导读:版本1.6,2.0
之前的数据批量处理,流式处理基本低spark的天下,现在有flink,blink(据说是阿里的flink内部版本)也开始开源了。
正在学习中,我更加偏向flink(spark是以批处理为数据的处理方式,sparkStreaming属于微批处理;flink是以纯流式的数据处理方式)
第一节:执行过程的原理层面
1:名词
2:执行过程
3:源码解析
第二节:集群及配置层面
1:集群配置
2:Spark shell
3:HA
4:属性配置
5:UI访问
第一节:执行过程的原理层面
1、名词:
Master :管理节点(standalone模式)
Worker :执行节点(standalone模式)
Client :客户端
Application :提交的应用
Job :应用中找出来的job,多少个action就有多少个job
Driver :请求资源,生成DAG,Task,分配任务
DAG :有向无环图
DAGScheduler :dag调度器
Stage :按照宽窄依赖划分的执行阶段,是dag执行流程的一个依据,由RDD组成
RDD :resilience distribute databases弹性分布式数据集,一组partition组成,partition是分布在不同的节点上的,默认partition个数 与block相同,可以设置。
Partition 与数据的块对应,可以设置(在代码程序中设置),里面存储的是代码逻辑,并非数据
taskScheduler :任务调度器,里面是DAGScheduler传过来的taskset
Task :执行的任务,在一个stage中的很多partition的一串,就是要执行的一个任务,
而一个stage中有多少任务就要看这个finalRDD有多少的partition
Executor :任务执行器
Threadpool :执行器中的线程池,负责task具体执行
BlockManager :虚拟的概念,用来数据的存储什么的,如果application执行完之后就消失
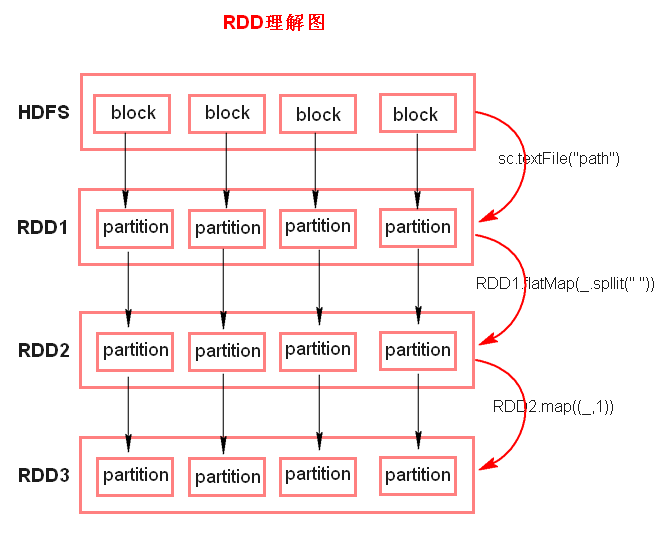
RDD实际上不存储数据,这里方便理解,暂时理解为存储数据

2、执行过程:
1、资源分配:
1.1 Standalone(本机模式):
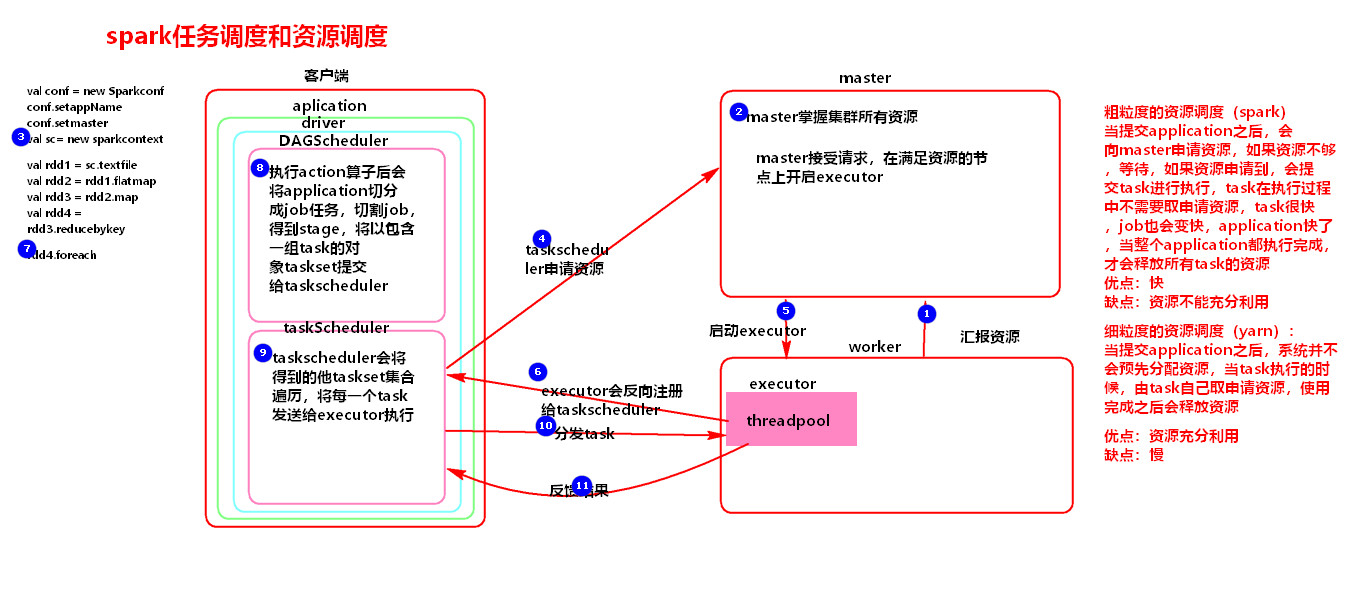
1.1.1 粗粒度的资源调度(资源是一次性申请):
向master一次性申请task要执行的资源,task执行过程不会再申请,并且全部执行完之后再释放资源;
优点:快(因为资源一次性申请了)
缺点:资源不能充分利用
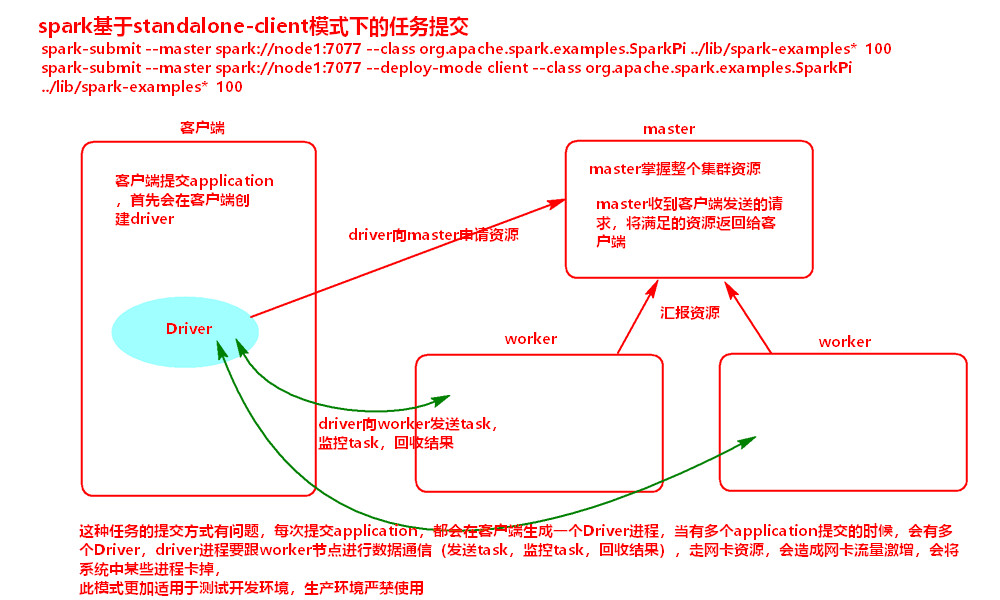
1.1.2 Client提交(如果多个application时候,会产生多个driver在client上,同时还有过多的client与集群节点的交互):
1:worker-----提交资源---->master
2:master掌握资源
3:client创建driver----提交application----->master
4:master在worker节点创建executor
5:executor反向注册给driver
