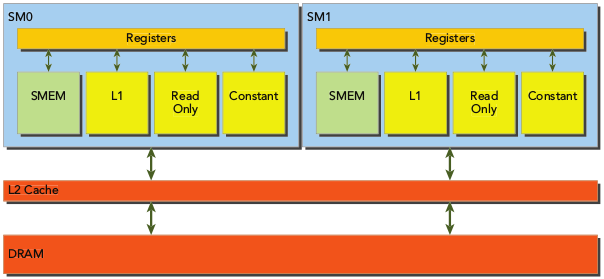
GLobal memory的load/store都要经过L2缓存(在计算能力 < 3的卡还有L1缓存),所以目前的主流卡基本上都已经没有L1缓存了,所以后面就只以L2缓存为例.
对齐寻址和临近寻址:
Global memory在与L2做数据传输的最小单位为32bytes,称为L2 cahce line size. 例如有一段64bytes的global memory,如果warp中的一个线程要访问第4个字节的数据,那么L2缓存会把前32个字节的global memory都缓存过来,这种策略称为space locality (空间局部性:当前使用的数据临近的数据被使用的可能性更高),同理如果访问第33个bytes的内存,那么L2缓存会把后32个bytes的数据都缓存过来,相当于将global memory从起始地址按照32bytes分段,每次都缓存若干段的数据,所以就存在一个global memory efficiency的指标表示global memory的Load和store效率.
以一个warp的32个线程为例:假设有一段global memory,float* data,长度为160(5*32).假设线程id为tid的线程去访问data[tid]位置的数据,那么总计需要访问data的前128字节的内容,按照L2以32字节为单位的缓存方式,正好缓存4段地址,这就属于对齐访问。
现在换一个访问方式:tid的线程去访问data[tid + offset]位置的内存,其中:0 < offset < 8.可以看到无论offset取多少,都将缓存全部5段内存,但是实际只用了4段,因此使用效率为80%,这种就属于没有对齐,所以对齐访问指的就是是否按照32字节访问global memory中的数据.
而临近访问指的就是让一个warp中的线程访问的内存尽量挨着,这样就能降低数据缓存的总量.访问的内存总量如果很高,就算efficiency很高,速度肯定也慢.
验证程序:
#include<stdio.h> #include<time.h> typedef float TYPE; __global__ void readOffset(TYPE* A, TYPE* B, TYPE* C, int n, int offset) { int tid = blockIdx.x * blockDim.x + threadIdx.x; int i = tid + offset; if ( i < n ) C[tid] = A[i] + B[i]; } __global__ void warmup(TYPE* A, TYPE* B, TYPE* C, int n, int offset) { int tid = blockIdx.x * blockDim.x + threadIdx.x; int i = tid + offset; if ( i < n ) C[tid] = A[i] + B[i]; } void InitValue(TYPE* p, int n) { for (int i = 0; i != n - 1; i++) { p[i] = i; } } int main(int argc, char** argv) { int n = 1 << 20; size_t nBytes = n*sizeof(TYPE); int blockSize = 512; int offset = 0; if (argc > 1) offset = atoi(argv[1]); int nBlocks = (n-1)/blockSize + 1; TYPE* a = (TYPE*)malloc(nBytes); TYPE* b = (TYPE*)malloc(nBytes); InitValue(a, n); InitValue(b, n); TYPE* A, *B, *C; cudaMalloc(&A, nBytes); cudaMalloc(&B, nBytes); cudaMalloc(&C, nBytes); cudaMemcpy(A, a, nBytes, cudaMemcpyHostToDevice); cudaMemcpy(B, b, nBytes, cudaMemcpyHostToDevice); //warmup clock_t start, end; start = clock(); warmup<<<nBlocks, blockSize>>>(A, B, C, n, offset); cudaDeviceSynchronize(); end = clock(); double dura = (double)(end - start) / CLOCKS_PER_SEC; printf("warmup : %f ", dura); start = clock(); readOffset<<<nBlocks, blockSize>>>(A, B, C, n, offset); cudaDeviceSynchronize(); end = clock(); dura = (double)(end - start) / CLOCKS_PER_SEC; printf("offset %d: %f ", offset, dura); cudaFree(A); cudaFree(B); cudaFree(C); free(a); free(b); cudaDeviceReset(); return 0; }
编译:
nvcc -O3 aliged.cu -o align
分别取不同的offset运行程序:
./align ./align 4 ./align 128
结果如下:(在垃圾游戏本上可能要多运行几次才能出现这么好的结果,在较好的比较稳定的服务器上几乎每次都能得到类似的结果)
warmup : 0.000350 offset 0: 0.000137
warmup : 0.000350 offset 4: 0.000154
warmup : 0.000346 offset 128: 0.000137
使用nvprof进一步验证:
nvprof ./align
nvprof ./align 4
nvprof ./align 128
结果如下:



