最近我们在客户端的驱动程序中引入了一些变更,这些变更会影响传入的请求在Apache Cassandra集群内的分发方式。
新的默认负载均衡算法即将随驱动程序推出,这些算法将有助于缩短长尾延迟,并提供更好的总体响应时间。
01 Cassandra中数据分区和数据复制的方式
Cassandra根据分区键(partition key)的值将数据分配至节点。每个分区键对应的分区有多个副本,从而确保可靠性和容错能力。
复制策略决定了要把这些副本放置在哪些节点。整个集群中的副本总数被称为“复制因子(replication factor)”。例如,“复制因子为3”就表示在一个给定的数据中心或集群中,每条数据有三个副本。
对于一个给定的查询请求,驱动程序会选择一个副本节点作为本次查询的协调节点(coordinator),并负责满足一致性级别(consistency level)的要求。
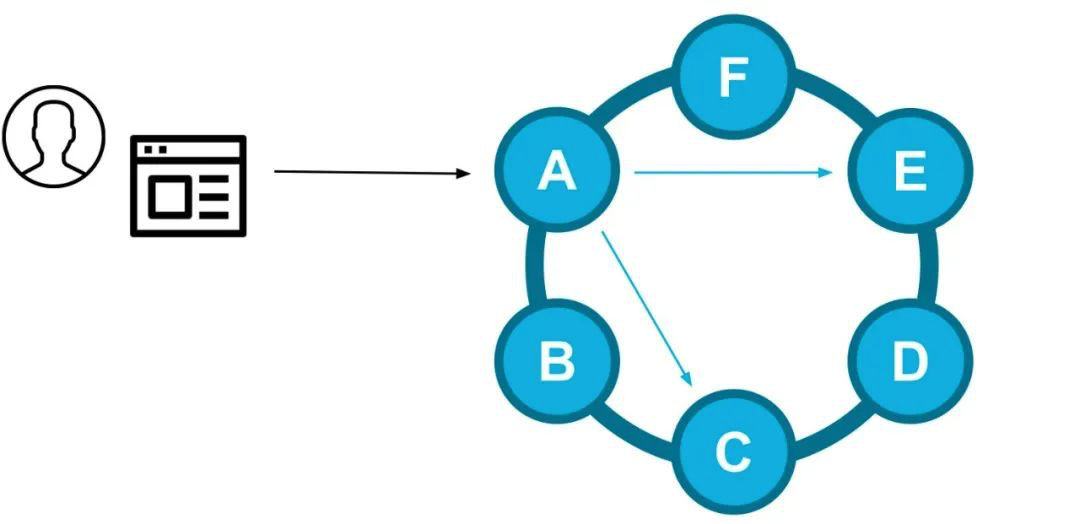
写入路径示例:客户端驱动程序选择了节点A,该节点A是某个给定的分区键的副本节点,它会作为本次请求的协调节点将数据发送到其他副本节点(E和C)
02 客户端是如何路由的
DataStax Drivers(DataStax的驱动程序)控制传入的查询请求将如何在集群中分发。借助集群的元数据,DataStax Drivers可以知道哪些节点是某个给定分区键的副本节点。然后驱动程序会将查询请求直接发送到其中的一个副本节点,以避免额外的网络跃点(network hop)。
当复制因子大于1时,驱动程序会把收到的请求在不同的副本间保持平衡。以往,驱动程序常常以随机的方式,从副本节点集(replica set)中为某个查询选择协调节点。