6:driver生成task-------发送task------>executor,且监控并回收task的执行结果
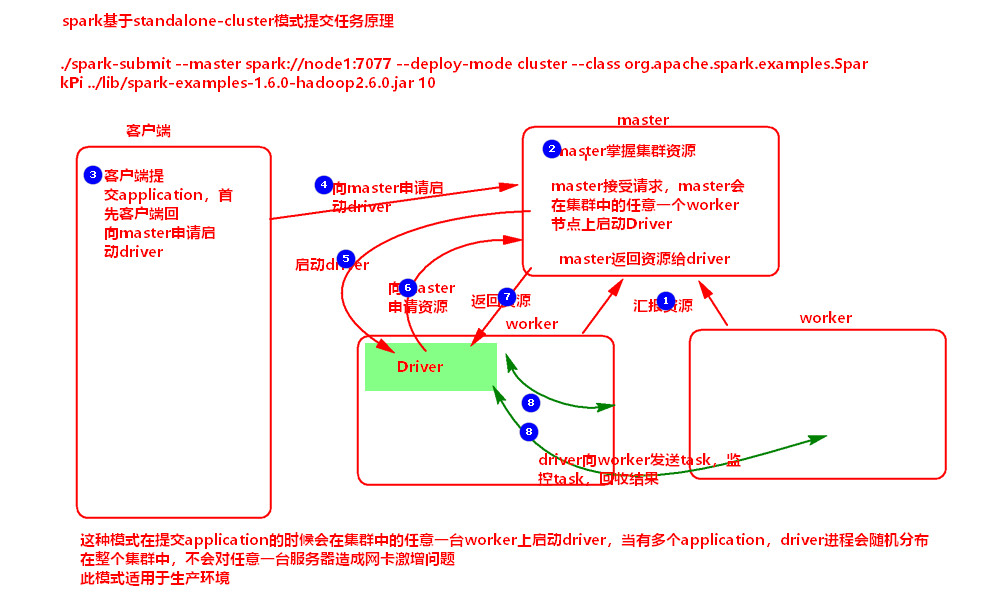
1.1.3 Cluster提交(如果多个application时候,产生多个driver是随机分布在worker上的,尽量避免了服务器的网卡激增):
1:worker-----提交资源---->master
2:master掌握资源
3:client----提交application----->master
4:master随机找一台worker-----启动driver----->worker
5:driver-----申请资源------>master
6:master-----启动executoer------>worker
7:worker反向注册给driver
8:driver生成task-------发送task------>executor,且监控并回收task的执行结果
1.2 Yarn(基于yarn的):
1.2.1 细粒度的资源调度(资源不是一次性申请):
Task自己去申请资源,并且执行完之后会释放资源;
优点:资源充分利用
缺点:慢(因为每次都要申请资源)
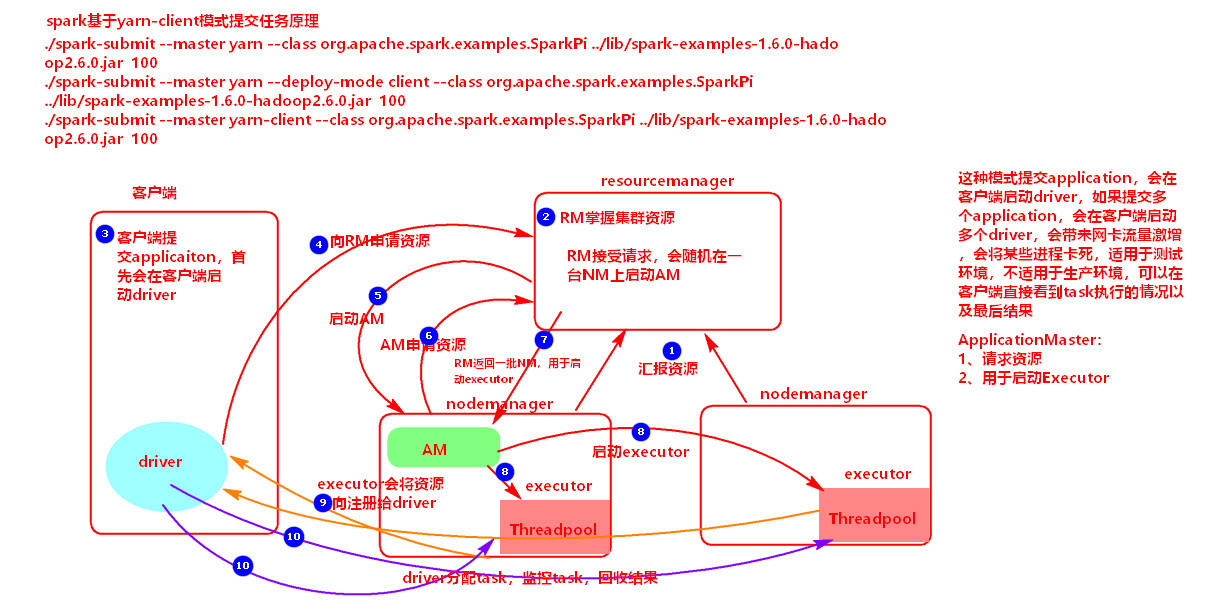
1.2.2 Client提交:
1:nodeManager-----提交资源----->resourceManager
2:resourceManager掌握资源
3:client创建driver-------提交application----->resourceManager
4:resourceManager-------启动applicationMaster------->nodeManager
5:applicationMaster-------申请资源-------->resourceManager
6:resourceManager-------返回一些nodeManager用于创建executer------>applicationMaster
7:applicationMaster------创建executor------>nodeManager
8:executor-----反向注册----->driver
9:driver生成task-------发送task------>executor,且监控并回收task的执行结果
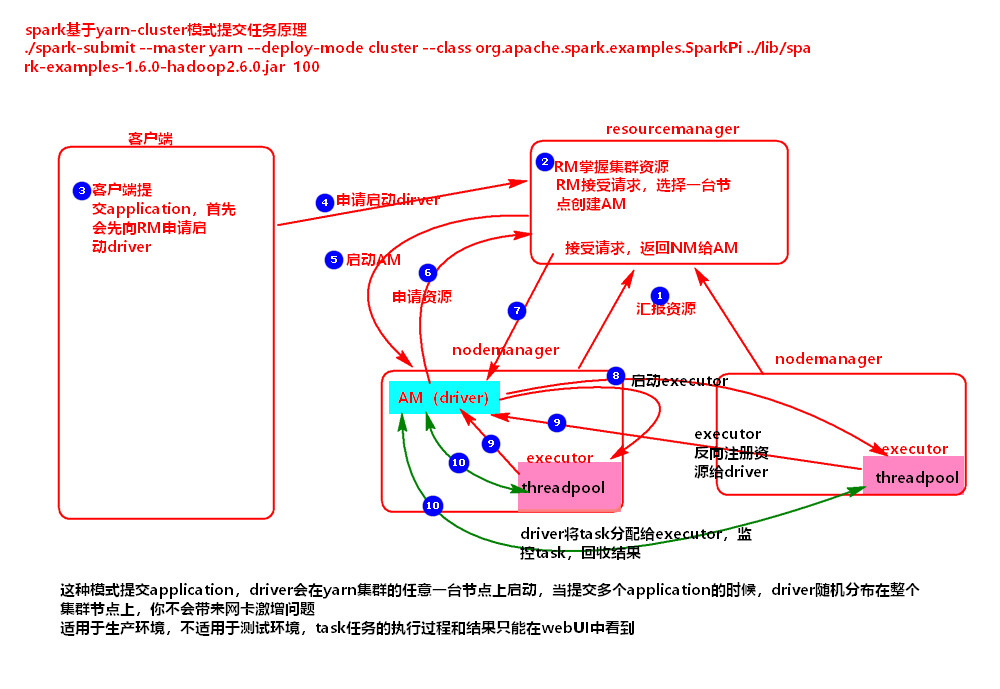
1.2.3 Cluster提交:
1:nodeManager-----提交资源----->resourceManager
2:resourceManager掌握资源
3:client------提交application----->resourceManager
4:resourceManager-------启动applicationMaster(同时启动driver)------->nodeManager
5:applicationMaster-------申请资源-------->resourceManager
