最近接了个活,有大批的图片需要文字识别
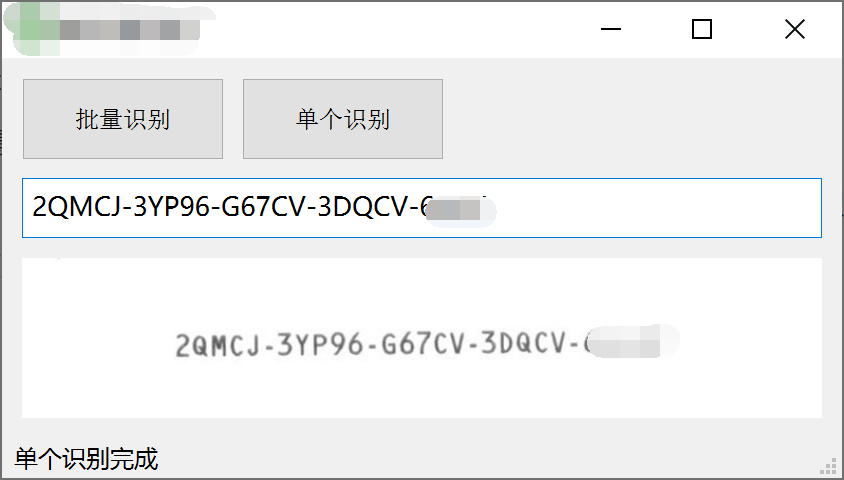
图片参考

是印刷字体打印后再扫描的图片,看到这种任务,首先想到的是用tesseract进行识别,印刷字体识别率很高
拿出工具进行识别分析,效果感人,5段文字,有3段都有识别错的,2和Z,3和S
进过多个图片测试,基本不可用,识别错的太多了

对接百度通用识别,使用高精度版,准确率基本100%,不过百度账户有数量限制,客户有几千上万的图像需要识别,这个方式行不通,毕竟能免费为啥要付钱呢
免费测试网址:https://cloud.baidu.com/product/ocr/general
通过资料查阅,发现可以对某一类图片进行训练,即可大幅提升识别准确率
训练过程参考:
https://www.cnblogs.com/cnlian/p/5765871.html
虽然这个教程是3.0的,但是5.0一样训练,不影响流程
通过选取40个图片为训练样本,合并成一个tif,生成box文件,然后使用jTessBoxEditor修正错误,然后训练出模型文件
使用新的模型文件进行识别,果然识别率大幅上升,测试准确度有99.9%,大批量测试速度也很快,1秒100张的速度
==================================================================================
==================================================================================
这边分享一些中间遇到的坑和经验:
1.32位模型和64位模型不通用,而且32位训练我这边出问题直接训练不成功
2.提示无法读取box:APPLY_BOXES: boxfile line 3/G ((80,0),(80,0)): FAILURE! Couldn't find a matching blob
这种错误大概率是训练图片太脏引起的,
如下左边这种图片就不行,需要使用opencv进行二值化处理,白底黑字,参照右图


3.如果百度识别效果还可以,建议使用百度识别修改文件名,这样大幅减少人工识别纠正的工作量
4.建议使用opencv进行处理,寻找轮廓,自己生成box文件,读取文件名来匹配每个轮廓的文字内容,这样可以极大的减少工作量
(jTessBoxEditor太难用了, 坐标得手动改,文字也要一个个改,不能放大,你要是改个100个,估计得崩溃)

box文件,格式为【文字内容,p1, p2, p3, p4, 图片序号】

#opencv的rect转换为box文件格式坐标
def get_tesseract_box(x, y, w, h, height):
p1 = x
p4 = height - y
p2 = p4 - h
p3 = x + w
return [p1, p2, p3, p4]
height为图像高度
5.如果需要训练的样本比较多,建议首先使用小批量的图片训练出一个模型,然后使用这个模型来识别,作为原始图片名,可以大幅减少工作量