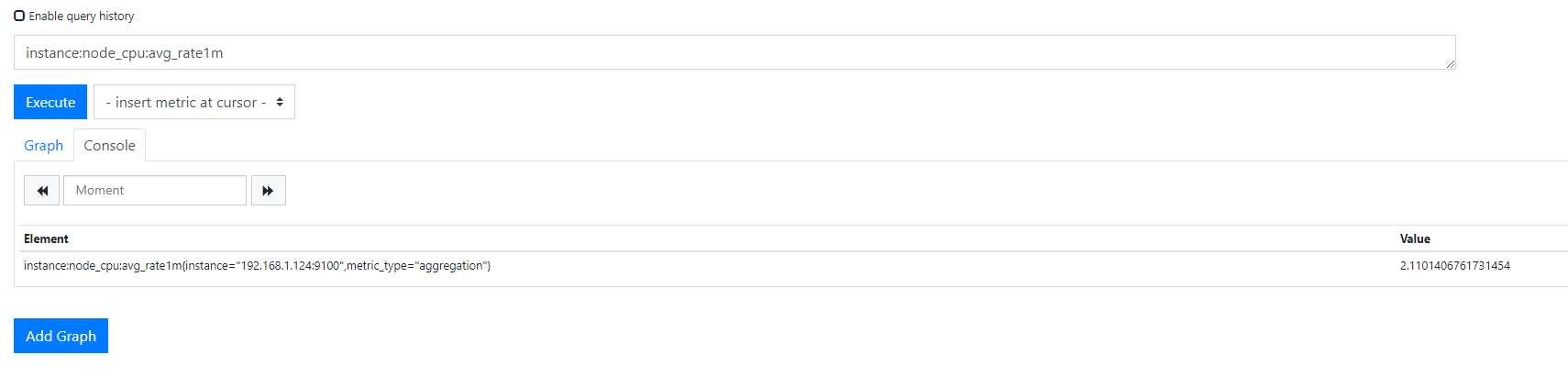
可视化
需要注意的是,普罗米修斯一般不用于长期数据保留——默认值是15天的时间序列。这意味着,普罗米修斯关注的是更直接的监控问题,而不是可视化和仪表板更重要的其他系统。使用表达式浏览器、绘制Prometheus用户界面内部的图形以及构建相应的警报,这些方法往往比构建广泛的仪表盘更能体现普罗米修斯时间序列数据的实用性。Grafana支持在Linux、Microsoft Windows和Mac OS x上运行。
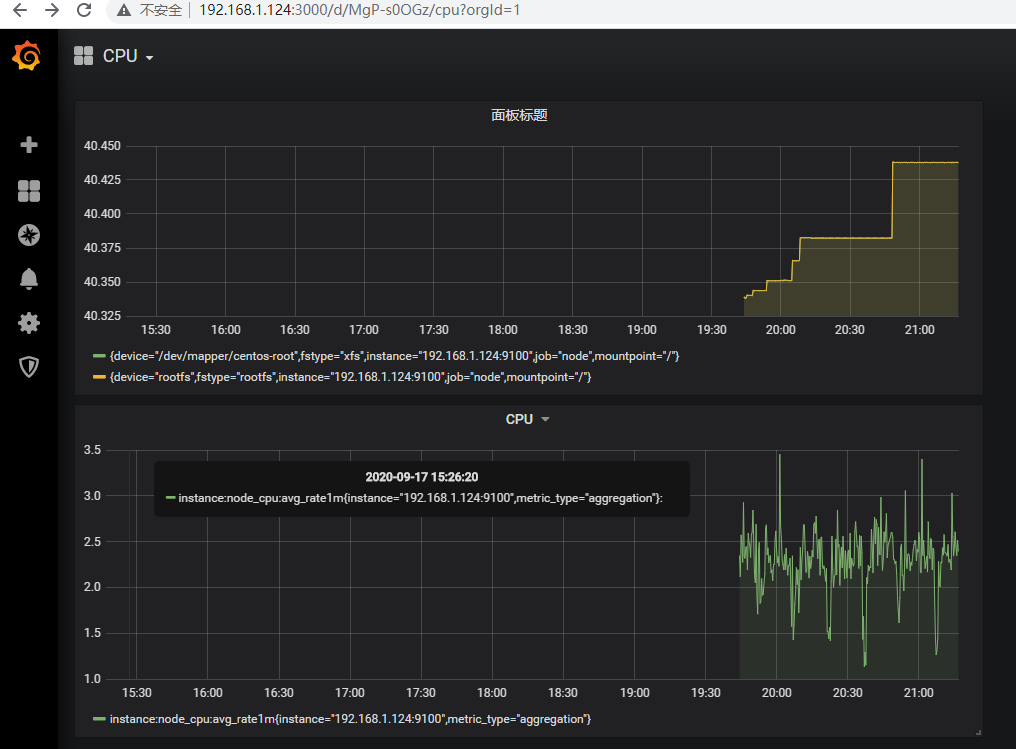
确实可以直接导入模板的,更好看点。