6:resourceManager-------返回一些nodeManager用于创建executer------>applicationMaster
7:applicationMaster------创建executor------>nodeManager
8:executor-----反向注册----->driver
9:driver生成task-------发送task------>executor,且监控并回收task的执行结果
2、任务执行过程:
1:action算子触发
2:在DAGScheduler中:
2.1:application----通过action算子个数---->job个数
2.2:job-----宽窄依赖----->stage
2.3:DAGScheduler-----taskSet----->taskScheduler
3:在taskScheduler中:
3.1:taskScheduler遍历taskSet-------task-------->executor(在Threadpool中执行)
3、源码解析:
3.1、资源调度源码:
1:(submit)
Main--->sunbmit(反射client)--->runMain--->invoke(调用client)
2:(client)
Main(akka通信)--->onStart(mainClass=workerDriverWrapper)--->RequestSubmitDriver
3:(master)
RequestSubmitDriver(创建driver对象)
--->schedule(最主要的方法)
--->创建driver对象--->launchDriver--->start(启动driver)
--->startExecutorOnWorkers
--->schedulerExecutorsOnWorkers(设置executor,cores)
{
--executor-memory设置每个executor所需的内存的大小,默认1G
--total-executor-cores设置整个集群可以提供的cores数量,默认全部可用的cores
--executor-cores{
不设置:默认1个,在worker上启动一个executor,会占用掉所有可用的cores(贪婪模式)
设置(假如设置2):一个executor上占用2个cores,如果还有多余的cores内存,则会在 一个worker上生成多个executor,且每个executor占用2个cores
}
}
--->allocateWorkerResourceToExecutor(分配worker上的executor资源)--->launchExecutor(启动executor)
合理分配executor在worker上的保障:
1:oneExecutorPerWorker(不设置executor-cores就是ture,这样就会executor=1保证executor一直是一个,循环分配所 有worker之后再循环回来,
executor还是1,但是所用的cores就会+1,直到用掉所有可用cores;
设置了就会executor+=1,这样同样循环回来,会生成新的executor,增加的cores也是分配到新的executor上)