可以看到不管是warmup还是readOffset函数,当offset不对齐的时候执行时间都比对其的情况慢.
然后继续使用--metrics选项查看利用率,执行:
nvprof --metrics gld_efficiency,gst_efficiency ./align 4
结果如下:
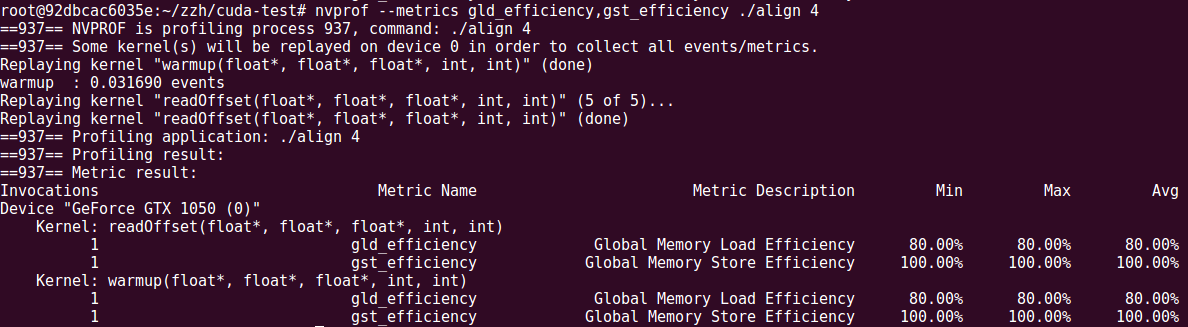
可以看到efficiency为80%,正好符合预期,如果offset换为8的倍数,那么efficiency就都是100%.
另外简单修改代码就能实现gst_efficiency为80%,就是将readOffset中的C[tid]改为C[tid+offset],修改之后重新编译,同样执行上面的命令,结果如下:

AoS VS SoA
什么意思:Array of struct && struct of Array
例如:
case AoS:
struct P { int x; int y; }; P* arr;
cudaMalloc(&arr, 1024*sizeof(P));
case SoA: struct P { int x[1024]; int y[1024]; };
P* arr;
cudaMalloc(&arr, sizeof(P));
假设(x,y)代表点的坐标,假设实现两个kernel函数,分别给两个不同形式的arr赋相同的值,代码参考:http://www.wrox.com/WileyCDA/WroxTitle/Professional-CUDA-C-Programming.productCd-1118739329,descCd-DOWNLOAD.html->chapter04中的simpleMathAos.cu.
理论上两种表示都能实现这个功能,但是对内存的efficiency是天差地别的.
Aos与SoA的存储方式,如下图:

经过上面的例子可以简单分析一下:当以AoS格式请求arr[tid].x时,arr[tid].y也被隐式加载,因此利用率只有50%,而SoA则没有这个问题.
这里注意:gld_efficiency的计算公式为:
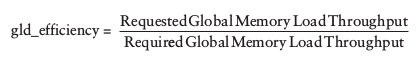
其中Required为一个warp的线程一次请求需要的全部内存,而Requested为每次请求的使用显存大小,所以simpleMathAoS.cu的kernel每次都对x,y分别赋值,每次都只request了4字节的内存,因此最后结果是50%.