03 随机选择
鉴于微服务应用程序通常包含多个服务实例,我们必须将客户端的驱动程序视为一种分布式的负载均衡器(n个客户端将流量路由到m个节点)。随机选择是一种很好的分布式负载均衡器的算法,因为它是无状态的,不需要客户端实例互相通信之后生成统一的负载。
多个客户端将多个请求分发到同一些节点
随机选择让请求负载被均匀地分配(从数量的角度),但这些负载的分配却不是公平的——因为随机选择没有考虑请求的大小或复杂性,也没考虑在服务器节点的后台可能正在处理的其他任务。
03 随机选择的二次方(The Power of Two Random Choices)
在分布式系统中,根据某个标识信号就确定性地选择某一个候选节点,这可能是很危险的——因为具有相同逻辑的多个客户端,可能会将同一服务器节点标识为最佳候选节点,并将所有流量导向到该节点。这会导致负载峰值,并有级联失效(cascading failure)的风险。因此,具有一定程度的随机性的算法仍然是我们所需要的。
通过泰勒·麦克穆伦(Tyler McMullen)的演讲,我们首此接触到“随机选择的二次方(The Power of Two Random Choice)”这个算法。在那之后,这个算法已经被诸多负载均衡软件(诸如Netflix的Zuul,Nginx和Haproxy之类的)实现,用于众多的服务网格部署(service mesh deployment)中(比如Twitter)。
这个算法的逻辑很简单:相比试着根据某个标识信号来选出那个绝对最佳的候选节点,“随机选择的二次方”这个算法会让你随机选择两个候选节点,然后再在这两者中选择更好的那个,同时也避免了更糟的选择。