2:spreadOutApps(这个值是true,进来会改变keepScheduling=false,这样就不会再同一个节点上一直分配,而是循环的 平均分配了)
3.2、任务执行源码:
执行算子--->DAGSecheduler
--->划分宽窄依赖
--->taskScheduler.submitTasks(taskSet)--->执行task
第二节:集群及配置层面
1,集群配置:(standalone,yarn,local,mesos)
1.1 Standalone:自带的资源调度框架,可以分布式
1.1.1:conf目录下,更名slaves.template,添加从节点
1.1.2:修改spark-env.sh:
export SPARK_MASTER_IP:master的ip
export SPARK_MASTER_PORT:提交任务的端口,默认是7077
export SPARK_WORKER_CORES:每个worker从节点能够支配的core的个数
export SPARK_WORKER_MEMORY:每个worker从节点能够支配的内存数
1.1.3:节点同步信息
1.1.4:启动:进入到sbin目录下./start-all.sh(这个不设置环境变量,与hadoop冲突了)
1.1.5:客户端提交:bin目录下
./spark-submit
--master spark://node1:7077 (主节点)
--deploy-mode client (客户端模式,默认)
--deploy-mode cluster (集群模式)
--class org.apache.spark.examples.SparkPi (方法全路径名)
../lib/spark-examples-1.6.0-hadoop2.6.0.jar (所在jar包)
10000(参数)
注意:
1:8080是Spark WEBUI界面的端口
(端口修改方式:
start-master.sh中SPARK_MASTER_WEBUI_PORT可以设置端口;
spark-env.sh中export SPARK_MASTER_WEBUI_PORT=9999;
命令行中export SPARK_MASTER_WEBUI_PORT=9999,临时改变)
2:7077是Spark任务提交的端口
(SPARK_MASTER_PORT)
1.2 Yarn:spark有实现了applicationMaster接口,所以可以使用yarn调度框架
1.2.1:配置同上
1.2.2:spark-env.sh:
export HADOOP-CONF-DIR=$HADOOP_HOME/etc/hadoop (yarn的配置位置)
1.2.3:客户端提交:bin目录下
./spark-submit
--master yarn-client (yarn的客户端模式)
--master yarn-cluster (yarn的集群模式)
--class org.apache.spark.examples.SparkPi (方法全路径名)
../lib/spark-examples-1.6.0-hadoop2.6.0.jar (所在jar包)
10000(参数)
1.3 提交参数:(启动执行可以配置一些参数)
1.3.1 Options:
--master
MASTER_URL, 可以是spark://host:port, mesos://host:port, yarn, yarn-cluster,yarn-client, local
--deploy-mode
DEPLOY_MODE, Driver程序运行的地方,client或者cluster,默认是client。
--class
CLASS_NAME, 主类名称,含包名
--jars
逗号分隔的本地JARS, Driver和executor依赖的第三方jar包
--files
用逗号隔开的文件列表,会放置在每个executor工作目录中
--conf
spark的配置属性
--driver-memory
Driver程序使用内存大小(例如:1000M,5G),默认1024M
--executor-memory
每个executor内存大小(如:1000M,2G),默认1G
1.3.2 Spark standalone with cluster deploy mode only:
--driver-cores
Driver程序的使用core个数(默认为1),仅限于Spark standalone模式
1.3.3 Spark standalone or Mesos with cluster deploy mode only:
--supervise
失败后是否重启Driver,仅限于Spark alone或者Mesos模式
1.3.4 Spark standalone and Mesos only:
--total-executor-cores
executor使用的总核数,仅限于SparkStandalone、Spark on Mesos模式
1.3.5 Spark standalone and YARN only:
--executor-cores
每个executor使用的core数,Spark on Yarn默认为1,standalone默认为worker上所有可用的core。
1.3.6 YARN-only:
--driver-cores
driver使用的core,仅在cluster模式下,默认为1。
--queue
QUEUE_NAME 指定资源队列的名称,默认:default
--num-executors
一共启动的executor数量,默认是2个。
2,Spark shell:
启动: ./spark-shell --master spark://node1:7077
例子:
启动hdfs集群: start-all.sh
创建目录: hdfs dfs -mkdir -p /spark/test
上传wc.txt: hdfs dfs -put /root/test/wc.txt /spark/test/
运行wordcount:
sc.textFile("hdfs://node1:9000/spark/test/wc.txt")
.flatMap(_.split(" ")).map((_,1)).reduceByKey(_+_).foreach(println)
3,HA:(standalone模式下会有单点,需要HA)
(1) 两种方式:
fileSystem(文件系统):
fileSystem只有存储功能,可以存储Master的元数据信息,用fileSystem搭建的Master高可用,在Master失败时,需要我 们手动启动另外的备用Master,这种方式不推荐使用。
zookeeper(分布式协调服务):
zookeeper有选举和存储功能,可以存储Master的元素据信息,使用zookeeper搭建的Master高可用,当Master挂掉时,备用的Master会自动切换,推荐使用这种方式搭建Master的HA。
(2) 搭建:
1:在Spark Master节点上配置主Master,配置spark-env.sh
export SPARK_DAEMON_JAVA_OPTS="
-Dspark.deploy.recoveryMode=ZOOKEEPER
-Dspark.deploy.zookeeper.url=node3:2181,node4:2181,node5:2181
-Dspark.deploy.zookeeper.dir=/sparkmaster0821"
2:发送到其他worker节点上
3:找一台节点(非主Master节点)配置备用 Master,修改spark-env.sh配置节点上的MasterIP
export SPARK_MASTER_IP=node02
4:启动集群之前启动zookeeper集群
./zkServer.sh start
5:启动spark集群
4,属性配置:
spark.task.cpus
5,UI访问:
1:可以指定提交Application的名称
./spark-shell --master spark://node1:7077 --name myap
2:配置historyServer
(1) 临时配置,对本次提交的应用程序起作用
./spark-shell --master spark://node1:7077
--name myapp1
--conf spark.eventLog.enabled=true
--conf spark.eventLog.dir=hdfs://node1:9000/spark/test
(2) spark-default.conf配置文件中配置HistoryServer,对所有提交的Application都起作用
在客户端节点,进入../spark-1.6.0/conf/ spark-defaults.conf最后加入:
//开启记录事件日志的功能
spark.eventLog.enabled true
//设置事件日志存储的目录
spark.eventLog.dir hdfs://node1:9000/spark/test
//设置HistoryServer加载事件日志的位置
spark.history.fs.logDirectory hdfs://node1:9000/spark/test
//日志优化选项,压缩日志
spark.eventLog.compress true
启动HistoryServer(举例在node02节点启动):
./start-history-server.sh
访问HistoryServer:node02:18080,之后所有提交的应用程序运行状况都会被记录。