我们有几种不同的方法来识别哪个节点是最佳候选节点。过去,我们公开了一种使用时延信息(LatencyAwarePolicy)作为标识信号的方法。由于我们在路由数据库请求时没有考虑查询的复杂性,因此聚合的节点时延信息并不是服务器实例的当前健康状态的最佳指标。
例如,某个查询可能由于需要整理合并大量数据而需要更长的时间,但是该服务器可能仍有大量的空闲资源来处理其他查询。另外,请求的响应时间是在收到响应之后才确定的,可是这已经不能反映服务器的最新状态了。
客户端驱动实例会向节点发送请求,我们决定用正在处理中的请求数来选择最佳候选节点。简而言之,我们会随机选择两个副本,然后选择其中等待处理的请求较少的副本节点作为协调节点。
04 监测陈旧队列
借助我们对节点的行为模式的了解,我们发现了更多的改进空间。当节点正在进行压实或垃圾回收(GC)时,它可能需要更长的时间来处理请求队列中的项目。如果仅仅基于最短队列的算法,在负载增加的情况下,即使节点的请求队列过时,客户端驱动程序也可能会继续向其路由流量。
例如,请考虑以下情形。
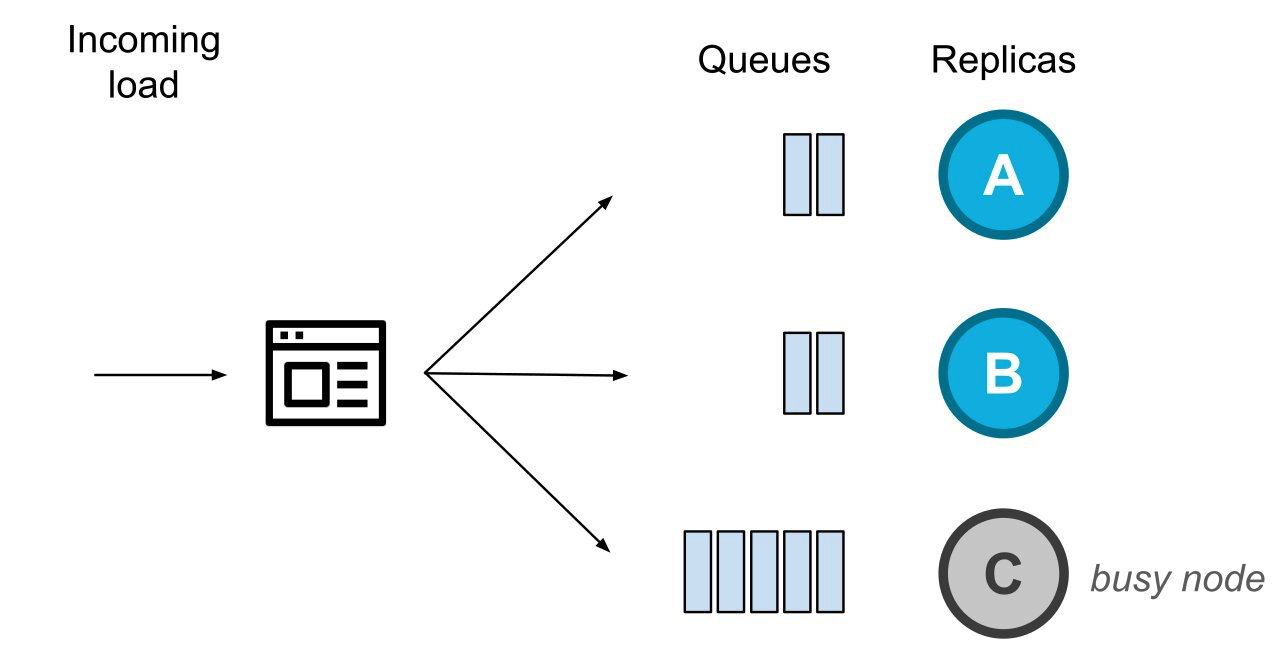
系统中有等待处理的请求,用队列来表示
请求源源不断而来,应用程序中的客户端驱动程序实例在不断地平衡发送至三个副本节点请求。在某个时间点,节点C变得很忙(即一段时间不能处理请求)。其他正常的副本节点将继续处理请求,如图所示。
与此同时,系统传入的负载正在增加,此时健康的副本节点们就会收到更多的待处理请求。
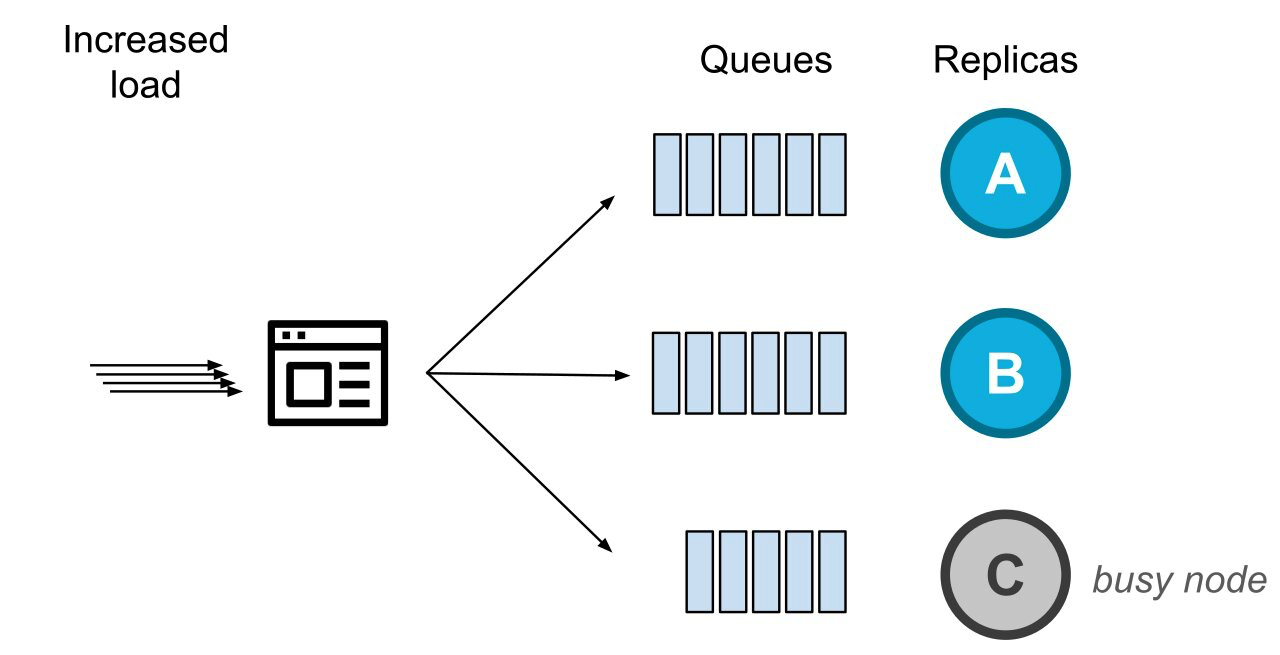
由于负载增加,健康的节点收到的待处理请求的数量增加了
在这种情况下,我们以前会将请求路由到那个无法以正常速度处理请求的节点(即上图中的节点C)。
为了克服上述情况,我们引入了第二个指标:节点是否有待处理的请求(10+),并且在最近的几百毫秒内还没发回任何响应。这个指标并不作为”随机选择的二次方“的标识信号,而是作为对副本节点的健康状况进行的初步探测。
如果大多数副本节点是健康的,那么不健康的副本节点将不会作为初始的协调节点(它们仍会被纳入重试和投机性执行speculative execution的考虑范围)。
为什么把探测副本节点的健康状况作为第一步?因为如果有大量节点是不健康的,则可能意味着该指标不适用于当前的工作负载、查询类别或预计的延迟时间。这样,我们确保不会根据一个在特定情况下并不适用的标识信号做出错误的决定, 从而避免了让情况变得更糟 。
05 总结
我们针对具有多个客户端的一系列场景同时测试了这个新算法,通过CPU burns(stress-ng)和人工网络延迟(tc)模拟了处于压力下的节点,结果是该新算法的性能优于所有其他方法。
作为示例,下图按百分位分布展现了延迟数据,在一些节点被CPU burns的情况下,对新算法和随机选择算法进行了比较。
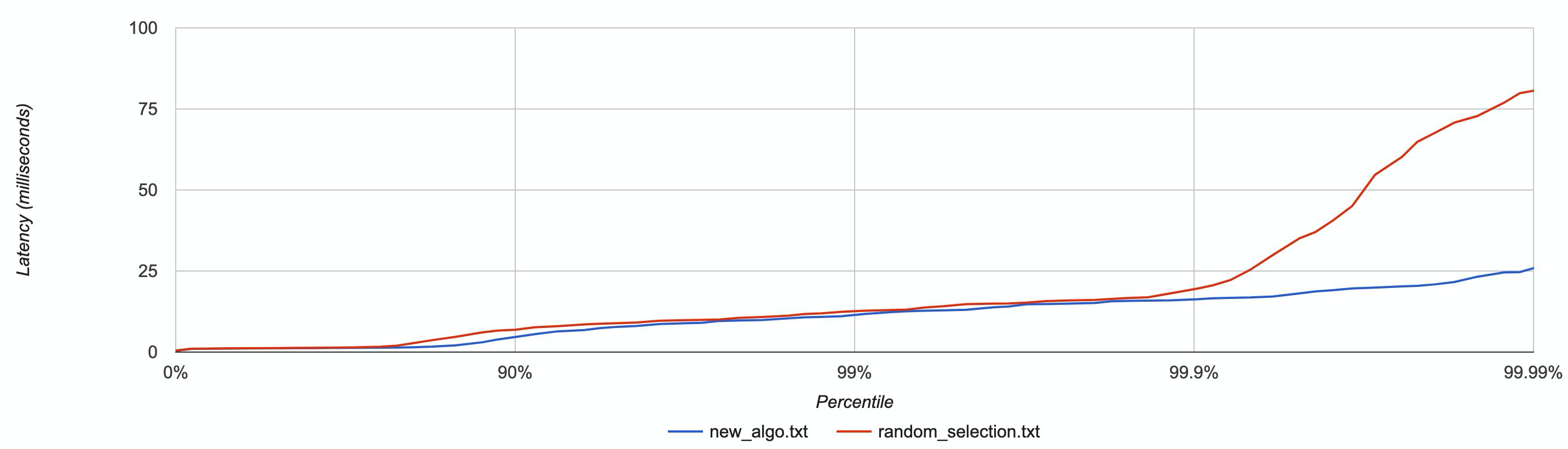 具有较低尾部延迟的新算法(蓝色)
具有较低尾部延迟的新算法(蓝色)
新的负载平衡算法基于“随机选择的二次方”,再加上能够躲开忙碌节点的逻辑判断,即将成为DataStax Drivers新的默认设置。借助简单的逻辑判断,这个新的算法绕开了最差的候选节点,同时保证了流量分配有一定程度的随机性。因而它能够避免大家不希望看到的羊群效应,大大降低了尾部延迟时间。
我们将在所有的客户端驱动程序中采用这种新算法。Java和Node.js驱动程序从4.4版开始已经默认使用此算法,其余驱动程序也将很快跟上。